
首个通用语音翻译系统!Meta重磅开源SeamlessM4T:支持100种语言多模态翻译,附47万小时训练数据

新智元报道
新智元报道
【新智元导读】语音翻译无需级联子系统,一个架构支持100种语言!
基于文本的翻译系统已经取得了非常大的进步,从最早的查词匹配、语法规则,再到神经翻译系统、Transformer预训练等,翻译结果越来越精准,支持的互译语言数量也超过了200种。
但与之相对的「语音到语音翻译」模型仍然进展缓慢,目前主要依赖多个子系统级联,先对输入音频转换到文本,再逐步得到翻译结果。
最近,Meta AI和加州大学伯克利联合发布了一个大规模的多语言、多模态机器翻译系统SeamlessM4T,只用一个模型实现支持100种语言的语音到语音翻译、语音到文本翻译、文本到语音翻译、文本到文本翻译和自动语音识别。

Blog post: https://bit.ly/45z0e6s
Demo链接: https://seamless.metademolab.com
论文链接: https://ai.meta.com/research/publications/seamless-m4t/
开源链接: https://github.com/facebookresearch/seamless_communication
为了训练模型的多项能力,研究人员先使用了100万小时的开放语音音频数据来学习w2v-BERT 2.0的自监督语音表征。
然后过滤并结合人工标注和伪标注数据,得到了一个自动对齐的语音翻译多模态语料库SeamlessAlign,总计40.6万小时,也是第一个能同时将语音和文本翻译成英语的多语言系统。
在Fleurs上,SeamlessM4T为多种目标语言的翻译设定了新的标准,在直接语音到文本的翻译方面,BLEU比以前的最高性能模型提高了20%;
与强级联模型相比,SeamlessM4T在语音到文本方面将英译质量提高了1.3 BLEU评分,在语音到语音方面提高了2.6 ASR-BLEU评分。
在CVSS上,与用于语音到语音翻译的2阶段级联模型相比,SeamlessM4T-Large的性能强了58%
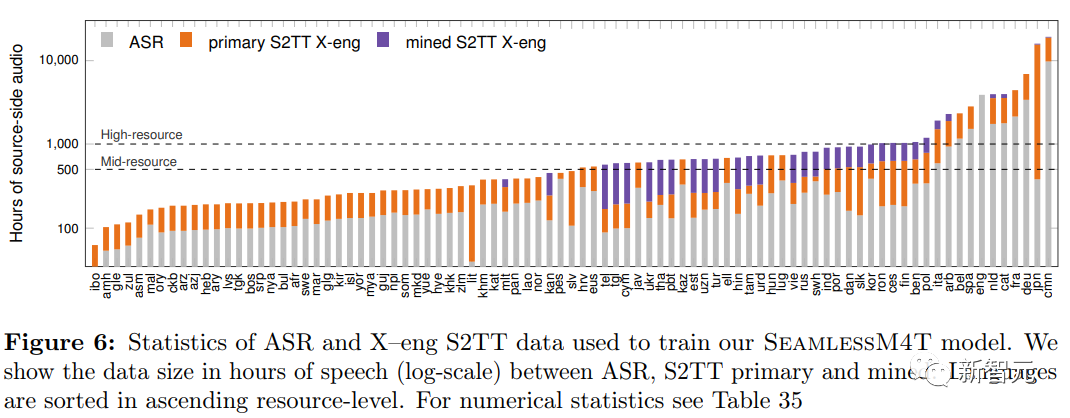
数据准备
数据准备
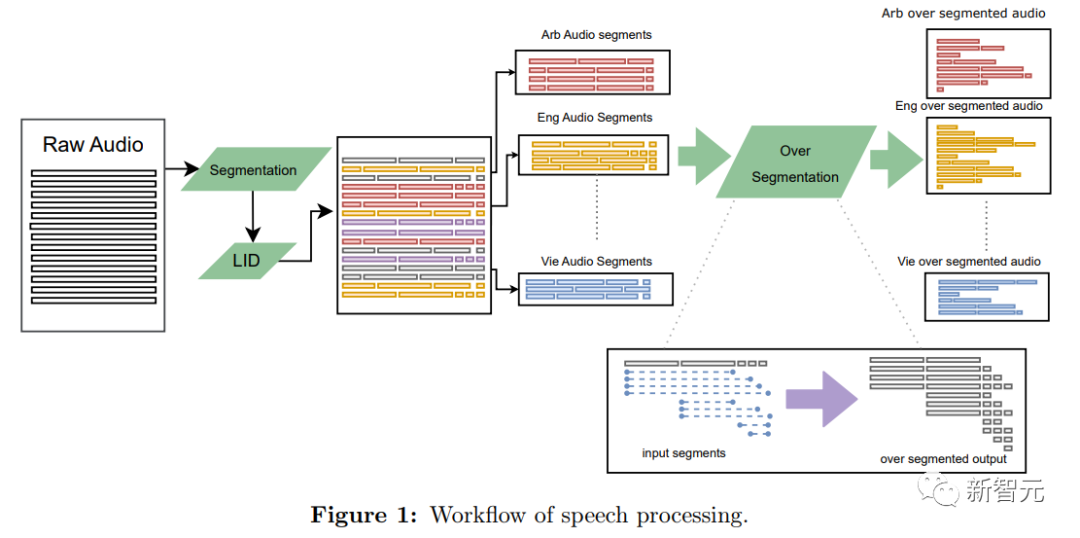
语言识别(LID)
将原始的音频数据按照语言进行分类后,可以提高音频片段的对齐质量,提高下游翻译系统的性能。
研究人员选择ECAPA-TDNN开源架构作为基线模型,在VoxLingua107数据集上重新训练30个epoch后,分类错误率为5.25%;相比之下,开源版模型VL107 HF的错误率为7%
在模型复现验证完毕后,研究人员最终在8个GPU上训练了40个epoch,总耗时172小时,累计使用1.7万小时的语音数据,平均每种语言171小时,具体为1到600小时不等。
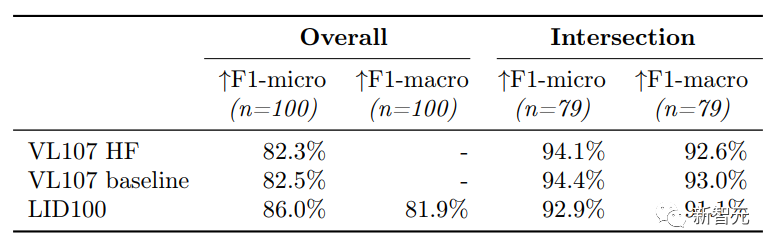
在100种SeamlessM4T语言以及79种VoxLingua107语言的实验中,可以看到,对额外语言的训练会略微降低通用语言集的整体性能,可以是因为引入了更多相似语言,比如祖鲁语(zul)经常与尼亚雅语(nya)混淆,现代标准阿拉伯语(arb)与摩洛哥阿拉伯语(arry)和埃及阿拉伯语(arz)混淆等。
总体来说,新模型在17种语言的分类能力上平均性能提升14.6%,但有12种语言的分类能力下降(平均9.8%)。
除此之外,为了提高LID标签的质量,研究人员还根据特定语言的可用数据量,估算了开发语料库中每种语言正确和错误分类的LID分数高斯分布,设定过滤阈值,使得 p(correct|score) > p(incorrect|score)
在过滤掉8%的数据后,模型的F1指标又进一步提高了近3%
大规模收集原始音频和文本
在文本预处理时,研究人员遵循NLLB团队的策略,使用相同的数据源、清洗策略、过滤步骤等。

论文链接:https://arxiv.org/abs/2207.04672
在音频预处理上,研究人员首先从公开的网络数据抓取库中获取了400万小时的原始音频(其中约100万小时为英语),然后以16KHz频率进行重采样,再使用定制的音频事件检测(AED)模型过滤掉非语音数据。
在音频分割部分, 为了实现S2TT或S2ST挖掘,研究人员将音频文件尽可能分割成小块,使得每个块内只包含一个独立的句子。
但语音中的语义分割仍然是一个开放性问题,不同语言中的停顿都可能代表不同的含义,所以研究人员先采用语音活动检测(VAD)模型将音频文件分割成较短的片段,再在每个文件上使用语音LID模型,最后为每个片段创建了多个可能的重叠片段,并使用挖掘算法选择最佳片段,过度分割的策略使得潜在分段数量增加了八倍。
语音挖掘
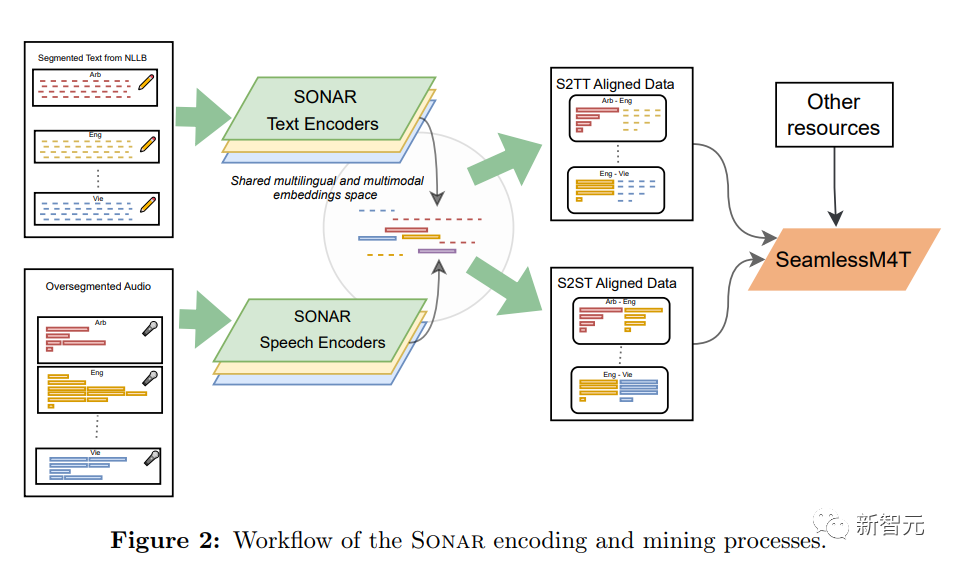
在挖掘过程中,研究人员先训练了一个文本编码器和语音编码器,然后利用两个编码器将文本和语音模态的数据投影到联合嵌入空间SONAR(Sentence-level multimOdal and laNguage-Agnostic Representations)中。
文本编码器的训练方法为,首先训练文本嵌入空间,再利用师生训练策略将其扩展到语音模态,初始文本SONAR空间采用了编码器-解码器架构,基于NLLB-1.3B模型,能够翻译200种语言。
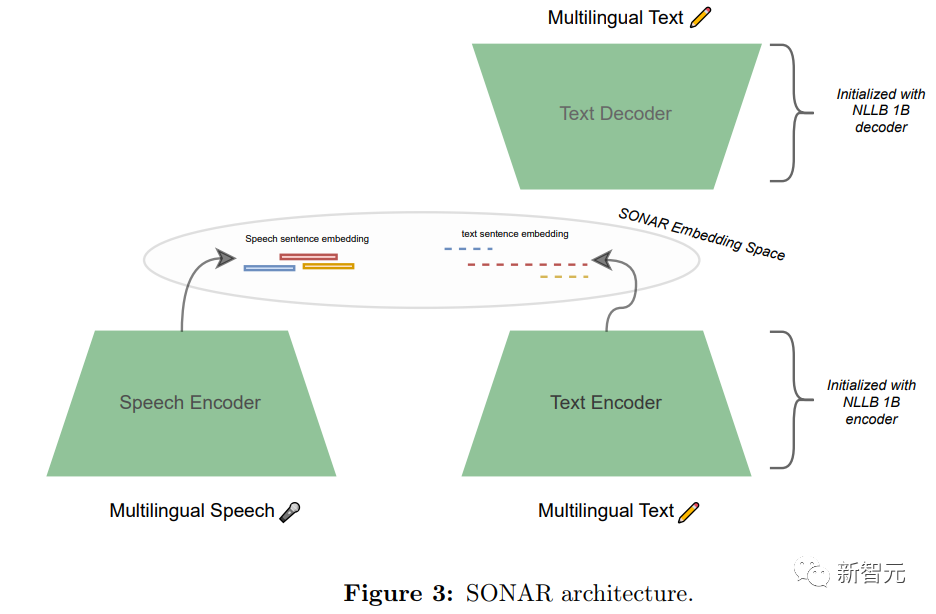
研究人员使用平均池化(mean-pooling)将中间表示转换为固定大小的向量,即解码器只需关注一个向量,然后利用NLLB的所有 T2TT训练数据对这一架构进行了微调。
在语音编码器的训练中,先通过预训练 XLS-R 模型的 BOS 输出,获得了固定大小的语音表征,然后对该模型进行微调,以最大化该集合语音表征与相同语言(ASR 转录)或英语(语音翻译)句子嵌入之间的余弦损失。
最后根据文本句子或其他语言的语音片段挖掘语音片段来生成S2TT和S2ST数据对以训练SeamlessM4T模型。
研究人员进行了全局挖掘(global mining),即将一种语言的所有语音片段与另一种语言的所有语音片段进行比较,利用faiss库对所有嵌入进行索引可以实现在GPU上高效的大规模相似度搜索。
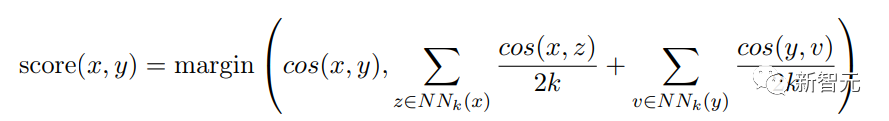
SeamlessM4T模型架构
SeamlessM4T模型架构
研究人员设计SeamlessM4T的目标之一是,通过构建一个更强大的直接X2T模型(用于将文本和语音翻译成文本)来弥合大型多语言和多模态设置中S2TT的直接和级联模型之间的差距,将强大的语音表示学习模型与大规模多语言T2TT模型相结合。
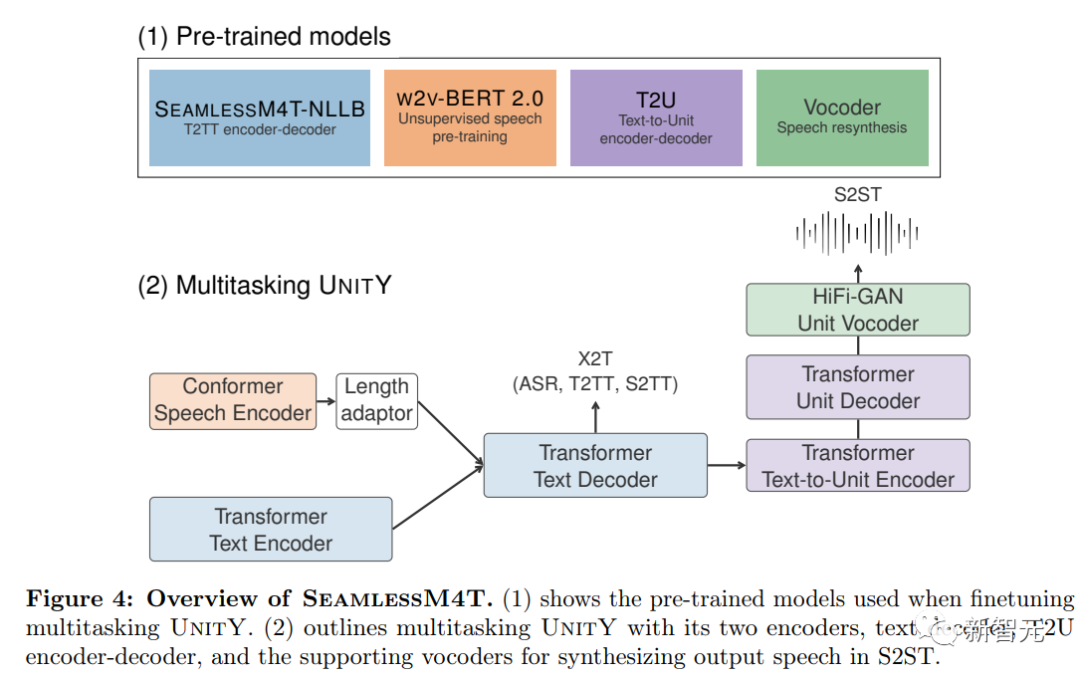
无监督语音预训练
语音识别和翻译任务的标注数据非常难获得,对于低资源语言来说更是如此,所以研究人员对语音翻译模型的训练思路是先采用自监督学习进行预训练后再用少量数据微调,可以在数据量不足的情况下提升模型的极限性能。
研究人员在Seamless M4T Large中采用w2v BERT 2.0预训练语音编码器的w2v BERT XL架构,具有24个Conformer层和大约600M的模型参数。
w2v BERT 2.0模型基于100万小时的开放语音音频数据进行训练,覆盖了超过143种语言。
w2v-BERT 2.0遵循w2v-BERT的设计思路,将对比学习和遮罩预测学习相结合,不过调整了其中两个学习目标。
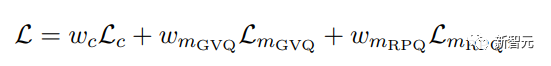
对比学习模块用于学习Gumbel矢量量化(GVQ)词表(codebook)和上下文表征,之后用遮罩预测学习在不同任务中细化上下文表征,而不是在遮罩位置对预测概率进行极化。
w2v-BERT 2.0没有使用单一的GVQ词表,而是用两个GVQ码本的乘积量化。
X2T:文本翻译与转录
多任务UnitY框架的核心部分X2T是一个多编码器序列模型,语音输入用的是基于Conformer的编码器,文本使用基于Transformer的编码器。
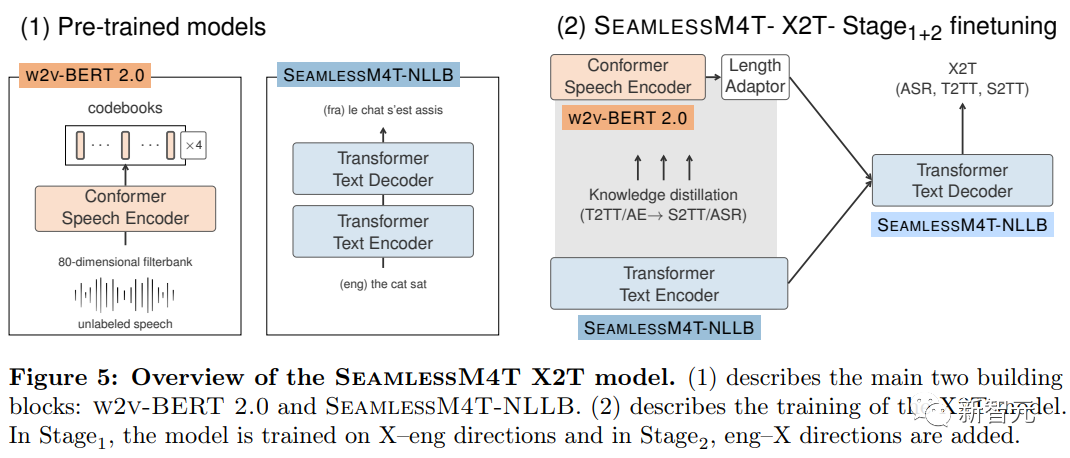
X2T模型的训练数据为S2TT,即包含一段源语言的音频和目标语言的文本。
研究人员分两个阶段训练X2T模型:
第一阶段在标注英语ASR和英语S2TT数据进行有监督训练,这一过程可以同时提升X-eng(某个语言到英语)及eng-X的翻译性能。
在这一过程中,研究人员猜想,模型只关注一种目标语言,同时用多语言语音表征进行微调的话,可以避免从目标语言反向传播回来的干扰信号。
在第二阶段,将标注eng-X S2TT和非英语ASR数据添加到混合数据集中。
语音到语音翻译(S2ST, Speech-to-Speech Translation)
S2ST问题的关键是使用自监督离散声学单元来表示目标语音,从而将S2ST问题分解为语音到单元翻译(S2UT)和单元到语音(U2S)转换。
对于S2UT问题,使用UnitY作为two-pass解码框架,首先生成文本,然后预测离散的声学单元。
与基本UnitY模型相比,SemalessM4T中的UnitY对初始化的S2TT模型进行预训练来联合优化T2TT、S2TT和ASR的X2T模型;T2U模型更深,包含6个Transformer层;使用预训练T2U模型而非从头初始化。
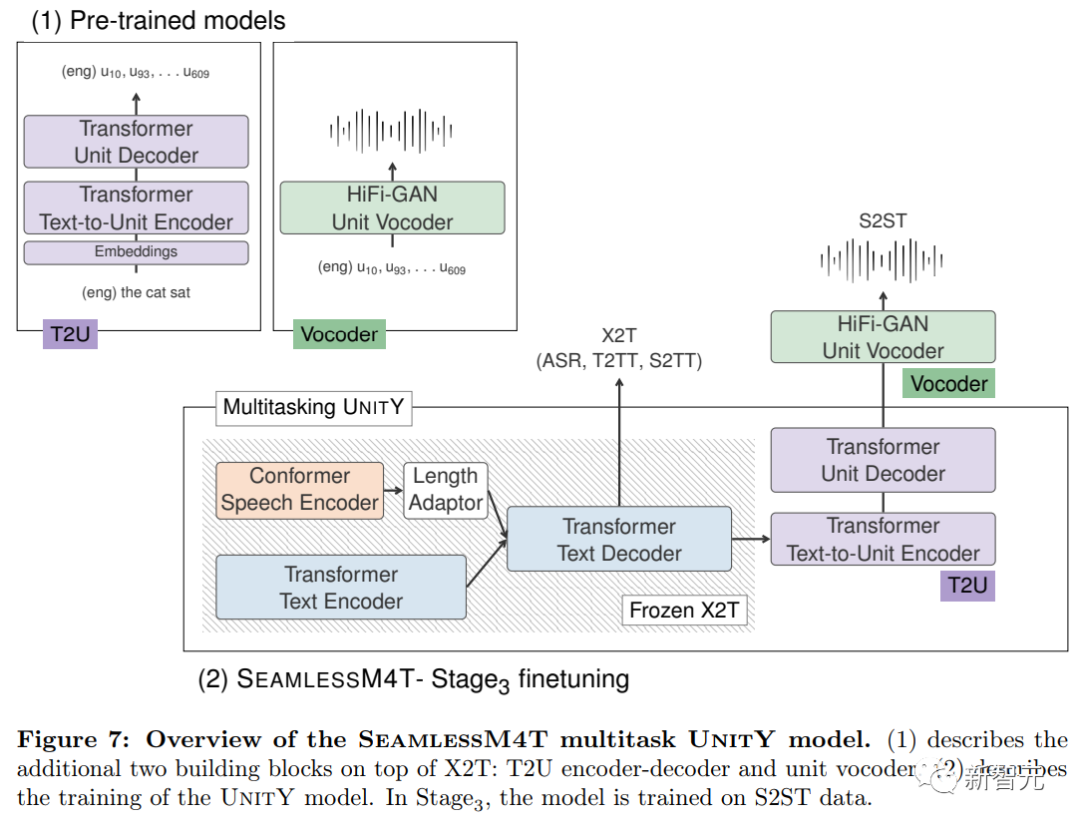
预训练X2T具有更强的语音编码器和更高质量的first-pass文本解码器,并且更大规模的预训练T2U模型可以在不受干扰的情况下,更好地处理多语言单元生成。
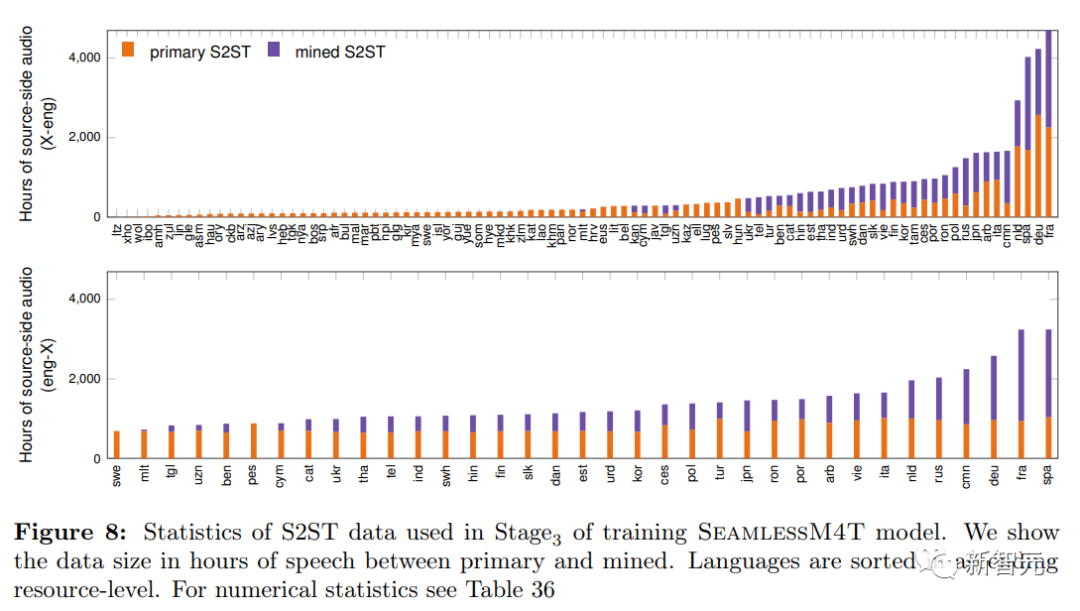
在微调的最后阶段,用预训练X2T模型和预训练T2U模型对多任务UnitY模型初始化后,使用总计12.1万小时的X-ENG和ENG-X S2ST翻译数据对T2U组件进行微调,确保模型对先前微调阶段任务的性能保持不变。
SeamlessM4T模型
经过前面三个阶段的训练后,最终得到的SeamlessM4T-Large模型具有2.3B参数,在T2TT任务上针对95种与英语配对的语言进行了微调,在ASR任务上针对96种语言进行了微调,在S2TT任务上针对89种与英语配对的语言进行了微调。

为了提供不同尺寸的模型,研究人员遵循相同的步骤来训练得到SeamlessM4T-Medium,参数量比SeamlessM4T-Large少57%,可以更方便地测试和微调以进行实验分析和改进。
实验评估
实验评估
研究人员在四个有监督任务(T2TT、ASR、S2TT和S2ST)以及文本到语音翻译的零样本任务(T2ST,跨语言文本到语音合成)上评估了SeamlessM4T模型。
在S2ST和T2ST推理过程中,模型进行two-pass beam search解码,宽度为5,先用文本解码器找到最佳假设(best hypothesis),然后输入到T2U中搜索最佳单位序列假设。
级联方法对比
在SeamlessM4T和Whisper支持的语言集上,研究人员对比了Whisper ASR模型和NLLB T2TT模型的组合。
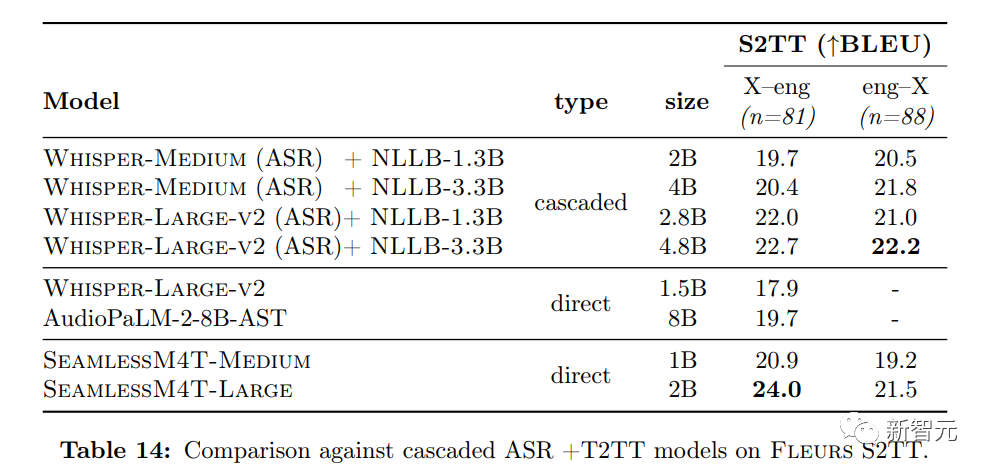
可以看到,SeamlessM4T-Large在x-eng方向上比参数小于3B的级联模型高出2个BLEU评分,在eng-x方向上比参数小于3B的级联模型高出0.5个BLEU评分。
当使用大型NLLB-3.3B T2TT模型(超40亿参数量)的级联模型时,也只在eng-X方向上优于SeamlessM4T-Large
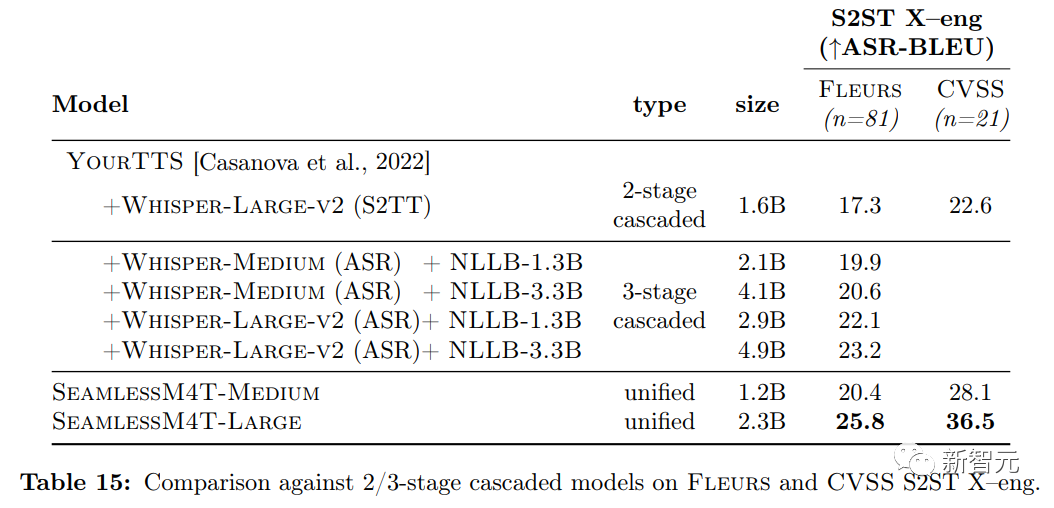
在S2ST任务的对比中,SeamlessM4T-Large在Fleurs X-Eng方向上比2级级联模型高出9个ASR-BLEU点,比3级级联模型高出2.6个ASR BLEU评分。
在CVSS上,SeamlessM4T-Large比2级级联模型高出14个ASR-BLEU评分;在Fleurs Eng-X方向上,SeamlessM4T-Large在32个X-Eng方向上的平均ASR-BLEU为21.5,比Whisper-Large-v2(用于ASR-BLEU的ASR模型)的WER高于100。


