
开源自助BI工具,傻瓜式BI分析,支持多种数据源
一:业务背景与需求梳理
公司现在的数据需求主要分为两类:临时需求(业务突然想看看这波活动的效果怎样,数据指标的定义可能随时改,随时加),固化需求(每周要看,每月要看的数据,数据的定义已经非常明确)。对于这两类需求,我们现在的处理方案是
对于临时需求:写HQL到Hive里去查一遍,然后将结果转为excel发送给需求人员。
对于固化需求:编写脚本,结合Hive跑出结果,将结果写入对应DB库,然后通过第三方百度的BI工具进行汇总展现。
这样做简洁明了,但很明显的问题:
开发成本太高:每来一个需求,不管是临时需求还是长期需求,都需要进行定制开发,这种情况下,我们的人力深陷其中。
使用不灵活:一个报表,只能进行展示,没有分析功能,如果要进行分析,需要将数据复制到excel里,利用excel进行处理分析,而我们的数据使用人员不一定具备这种能力。
资源浪费:不同人员开发的报表,很多情况下存在很多重复计算。
其他体验问题:hue的查询速度特别慢,做select from简单的查询,要等一分钟以上(底层引擎tez太慢)
在这种情况下,我们准备构建一个多维分析平台,让业务方自己能够取数,而且最好不用SQL,因为我们的业务方大部分不会SQL(尽管我们已经开展SQL培训,但还是有一定门槛)。这个平台至少满足以下需求
1.SQL查询的速度更块(现在hue太慢,简单查询要2分钟以上),所以底层要支持大数据OLAP引擎
2.更傻瓜的自助分析模型,最好是拖拉拽;(因为很多分析师都没有SQL技能)
3.可视化上有最基本的图表类型(包括数字,地图,时间趋势)
4.开源产品,免费;商业化的产品数据都在别人的服务器上;
5.报表/看板的筛选功能支持时段筛选,最好能联动筛选;
6.权限满足最低门槛(修改,删除表可控制),同时能做到数据行级控制(很多业务部分看数据)
二:产品分析
我们直接入手了开源工具,筛选出了下面几个产品做为重点调研对象:
Superset、Metabase、Davinci
A)Metabase (gihub star 15,670)
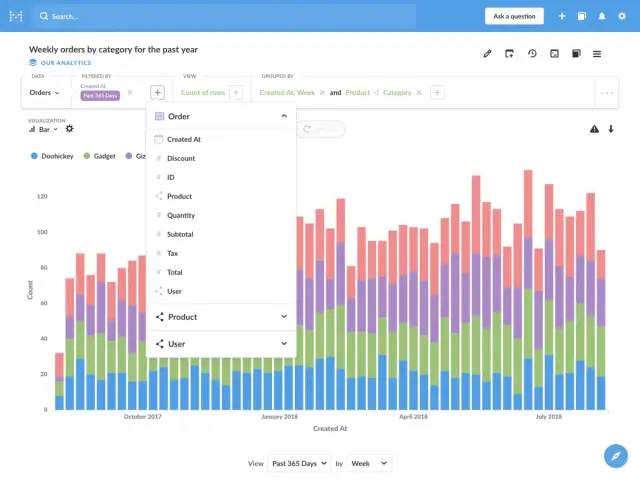
官方的宣传特色(版本号:v0.32.9)
5分钟设置(We're not kidding)
让团队中的任何人在不知道SQL的情况下提出问题
丰富美观的仪表板,自动刷新和全屏
分析师和数据专业人员的SQL模式
为您的团队创建规范细分和指标
使用Pulses按计划发送数据给Slack或发送电子邮件
使用MetaBot随时查看Slack中的数据
通过重命名,注释和隐藏字段,为您的团队人性化数据
整体上,个人体验下来,亮点特色如下:
a)交互体验对业务人员非常友好。通过一个对看板和单图做了一个全局搜索的功能,营造一种”ask a question“的智能场景。即通过搜索框咨询,系统告诉你答案。且整个产品的界面非常简洁明。
b)制作单图时非常简单,以数据为中心,去选择不同的图形(不可选的图形自动打灰)。基本做到了半分钟就能完成一个单图的分析。
但但是最大的不足是权限管理实在太弱,只有可修改/可见的粗粒度控制,对表是否可删除都没法单独控制。
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库* 相对较弱:Postgres、MySQL、SQL Server、Redshift、SQLite、Google BigQuery、H2、Oracle、Vertica、Snowflake、MongoDB、Druid、Presto、SparkSQL
(特别需要注意的是:其中Druid的版本为2.0版本,所以不支持sql查询,威力大打折扣;另外也不支持Hive,Kylin)统一的数据模型管理入口,添加数据表/视图后,设置维度/度量字段(该部分做得很细,设定的类型做了很丰富的扩展)
提供定时任务,数据库同步(小时级别)
自助的表字段信息透视功能,智能化探索,自动出看板,自动关联数据的分布(加分酷炫功能)
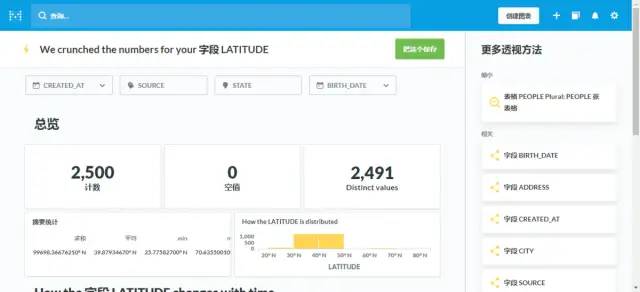
表字段透视
2)chart单图&dashboard看板
单图制作流程非常简单:选择数据源->选择过滤条件->选择分析指标->选择分组维度->选择可视化类型
支持的可视化图形种类仅能满足基本需求,14种可视化方案(包含漏斗、带变化的数字、地图)
对一些图表可做细节控制,比如表单按条件控制行颜色,调整字段位置,显示迷你彩条,前后缀设定
支持基本的过滤条件,包含日期段(通过筛选器的字段与单图中字段的关联)
提供简单的图表钻取功能,但不支持图表的联动
可一键复制已有看板
自动刷新数据最小粒度到1分钟
分享上支持:公开链接,公开嵌入(博客网页),在应用中嵌入
使用Pulses按计划发送数据给Slack(一个国外的聊天工具)或发送电子邮件
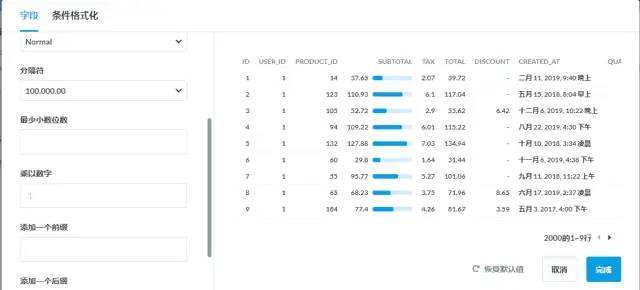
表单格式设置
3)SQL查询
支持关联填补字段/表信息
sql查询结果可直接切换图形展示方案
不支持跨库关联查询
原生查询中的变量允许使用筛选组件或URL参数来动态替换查询中的值
SELECT count(*)FROM productsWHERE 1=1 [[AND id = {{id}}]] [[AND category = {{category}}]]4)权限管理
通过对角色设置权限,用户指定角色,实现权限的控制
权限设置力度非常弱,只能设置是否可访问权限(可访问的数据可能直接被删除)
权限设置对象较浅:仅可对数据源,数据表,图表,分析项目集合的权限控制,不到数据行级
字段级的字段控制可设置可见不可见(敏感字段场景),但不能分角色管理
5)二次开发
技术架构:Clojure+Recat+Redux
提供了完整的API文档,可凭借丰富的API与文档完成许多二次开发
B)Superset (gihub star 25,163)
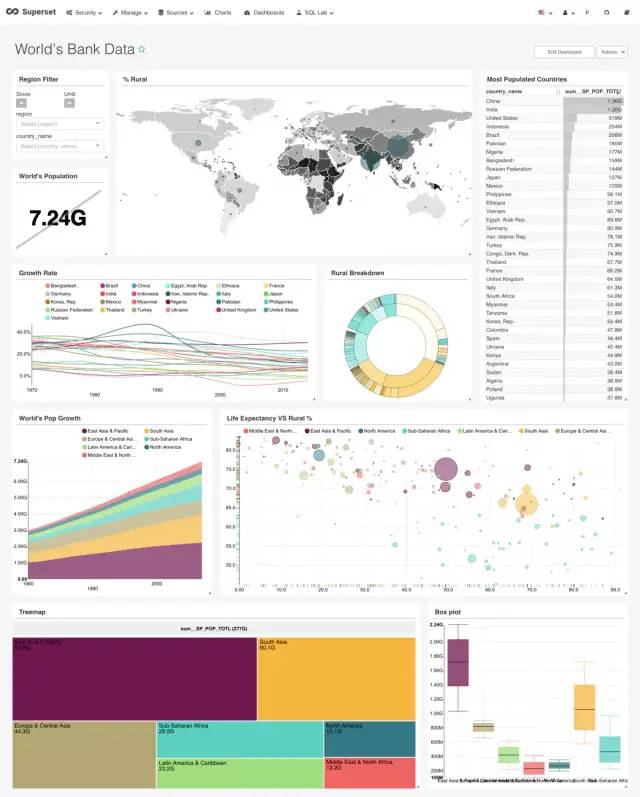
官方的宣传特色(版本号:v0.32.9)
一个直观的界面,用于探索和可视化数据集,以及创建交互式仪表板。
各种漂亮的可视化来展示您的数据。
简单,无代码的用户流程可以深入挖掘并切割暴露仪表板下的数据。仪表板和图表可作为深入分析的起点。
最先进的SQL编辑器/ IDE,提供丰富的元数据浏览器,以及从任何结果集创建可视化的简单工作流程。
可扩展的高粒度安全模型,允许谁可以访问哪些产品功能和数据集的复杂规则。与主要身份验证后端集成(数据库,OpenID,LDAP,OAuth,REMOTE_USER,...)
轻量级语义层,允许通过定义维度和指标来控制数据源向用户公开的方式
开箱即用支持大多数讲SQL的数据库
与Druid的深度集成允许Superset在切割和切割大型实时数据集时保持快速
快速加载仪表板,带有可配置的缓存
整体上,个人体验下来,亮点特色如下:
深度整个主流大数据引擎,SQL查询速度体验没得说;
可视化选择非常丰富,基于经纬度的地理位置可视化方案有好几套;
权限控制非常细,细到每个功能键;
可惜最大的问题是对于业务分析师的用户体验不是很好,可视化流程是要对不同图形方案做对应参数设置,权限控制也非常复杂。
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库* 非常丰富:Athena、Redshift、Drill、Druid、Hive、Impala、Kylin、Spark SQL、BigQuery、Pinot、ClickHouse、Google Sheets、Greenplum、IBM Db2、MySQL、Oracle、PostgreSQL、Presto、Snowflake、SQLite、SQL Server、Teradata、Vertica
支持上传本地CSV文件
数据表模型的管理,可设置字段类型,维度/可否过滤/可否做时间列,二次加工字段,统计指标
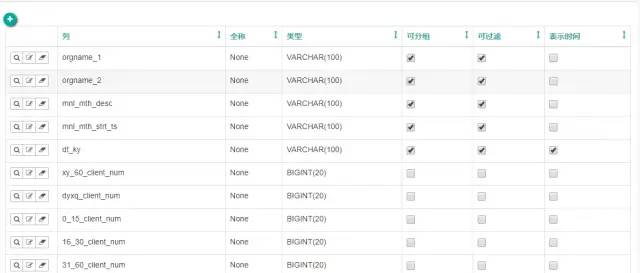
数据模型管理
chart可用的数据表得一个一个从数据库里添加(SQL工具箱可以全部看到),不是很方便。
深度支持durid
2)chart单图&dashboard看板
单图制作流程:选择数据源(表或视图)->选择图表类型->设置图表参数(指标/维度/过滤条件)。选择数据源只能从数据表列表页选择,进到分析页面后无法更换数据源;由于切换不同的图表类型时就要按照不同图重新填写参数,在自助分析时用起来不大方便;
支持的可视化图形种类十分丰富,48种可视化方案;
看板的过滤功能非常弱。连最基本的日期过滤组件没有。通过单图中的过滤器组件实现;只能针对单个数据表做出过滤组件,然后应用到看板上。此功能也很不方便
提供简单的图表钻取探索功能(直接跳入到单图里面),但不支持图表的联动;
数据格式(比如3721,显示成0.4k)可以有很多种方案可供选择
看板不能直接复制克隆,要做复制一个看板只能重新编辑选择单图;
看板支持自动刷新,刷新最小时间粒度为10秒
分享上支持:公开链接,可嵌入其他网页中,可以通过底层参数调整做免密
应用于chart的sql视图必须是select from的形式,否则会查询错误(不能用with as)
不支持邮件发送报表数据
不支持图表/看板的分组
不支持图表的下钻,多图联动
不支持直接对日期范围做筛选
透视表功能不能按行/列做百分比汇总;
Druid引擎的计算结果,不能在superset里面生成新的指标
3)SQL查询支持关联填补字段/表信息
支持跨库关联查询
一个多选项卡环境,一次处理多个查询
查询结果可视化,需要保存成视图,再跳转到chart页面;且需要对该视图做赋权(过程非常不方便)
可对查询历史记录做搜索;
支持使用Jinja模板语言 进行模板化,该语言允许在SQL代码中使用宏
4)权限管理
通过对角色设置权限,用户指定角色,实现权限的控制
权限控制的粒度非常细,支持功能型的权限控制(表的修改可细分到删除,新增操作),支持对菜单,数据源,数据表,字段,图表,看板的权限控制;
权限的配置非常复杂,繁琐.
不支持数据行级控制
5)二次开发
技术架构:Python+Flask+Recat+Redux+SQLAlchemy
原属Airbnb的开源项目,背后有大公司团队支持维护,版本更新,bug修复,二次开发有较大保障
支持restful API
C)Davinci
Davinci 是一个 DVaaS(Data Visualization as a Service)平台解决方案,面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案。既可作为公有云/私有云独立部署使用,也可作为可视化插件集成到三方系统。用户只需在可视化 UI 上简单配置即可服务多种数据可视化应用,并支持高级交互/行业分析/模式探索/社交智能等可视化功能。
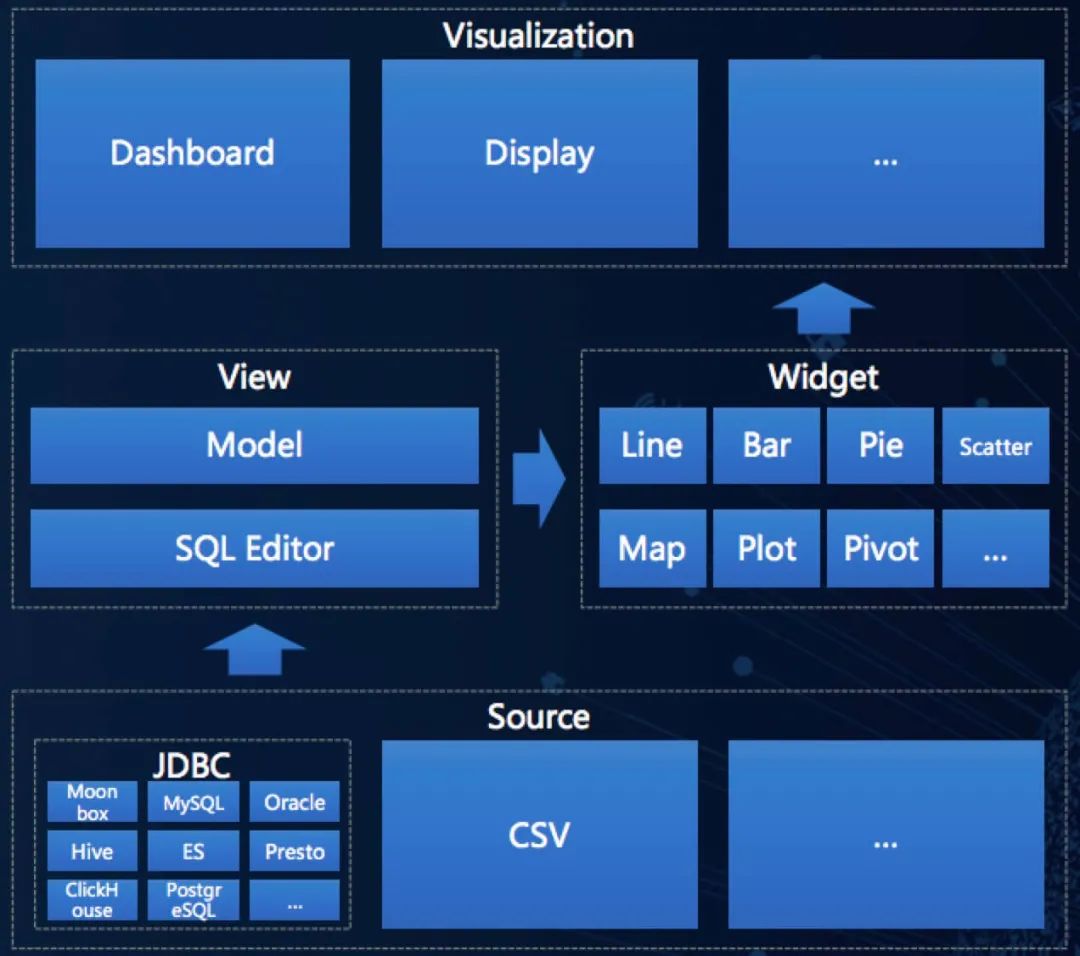
设计理念
围绕 View(数据视图)与 Widget(可视化组件)两个核心概念设计
View 是数据的结构化形态,一切逻辑/权限/服务等相关都是从 View 展开。
Widget 是数据的可视化形态,一切展示/交互/引导等都是从 Widget 展开。
作为数据的两种不同形态,二者相辅相成,让用户拥有一致的体验和认识。
强化集成定制能力和智能社交能力
集成定制能力指无缝集成到三方系统,并提供强大的定制化能力,使其和三方系统融为一体。
社交智能能力指共享优秀的数据可视化思想,激发用户对数据可视化表达能力和艺术美感的追求,同时也使 Davinci 更加智能的引导和提高用户的数据可视化能力。
在数据可视化领域里,Davinci 重视基础的交互能力和多种多样的图表选择能力,同时更加重视集成定制能力和社交智能能力。
功能特点
数据源
支持多种 JDBC 数据源
支持 CSV 数据文件上传
数据模型
支持友好 SQL 编辑器进行数据处理和转换
支持自动和自定义数据模型设计和共享
可视化组件
支持基于数据模型拖拽智能生成可视化组件
支持各种可视化组件样式配置
支持自由分析能力
数据门户
支持基于可视化组件创建可视化仪表板
支持可视化组件自动布局
支持可视化组件全屏显示、本地控制器、高级过滤器、组件间联动、群控控制器可视组件
支持可视化组件大数据量展示分页和滑块
支持可视化组件 CSV 数据下载、公共分享授权分享以及可视化仪表板的公共分享和授权分享
支持基于可视化仪表板创建数据门户
数据大屏
支持可视化组件自由布局
支持图层、透明度设置、边框、背景色、对齐、标签等更丰富大屏美化功能
支持多种屏幕自适应方式
用户体系
支持多租户用户体系
支持每个用户自建一整套组织架构层级结构
支持浅社交能力
安全权限
支持 LDAP 登录认证
支持动态 Token 鉴权
支持细粒度操作权限矩阵配置
支持数据列权限、行权限
集成能力
支持安全 URL 嵌入式集成
支持 JS 融入式集成
多屏适应
支持大屏、PC、Pad、手机移动端等多屏自适应
场景支持
安全多样自助交互式报表
一次配置即可实现可视组件高级过滤、高级控制、联动、钻取、下载、分享等,帮助业务人员快速完成对比、地理分析、分布、趋势以及聚类等分析和决策。
自动布局的 Dashboard(仪表板),适用于大多数通过快速配置即可查看和分享的可视化报表。
自由布局的 Display(大屏),适用于一些特定的、需要添加额外修饰元素的、长时间查看的场景,通常配置这类场景需要花一定的时间和精力,如“双11”大屏。
实时运营监控
实时观察运营状态,衔接各个环节流程,对比检测异常情况,处理关键环节问题。
透视驱动与图表驱动两种图表配置模式,满足不同的应用场景需求。
快速集成
分享链接、IFRAME 或调用开发接口,方便快捷地集成到三方系统,并能够支撑二次开发与功能拓展,充分适应不同业务人员的个性化需求,快速打造属于自己的数据可视化平台。
参考连接
https://www.jianshu.com/p/419300a5244b
https://edp963.github.io/davinci/index.html