Netflix因果推理应用调研
共 3180字,需浏览 7分钟
·
2022-06-27 21:23

大数据文摘授权转载自数据派THU
作者:Netflix Technology Blog
翻译:陈之炎
校对:zrx
Netflix旨在通过创造引人入胜的内容,帮助会员发现他们所热爱的游戏娱乐世界。其中的关键在于,需要充分理解产品升级与会员快乐指标相关联的因果效应。
此前,Netflix往往通过AB测试来衡量二者之间的因果效应。而当 AB测试产生局限性时,则可以通过准实验(quasi-experimentation)来解决这一问题。Netflix公司的许多科学家都对因果效应的分析方式做出了贡献。
近期,Netflix的科学家们聚在一起,举办了一次内部的因果推理和实验峰会,以此增进彼此间的相互交流与学习,并借机庆祝一下。为期一周的会议邀请了来自内容、产品和会员团队的演讲者,共同学习交流因果推理的开发和应用。与会者进行了广泛的议题交流,内容涵盖差分估计、双机器学习、贝叶斯AB测试以及推荐系统中的因果推理。
在这篇博文中,我选择了其中几个议题,与读者分享这次峰会的情况,探究社区Netflix因果推理的广度。希望通过进一步的深入交流或其它博文与读者建立联系!
本地化的影响得以加大
Yinghong Lan, Vinod Bakthavachalam, Lavanya Sharan, Marie Douriez, Bahar Azarnoush, Mason Kroll
Netflix公司热衷于为会员提供来自全球的动人故事,这为世界各地的人们所喜爱。目前对30多种语言和190个国家的媒体内容实现了本地化,通过字幕来定位会员最喜欢的内容。理解会员查看到的本地化异构增量值是工作的关键所在!
为了估计本地化的增量值,Netflix公司使用了历史数据的因果推理方法。运行大规模训练或随机实验在技术层面和操作上都富有挑战性,特别是当那些无需对内容进行本地化的会员来说,当访问他们喜欢的内容时,应对内容的本地化有所保留。
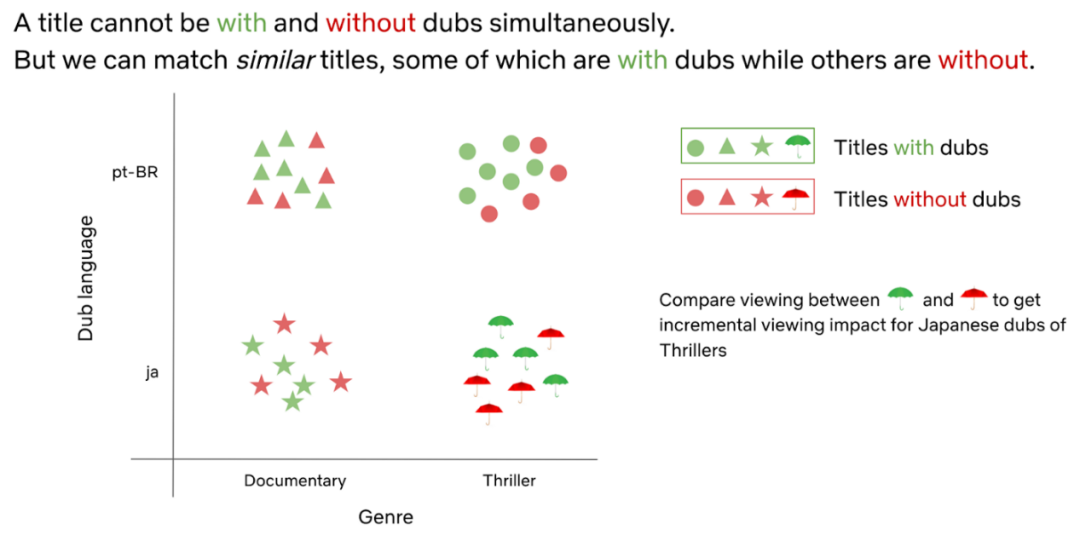
使用双机器学习来控制混杂因素,通过相似标题比对来估计本地化增量的影响。
分析了不同语言的数据,应用双机学习方法来适当地控制测量的混杂因素。不仅研究了本地化对查看标题的影响,而且还研究了本地化如何为会员的不同旅程增值。在稳健性检查方面,探索了通过多种模拟来评估增量估计的一致性和方差。这些见解在决定扩大本地化规模,取悦世界各地的会员中发挥了关键作用。
新冠肺炎蔓延影响下,许多与配音相关的制作工作室都关闭了,于是,因果推理方法在本地化方面的应用便出现了。为了理解配音延迟对观看的影响,采用了合成控制的方法模拟在没有延迟的情况下的观看、在游戏发行时(无配音时)和游戏发布后(重新添加配音时)的观看,并对其进行了比较。
为了控制混杂因素,使用了一个安慰剂试验,对不受配音延迟影响的标题进行了重复分析。通过这种方式,估计出延迟配音的可用性会对会员查看标题产生增量影响。如果配音制作室再次关闭,这些分析结果使得团队够更有信心做出明智的决定。
制作创新的支撑实验
Travis Brooks, Cassiano Coria, Greg Nettles, Molly Jackman, Claire Lackner
Netflix做了很多反向AB测试,向用户展示了无专业特征情况下的体验。通过测量新特征的长期影响或重新检查旧的假设,这大大改善了会员的用户体验。然而,当提出反向测试的话题时,在实验设计和/或工程成本方面往往非常复杂。
通过分享关于反向测试设计和执行的最佳实践,使得Netflix的反向测试更加明晰,以下方式在制作创新团队中广为使用:
1.用过去的示例来定义反向测试的类型及用例;
2.建议使得反向测试增值的机会;
3.列举反向测试所带来的挑战;
4.确定能够降低产品成本、工程团队部署成本和维护反向测试成本的未来投资。
反向测试在许多产品领域都有明确的价值,可以确认学习知识、了解长期影响、重新测试新会员的假设,并衡量累积价值。它们还可以作为一种简化后的产品测试方法,通过删除未使用的特征,创建一个更无缝的用户体验。在Netflix的许多领域,它们已经普遍用于多种应用。

概述反向测试如何工作,保留部分会员的长期经验,以获得产品改进的有价见解。
通过统一最佳实践和提供更简单的工具,可以加速学习过程,并为会员创造最佳的产品体验,来访问他们钟爱的内容。
因果排名:推荐模型的因果自适应框架
Jeong-Yoon Lee, Sudeep Das
大多数用于个性化搜索的机器学习算法,包括深度学习算法,都是纯粹的联想算法,它们从特征和结果之间的相关性中学习如何最好地预测一个目标。
在许多场景下,超越纯粹的联想性质,通过理解采取某种行动和由此产生的增量结果之间的因果机制,来做为决策的关键。因果推理提供了一种学习这种关系的方式,在与机器学习相结合时,成为了一种可大规模利用的强大工具。
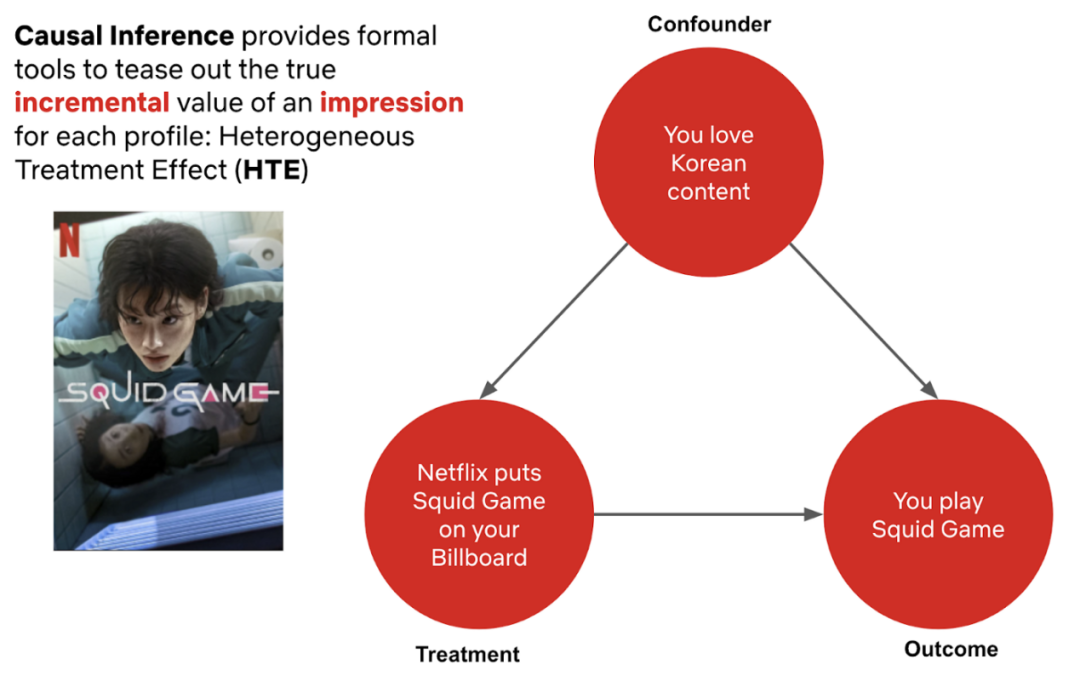
与机器学习相比,因果推理允许建立一个健壮的框架来控制混杂因素,估计出会员的真实增量影响。
当前,Netflix的许多应用都是由推荐模型所驱动,比如在主页上看到的个性化内容,均受益于额外添加的算法,这些算法尽量使得每条推荐对会员尽可能有用,而不仅仅是识别出某人最有可能参与的标题或特征。在现有的系统之上添加新模型之后,可以帮助改进当前系统的建议,帮助会员找到现在想要流媒体的确切标题。
为此,Netflix创建了一个框架,在基础推荐系统之上应用了一个轻的、因果的自适应层,称为因果排名框架。该框架由几个组成部分组成:播放属性印象、真正的负面标签收集、因果估计、离线评估和模型服务。
使用可重用的组件以一种通用的方式构建这个框架,这样Netflix中任何感兴趣的团队都可以将这个框架用于他们的用例,从而在整个产品中改进提供的建议。
Bellmania:Netflix及其应用程序的增量账户生命周期估值
Reza Badri, Allen Tran
了解获取或保留订阅者的数值对于Netflix这样的订阅业务来说至关重要,虽然通常用客户使用寿命值(LTV)对会员进行评估,但对LTV的简单测量可能会夸大获取或保留会员的真实数值,因为潜在会员有可能在没有任何干预的情况下加入进来。
为此,Netflix建立了一种方法和必要的假设,利用基于增量LTV的因果解释来估计获取或保留订阅者的币值。这要求对Netflix在线LTV和线下Netflix LTV二者均进行评估。
为了克服Netflix公司会员数据缺乏问题,他们采用了一种基于马尔可夫链的方法,该方法从非用户的数据中再现线下Netflix公司的LTV。
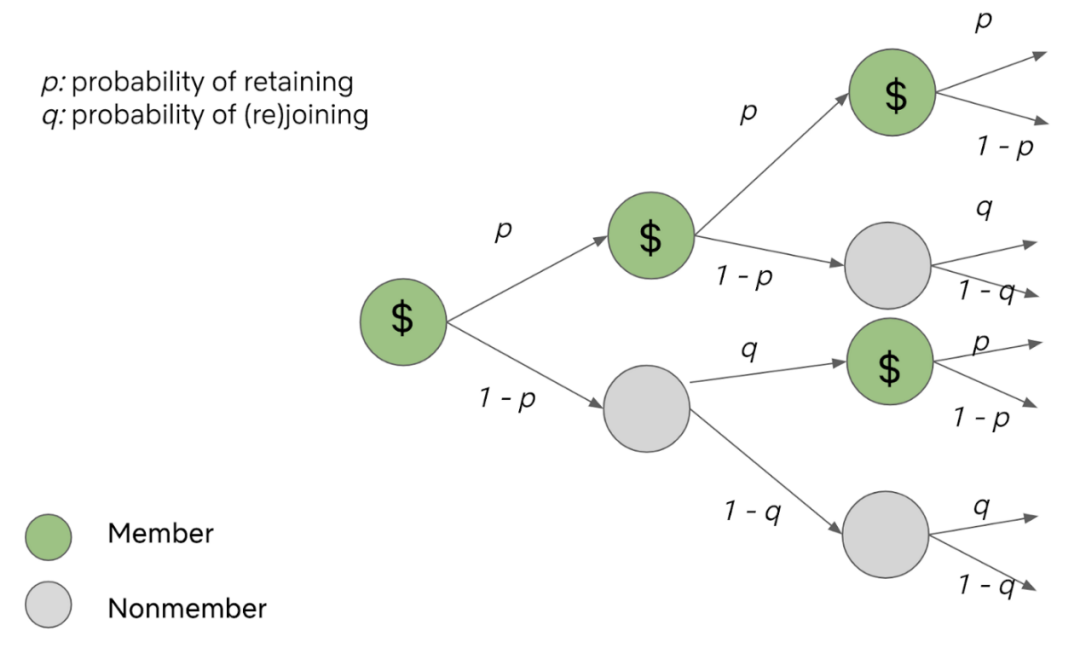
通过马尔可夫链,可以估计出会员和非会员的增量值,从而捕获未来潜在连接的数值。
此外,演示了如何利用该方法(1)预测总用户数量,考虑可寻址市场约束和账户级动态,(2)估计价格变化对收入和订阅增长的影响,(3)提供最优政策,如价格折扣,将会员生命周期内的预期收入最大化。
因果关系的度量是Netflix数据科学文化的很大一部分内容,很自豪有这么多同事利用实验和准实验来驱动会员的印象。这次峰会是一个庆祝彼此工作的好方式,强调了利用因果方法创造出更多的商业价值。
原文标题:
A Survey of Causal Inference Applications at Netflix
原文链接: