
面试题:让你设计一个延时队列,说说你的思路
共 5010字,需浏览 11分钟
·
2022-01-14 22:10
点击上方蓝色字体,选择“设为星标”

项目背景
延迟队列,它是一种带有延迟功能的消息队列,目前工作中有几处需延时处理的应用场景。
可选技术参考
kafka
考虑前提:由于项目代码与业务方交互大多采用 kafka,所以想是否能自己集成一个 kafka 延迟队列,直接提供延迟功能,更方便使用。
大致思路:借鉴 rocketMQ 延迟队列设计思想,创建多个topic 用于处理不同的延迟消息,例如延迟一分钟的任务消息,让 topic为 delay-minutes-1 进行处理。
发送延迟消息时不直接发到目标topic,而是发到一个用于处理延迟消息的topic,例如 delay-minutes-1
写一段代码定时拉取 delay-minutes-1 中的消息,将满足的消息发到真正的目标主题里。
流程图:
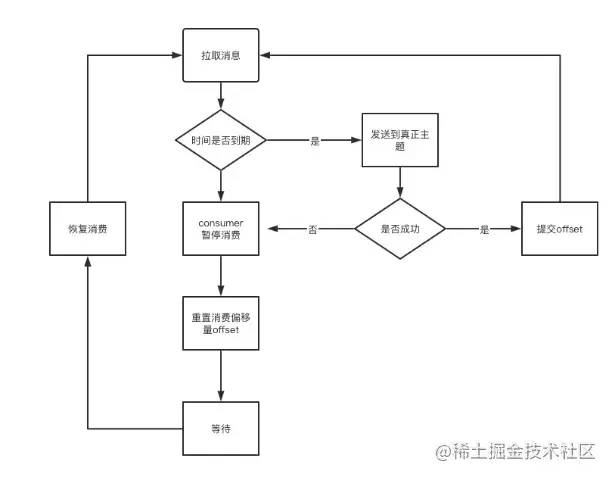
解决问题:如何让延迟消息等待一段时间才发送到真正的topic里面?
答:KafkaConsumer 提供了暂停和恢复的 API 函数,当消费者发现不满足消费时间条件时,可以先暂停消费者,并把消费偏移量移动到上次位置,进行等待下次消费。
缺点:kafka内部改造复杂度较高,由于要使 consumer 进行 pause,还需要额外的做一些健康检查操作,在状态不对时可以报警或者重启。另外,不支持灵活设置延时时间。
rocketMQ
考虑前提:底层代码已经全部封装好,直接使用,不用关心底层代码,可以实现与业务进行解藕。
大致原理思路:
RocketMQ将延时队列的延时时间分为 18 个级别,在发送 MQ消息的时候只需要设置 delayLevel,把每种延迟时间段的消息放到同一个队列中
通过一个定时器进行轮询这些队列,查看消息是否到期
流程图:

缺点:
使用中间件,尽可能的需要熟读底层源码,以便后续出现问题,快速跟踪定位。还有能找到适合的扩展点。
定时器采用的timer是单线程运行,如果延迟消息数量很大的话,可能造成消息到期也没有发送出去的情况。
redis
考虑前提:Redisson延时队列,代码redis已经封装好,可以直接拿来用。redisson.getBlockingQueue() 和 Redission.getDelayQueue()
大致原理思路:https://zhuanlan.zhihu.com/p/343811173
三个核心集合结构:
延时队列:数据入队的队列
目标 blocking 队列 :到期数据待consume
timeoutSet 过期时间zset:分数值为timeout,辅佐判断元素是否过期。
实现 Timer :
运用了 redis 的 sub/pub 功能,当有数据put的时候,先把它放到一个zset集合,同时发布订阅的key,发布内容为数据到期的timeout,此时客户端开启了一个延时任务(HashedWheelTimer),到了时间,从zset分页取出到期了的数据,放入 blocking 队列中。
缺点:
采用 sub/pub 机制的时候,可能会造成多个客户端同时开启一个时间段的延时任务,重复执行,也会有并发的安全问题,因为涉及的要数据加入阻塞队列,和将当前数据从zset移除操作。
默认是数据量小的时候比较稳定,数据量一大就需要构建 cluster模式,这一块需要自己开发
基于Redisson方案进行改造思路
有赞的延时队列
https://tech.youzan.com/queuing_delay/
实现逻辑图
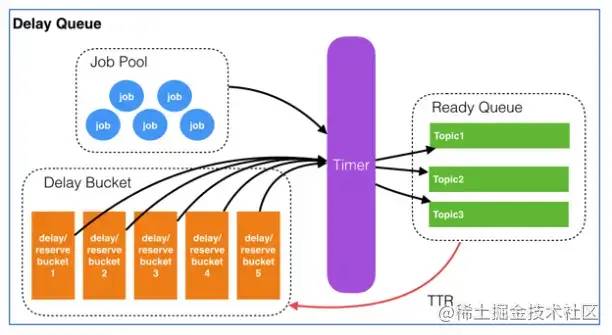
各个组件含义:
job :需要异步处理的任务,是最基本单元,其中属性包含,自定义唯一jobid,topic任务类型,delayTime任务执行时间,ttrtime执行超时时间,message具体消息内容。
job pool :用来存放Job 的原信息,是个 map结构
Delay Bucket :一组以时间为维度的有序队列(这里只存放 job Id),bucket的数据结构就是redis的zset,将其分为多个bucket是为了提高扫描速度,降低消息延迟
Timer: 实时扫描各个 Bucket,并将delay时间小于等于当前时间的job放入到对应的 Ready Queue。
* 自己实现中,此处的Ready Queue 替换一个共同的kafka topic出口:存放处于Ready状态的Job,以供客户端消费程序消费。timer 到时间直接发送到 kafka
对比 Redisson 改动点
去除原有redisson 延时队列 sub/pub实现timer思路,采用轮询 zset 头部节点,判断是否已到过期时间进行判断。
加入线程池概念,加快消息处理,减少延时消息时间误差。
cluster 模式,可用 redis 的 setnx命令实现简单的分布式锁,以保证集群中每次只有一个timer thread执行。
个人改动点
做成通用性服务,提供统一的push topic,和统一的pull topic
整体执行流程:
各个业务方把任务发给入口topic,生成延迟任务,放入某个桶
定时器时刻轮询各个桶,当时间到达,发送消息任务到Kafka
消费端可以从 Kafka 共同出口中取到任务,做相应的业务逻辑
出口topic接收到消息,Kafka确认应答一次,保证消息不丢失
微服务延时队列整体架构图

例子:
kafka 共同入口 delay_entrance_topic 格式:
| 属性 | 类型 | 是否必须 | 含义 |
|---|---|---|---|
| realTopicName | string | 是 | 业务类型,真实投递到的topic |
| delayTime | long | 是 | 任务延时时间 |
| message | string | 是 | 具体消息内容,json字符串 |
kafka 共同出口 delay_exit_topic 格式:
| 属性 | 类型 | 是否必须 | 含义 |
|---|---|---|---|
| delayJobId | long | 是 | 发送到kafka时,发送成功应答时需取这个字段进行后续操作,业务方可不关注 |
| realTopicName | string | 是 | 业务类型,真实投递到的topic,各个业务进行过滤 |
| message | string | 是 | 具体消息内容,json字符串 |
扩展点
减少延时时间误差,使用线程池加快轮训判断时间到期 cluster模式,防止其中一台服务器挂了无法使用,高可用设计,使用定时器维护路由 cluseter模式中,timer 代码逻辑需要设置分布式锁,防止多台服务器同时执行 消息可靠性:保证至少被消费一次,消费不成功,未应答,会重新投递一次。
可能产生的问题
消息持久化问题:基于Redis自身的持久化特性,如果Redis数据丢失,意味着延迟消息的丢失,不过可以做主备和集群保证。这个可以考虑后续优化将消息持久化到MangoDB中。
其他延时队列思路
Netty 时间轮
HashedWheelTimer 流程图
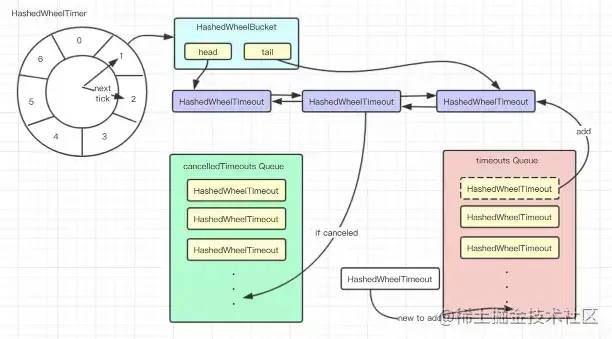
tickDuration: 每个格子的时间大小,每次转动的时间
ticksPerWheel:时间轮数组大小
HashedWheelBucket:数组,记录 header,tail
HashedWheelTimeOut: 延时任务载体,放于Bucket 数组中,属性有:前后指针,round 数等
如果把时间轮看作一个map,那么 tickPerWheel 就为map的size,时间轮开始的时候,会设置一个 startTime,即每ticket都可算出延时时间,也就是 map 的key,value 为bucket。
核心代码,线程 for循环,校验 此刻的 bucket的链表是否到了执行时间,到了就立即执行,且 ticket+1,往下走。没有则会sleep一会儿。
long deadline = tickDuration * (tick + 1);for (;;) {// 相对时间final long currentTime = System.nanoTime() - startTime;long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;// <=0 说明可以拨动时钟了if (sleepTimeMs <= 0) {if (currentTime == Long.MIN_VALUE) {return -Long.MAX_VALUE;} else {return currentTime;}}// 这里是为了兼容 Windows 平台if (PlatformDependent.isWindows()) {sleepTimeMs = sleepTimeMs / 10 * 10;}try {Thread.sleep(sleepTimeMs);} catch (InterruptedException ignored) {if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {return Long.MIN_VALUE;}}}}
kafka 时间轮
在普通时间轮的基础上,以空间换时间的思路,用 DelayQueue 去存储每个 Bucket,DelayQueue 内部有个 PriorityQueue,以每个bucket的延时时间进行大小排序,队首的bucket就为将要执行的任务,如果到期了,则可以直接取出执行,未到则阻塞。依次循环取空优先队列。
其中的比对时间到期,交给底层api去做,Condition.awaitNanos() -> parkNanos() 核心代码:
private[this] val reinsert = (timerTaskEntry: TimerTaskEntry) => addTimerTaskEntry(timerTaskEntry)/** Advances the clock if there is an expired bucket. If there isn't any expired bucket when called,* waits up to timeoutMs before giving up.*/def advanceClock(timeoutMs: Long): Boolean = {var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)if (bucket != null) {writeLock.lock()try {while (bucket != null) {//驱动时间轮timingWheel.advanceClock(bucket.getExpiration())//循环buckek也就是任务列表,任务列表一个个继续添加进时间轮以此来升级或者降级时间轮,把过期任务找出来执行bucket.flush(reinsert)//这里就是从延迟队列取出bucket,bucket是有延迟时间的,取出代表该bucket过期,通过bucket能取到bucket包含的任务列表bucket = delayQueue.poll()}} finally {writeLock.unlock()}true} else {false}}
小问题
对于时间计算方面的问题,底层系统提供的api为什么效率更低呢?
它应该也是循环检查到期时间,看到有的同学说,更推荐使用底层api,原理是一样的,它为什么就比放在外面要好些呢?如果有知道的同学,也可在评论区告诉作者,感恩!
XXL_JOB
主要有两个线程:scheduleThread 负责把 5s 之后要执行的任务,从 db 中扫出来,放到 时间轮 容器中。
ringThread 负责把时针指向的每个到期的任务链表,交由快慢线程,rpc调用指给调度器执行。
分布式任务调度,多个执行器。任务持久化,任务统一先入库,延时也是用的传统时间轮。
总 结
两个非常核心的问题:
一定先给所有的延时任务排序
比对时间问题,到了任务执行时间取出来
| 排序 | 找到到期job | |
|---|---|---|
| RocektMQ | 指定level,类似桶排序 | for 循环 |
| HashedWheelTimer | 数组,桶排序 | for 循环 |
| kafka 时间轮 | 堆排序,PriorityQueue | 底层api实现,Condition.awaitNanos()-> parkNanos() |
| Redisson 延时队列 | Zset 跳表实现 | 先是 sub/pub 订阅功能,客户端到期从zset中拿数据,用的是 HashedWheelTimer |
| 基于有赞延时队列 | Zset 跳表实现 | for循环遍历,开启多个线程,每个bucket一个线程 |
所以,如果想自己设计一个延时队列,关键是确定这两个核心问题怎么解决,其余的根据自己的业务场景进行调整吧。
巨人肩膀
https://juejin.cn/post/6845166891225317384
https://juejin.cn/post/6910068006244581390 https://juejin.cn/post/6976412313981026318