
高并发整体可用性:大规模集群下的分片管理策略
1、有状态&无状态的服务部署
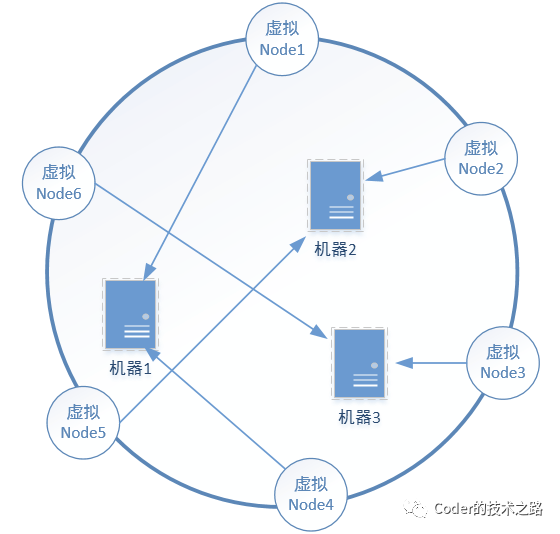
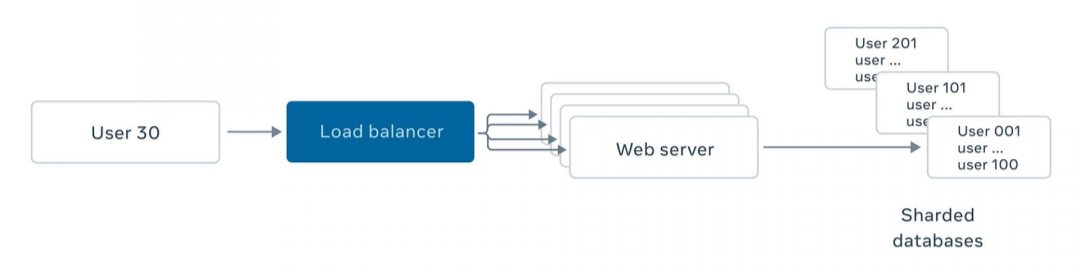
2、故障是一种常态
3、资源是宝贵的,不浪费才最好
异构的硬件。由于硬件规格不同,服务所能承载的压力也不尽相同,因此需要考虑硬件限制来分配负载。 动态资源。比如可用的磁盘空间、空闲的CPU等,如果负载和这些动态资源绑定,那么不同的时间点,服务负载是不能一概而论的。
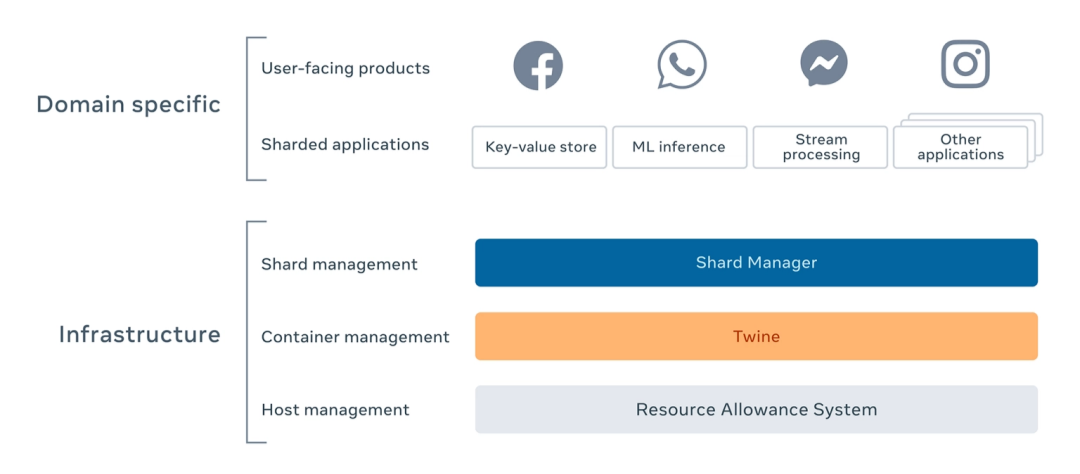
4、Facebook怎么平衡上述诉求[1]
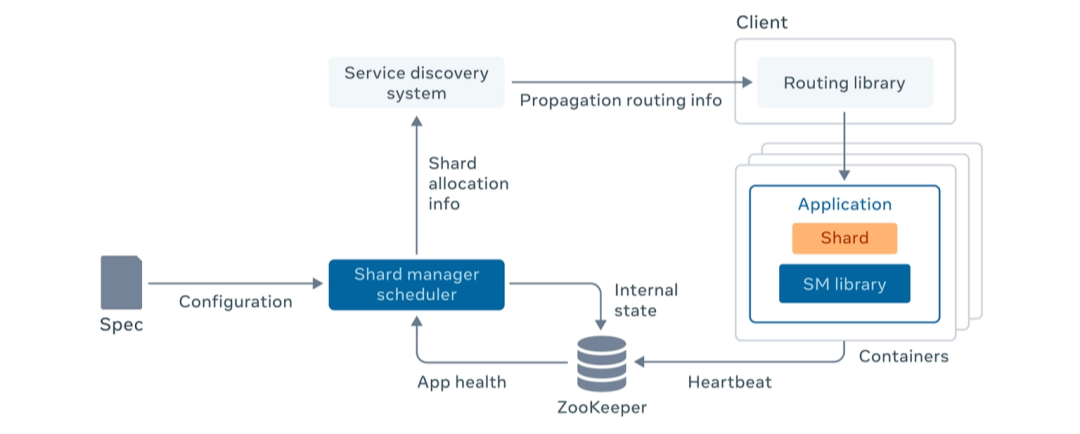
//分片加载
status add_shard(shard_id)
//分片删除
status drop_shard(shard_id)
//主从切换
status change_role(shard_id, primary <-> secondary)
//验证和变更副本成员关系
status update_membership(shard_id, [m1, m2, ...])
//客户端路由计算和直连调用
rpc_client create_rpc_client(app_name, shard_id)
rpc_client.execute(args)
Status status= A.drop_share(xx);
if(status == success){
B.add_share(xx)
}
参考资料
[1]fb engineering: "使用ShardManager扩展服务"
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论