点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
幂等性设计
今天我们来聊聊接口的幂等性设计,所谓幂等,就是任意多次执行所产生的影响均与一次执行的影响相同。 幂等性接口是指可以使用相同参数重复执行,并能获得相同结果的接口。这里就不展开数学中的定义了,有兴趣的可以自行google。
为什么接口需要幂等呢?
我们都知道,作为接口的调用方,对于接口调用的结果,一般会返回成功、失败和超时。对于成功和失败,都是明确的状态,调用放可以根据结果做相应的处理,但是对于超时,由于不确定是否成功请求了,作为调用方来说,所以一般都会选择重试。而重试就会出现定义中描述的多次执行。
可以从下面这个例子中加深一下理解:
创建订单时,需要减库存,如果减库存接口超时了,调用方重新调用一次(无论是否成功的执行了减库存代码),应该要保证不会多减一次库存。
要保证不会多件一次库存,一般有两种做法:
接口提供方需要提供相应的查询接口。调用方在超时后去查询一下是否成功。是否多扣一次库存掌握在调用方手里。如果接口是提供给第三方使用的,就会存在一定的风险。
接口支持幂等。这样幂等的保证完全掌握在提供方自己手里,完全不用担心。
全局ID
要让接口支持幂等,要怎么做呢,你可能会想到在减库存之前增加一次查询,已经减过的直接返回不就完事了么?这样确实能达到目的,可是会额外多了一次查询,有没有什么更优的方法呢?
要保证减库存操作的唯一性,可以在接口上多加一个参数,这个参数必须全局唯一,数据库设计表的时候这个字段要加上唯一索引,当多次保存相同数据的时候,数据库就会报错,这就证明了接口已经成功调用过,可以直接返回。
那这个全局ID由谁来分配呢?
可以创建一个分配中心,由中心统一分配。
优点:分配ID与业务集群解耦。
缺点:需要单独维护分配中心,这个分配中心也必须做成高可用集群,增加维护成本。
集成在业务服务集群。
优点:业务服务集群本来就是高可用的,无需提供额外保证。
缺点:分配ID与业务耦合(这其实没什么影响),需要保证业务服务集群生成ID的唯一性。
一般来说,后者是比较好的方案,我们只要提供一个能在集群上生成全局唯一ID的算法即可。
除了保证全局唯一,最好具备以下特点(非必须):
接下来就来说说现阶段常用的全局ID算法。
UUID
UUID设计的目的就是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。关于UUID的设计原理可自行Google。
优点:实现简单(大多数编程语言都集成到工具库了),本地生成,性能好,扩展性高,不需要协定。
缺点:无法递增(消耗数据库性能)、UUID过长(消耗存储空间)。
在中小型项目中,UUID会是不错的选择。 为什么这么说呢?面对并发度不高的系统,数据库性能一般不会达到瓶颈,所以说UUID是牺牲数据库性能换取其优点的一种选择。
Snowflake
Snowflake是Twitter 的开源项目,它生成的ID是64bit的正整数,结构如图:

1bit:固定为0,二进制中最高位为符号位,0为整数,1位负数。所以固定为0表示生成的ID都为正数
41bit:作为毫秒数,大约能用69年。
10bit:作为机器编号(5bit是数据中心ID,5bit为机器ID)。支持1204个实例。
12bit:序列号,一毫秒最多生成2^12=4096个。
优点:递增,且按时间有序。性能高,可根据情况分配bit。
缺点:依赖机器时钟。在分布式系统中,各个机器上的时间不可能完全一样,在同步各机器的时间时,可能会造成重复ID。
在高并发的业务下,Snowflake生成的整数ID的存储和读取性能都要优于UUID。 现阶段国内有很多基于Snowflake算法的特定实现,比如百度的UidGenerator。
关于Redis和MongoDB的设计这里就不展开了。毕竟要强依赖于存储系统,添加了维护成本和风险点。
业务逻辑
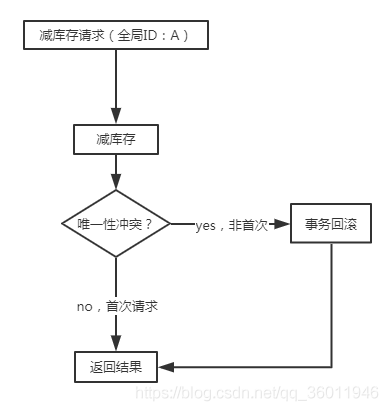
正如我们前面讲过的,要依赖于数据库唯一性约束,当数据库报唯一性冲突时,就说明这个求情已经成功过了,不用再执行,直接返回即可。
HTTP的幂等性
这里给出http请求的幂等性要求:
| 方法 | 幂等 | 描述 |
|---|
| GET | √ | 天然幂等 |
| HEAD | √ | 天然幂等 |
| OPTIONS | √ | 天然幂等 |
| DELETE | √ | 天然幂等 |
| PUT | √ | 天然幂等 |
| POST | × | 需要支持幂等 |
对于POST方法,可能会出现多次提交的问题,比如由于网络不好等原因,造成请求超时,这是用户再点一次提交按钮。对此一般的幂等性解决方法如下:
小结
这篇讲了幂等性设计的要点,并给出了设计方案,大家可根据具体情况选择合适的方案。
作者 | pikaxiao
来源 | csdn.net/qq_36011946/article/details/104200262

 下载APP
下载APP