
Hudi 实践 | AWS EMR Hudi 2020年度回顾
本文是AWS EMR 2020年的年度回顾,可以说都是一些"大事记"。在这样一篇回顾中,"Hudi"框架被提及了12次且占据了一个完整的小章节"更简单的增量数据处理"。EMR为何如此看好Apache Hudi(自Hudi还在Apache 孵化器中,EMR就集成了它),它为云上客户解决了哪些问题,请看下文解读。
1. 概述
成千上万的客户在Amazon EMR上使用Apache Spark,Apache Hive,Apache HBase,Apache Flink,Apache Hudi和Presto运行大规模数据分析应用程序。Amazon EMR自动管理这些框架的配置和扩缩容,并通过优化的运行时提供更高性能,并支持各种Amazon Elastic Compute Cloud(Amazon EC2)实例类型和Amazon Elastic Kubernetes Service(Amazon EKS)集群。Amazon EMR方便数据工程师和数据科学家通过Amazon EMR Studio(预览版)和Amazon EMR Notebook轻松开发、可视化和调试数据科学应用程序。
可以参考来自客户在2020 AWS re:Invent大会上的一些talk
•How Nielsen built a multi-petabyte data platform using Amazon EMR[1]•Contextual targeting and ad tech migration best practices[2]•The right tool for the job: Enabling analytics at scale at Intuit[3]
以下博客提供了更多信息
•How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets[4]•How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale[5]•Dream11’s journey to building their Data Highway on AWS[6]•Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake[7]
回顾2020年,EMR团队致力于以较低的价格提供更好的Amazon EMR性能,并使Amazon EMR在LakeHouse架构中更易于管理和更易于分析,本篇文章总结了过去一年的主要改进。
2. 差异化的引擎性能
Amazon EMR简化了大数据环境和应用程序的构建和运维,可以在几分钟内启动EMR群集,并且无需担心基础架构设置、集群设置、配置或调优。Amazon EMR负责这些任务,可以使得团队集中精力专注业务开发。除了避免构建和管理自己的基础架构来运行大数据应用程序的运维外,Amazon EMR还提供了比开源发行版更好的性能,并提供了100%的API兼容性。这意味着可以以更快速度运行工作负载而无需修改任何代码。
适用于Apache Spark的Amazon EMR运行时是针对Spark进行性能优化的运行时。我们首先在2019年11月在Amazon EMR 5.28.0版中引入了适用于Apache Spark的EMR运行时,并使用TPC-DS基准的查询来衡量相较于开源Spark 2.4的性能提升。测试结果表明相比开源版本查询执行时间的平均快了2.4倍,总查询运行时间快了3.2倍,最新结果表明Amazon EMR 5.30的运行速度是没有运行时的3倍,这意味着运行PB级数据可以以不到传统本地解决方案一半的成本进行规模分析。
我们还改善了Hive和PrestoDB的性能。2020年4月我们宣布从Amazon EMR 6.0开始支持Hive低延迟分析处理(LLAP)服务。测试表明在Amazon EMR 6.0上使用Hive LLAP比Apache Hive快两倍。2020年5月我们在Amazon EMR 5.30中引入了PrestoDB的Amazon EMR运行时,使用TPC-DS基准查询比较了使用运行时的Amazon EMR 5.31与未使用运行时的Amazon EMR 5.29,测试结果表明使用Amazon EMR 5.31和PrestoDB的运行时,查询执行时间的平均值快2.6倍。
3. 更简单的增量数据处理
Apache Hudi[8] (Hadoop Upserts, Deletes and Incrementals)是一个开源数据管理框架,用于简化增量数据处理和数据管道开发,基于Apache Hudi,可以在Amazon Simple Storage Service(Amazon S3)数据湖中执行记录级的插入,更新和删除,从而简化构建变更数据捕获(CDC)管道,借助此功能你可以遵守数据隐私法规并简化数据提取管道,以处理来自流式管道输入和事务系统CDC等来源的迟到或更新的记录。Apache Hudi与开源大数据分析框架(例如Apache Spark,Apache Hive和Presto)集成,并以Apache Parquet和Apache Avro等开放格式维护Amazon S3或HDFS中的数据。
我们从2019年11月的Amazon EMR 5.28版本开始支持Apache Hudi。2020年6月Apache Hudi从孵化器毕业,并发布了0.6.0版本,我们在Amazon EMR 5.31.0、6.2.0及更高版本支持了该版本。Amazon EMR团队与Apache Hudi社区合作开发了一个新的引导功能特性,该功能用于将Parquet数据集转化为Hudi数据集,而无需重写数据集。此引导功能可加快从现有数据集迁移至Apache Hudi数据集过程,经过测试,使用Amazon S3上的1 TB Parquet数据集,引导执行的速度比批量插入快五倍。
在2020年6月,从Amazon EMR版本5.30.0开始支持了HoodieDeltaStreamer实用程序,该实用程序提供了一种从许多来源(包括AWS数据迁移服务(AWS DMS))提取数据的简便方法,通过此集成,可以以无缝,高效和连续的方式将数据从上游关系数据库提取到S3数据湖中。有关更多信息,请参阅使用Amazon EMR和AWS数据库迁移服务上的Apache Hudi将记录级别变更从关系数据库应用于Amazon S3数据湖[9]
Amazon Athena和Amazon Redshift Spectrum增加了对基于S3的数据湖中的Apache Hudi数据集查询的支持。Athena于2020年7月宣布支持查询Hudi表[10],而Redshift Spectrum 9月宣布支持查询Hudi表[11]。你可以继续使用Amazon EMR中的Apache Hudi[12]对数据集进行更改,然后从Athena和Redshift Spectrum查询Apache Hudi写入时复制(CoW)数据集的最新快照。
4. 差异化的实例性能
除了通过Amazon EMR运行时提供更好的软件性能外,EMR团队还提供了更多的实例选项,可以选择为工作负载提供最佳性能和成本的实例,可以根据应用程序的要求选择在群集中配置哪些类型的EC2实例(标准,高内存,高CPU,高I / O),并完全自定义群集来满足需求。
2020年12月,我们宣布Amazon EMR现在支持6.1.0、5.31.0及更高版本的M6g,C6g和R6g实例,可以使得能够使用由AWS Graviton2处理器实例,AWS使用64位Arm Neoverse内核定制设计了Graviton2处理器,为Amazon EC2中运行的云工作负载提供最佳的价格性能。尽管性能优势会因工作负载的不同特性而有所不同,基于TPC-DS 3 TB基准测试表明,Apache Spark的EMR运行时与Graviton2相比,性能提高了15%,成本降低了30%。
5. 更容易的集群优化
我们还使优化EMR群集变得更加容易。2020年7月我们推出了Amazon EMR Managed Scaling,这项新功能可自动调整EMR集群大小,从而以最低的成本实现最佳性能。EMR托管扩展无需预先预测工作负载模式,也无需先深入了解应用程序框架(例如Apache Spark或Apache Hive)的规则,相反只需要指定集群最小和最大计算资源限制,Amazon EMR会根据工作负载监视关键指标并优化集群大小以实现最佳资源利用率,Amazon EMR可以在高峰期扩大集群规模,并在闲置期间优雅地缩减集群规模,从而将成本降低20–60%。
Amazon EMR 5.30.1及更高版本上的基于Apache Spark,Apache Hive和YARN的工作负载均支持EMR托管扩展,EMR托管扩展支持EMR实例队列,可以无缝扩展竞价型实例、按需实例以及保留的一部分实例,它们都在同一集群中,可以利用Managed Scaling获取最低成本配置的集群。
2020年10月,我们宣布Amazon EMR支持配置EC2竞价型实例的容量优化分配策略,容量优化分配策略会自动利用可用的备用容量,同时仍然可以利用竞价型实例提供的大幅折扣,这为Amazon EMR提供了更多选择。
6. 工作负载合并
以前需要在Amazon EC2上使用完全托管的Amazon EMR或在Amazon EKS上管理Apache Spark之间选择。在Amazon EC2上使用Amazon EMR时,可以从多种EC2实例类型中进行选择以满足价格和性能要求,但是不能在集群上运行多个版本的Apache Spark或其他应用程序,并且不能为非Amazon EMR应用程序使用未使用的容量。在Amazon EKS上对Apache Spark进行自我管理时必须进行繁重的安装、管理和优化,Apache Spark才能在Kubernetes上运行,并且无法从Amazon EMR优化运行时受益。
2020年12月,我们宣布Amazon EKS上的Amazon EMR合并,这是Amazon EMR新的部署选项,可以在Amazon EKS上运行完全托管的开源大数据框架。如果已经使用Amazon EMR,则可以在同一Amazon EKS集群上将基于Amazon EMR的应用程序与其他基于Kubernetes的应用程序合并以提高资源利用率并使用常见的Amazon EKS工具简化基础架构管理。如果当前正在Amazon EKS上自我管理大数据框架,则现在可以使用Amazon EMR来自动进行设置和管理,并利用优化的Amazon EMR运行时来提供更好的性能。
7. 更高的开发生产力
使用Amazon EMR的目标不仅是要为大数据分析工作负载实现最佳的价格性能,而且还要提供业务新见解。
2020年11月我们发布了Amazon MWAA,这是一项完全托管的服务,可轻松在AWS上运行Apache Airflow的开源版本以及构建工作流以运行提取,转换和加载(ETL)作业和数据管道。Airflow流程使用Athena查询从Amazon S3等来源检索输入,在EMR集群上执行转换,并可以使用所得数据在Amazon SageMaker上训练机器学习(ML)模型。使用Python编程语言,将Airflow中的工作流编写为有向非循环图(DAG)。
在AWS re:Invent 2020上我们介绍了EMR Studio的预览,EMR Studio使数据科学家可以轻松地开发、可视化和调试用R,Python,Scala和PySpark编写的应用程序。它提供了完全托管的Jupyter笔记本以及Spark UI和YARN Timeline Service之类的工具来简化调试,用户可以将应用程序所需的自定义Python库或Jupyter内核直接安装到EMR集群,并可以连接到代码存储库(例如AWS CodeCommit,GitHub和Bitbucket)进行协作。
EMR Studio内核和应用程序在EMR群集上运行,因此使用针对Apache Spark进行了性能优化的EMR运行时可以获得分布式数据处理的优势。也可以在AWS Service Catalog中创建集群模板以简化数据科学家和数据工程师的工作负担,并可以利用在Amazon EC2/Amazon EKS上运行的EMR集群。
8. 统一治理
在AWS我们建议使用现代化的Lakehouse架构来构建云上数据和分析基础架构。这不仅涉及将数据湖与数据仓库集成在一起,而且还涉及将数据湖、数据仓库和专用分析服务集成在一起,并实现统一的治理和数据移动。
如下图所示,Amazon EMR与Amazon S3,Amazon Redshift等一起构成AWS上Lakelouse体系结构。
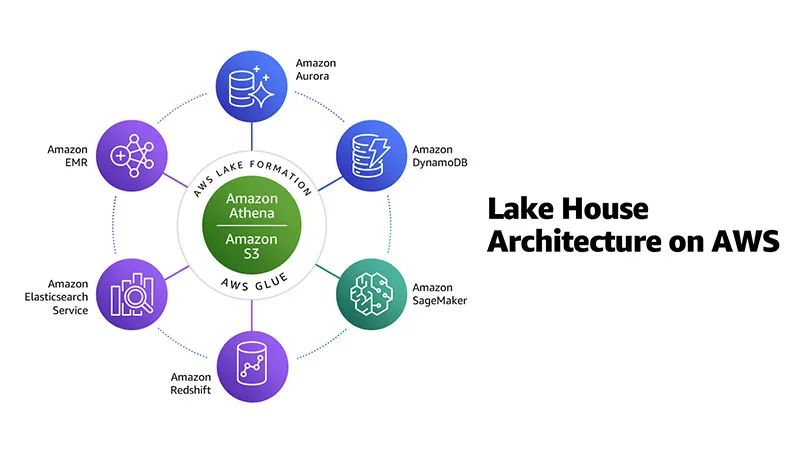
现代分析体系结构中最重要的部分之一就是可以授权、管理和审核对数据的访问。AWS提供了细粒度的访问控制和治理,可以从一个控制点管理跨整个数据湖的数据访问以及专用数据存储和分析服务。
在2021年1月Amazon EMR集成了Apache Ranger,Apache Ranger是一个开源项目,为Hadoop和相关的大数据应用程序(如Apache Hive,Apache HBase和Apache Kafka)提供授权和审核功能。从Amazon EMR 5.32开始,Apache Ranger 2.0插件可启用对Apache SparkSQL,Amazon S3和Apache Hive授权和审核功能。可以设置多租户EMR集群,使用Kerberos进行用户身份验证,使用Apache Ranger 2.0进行授权,以及为数据库、表、列和S3对象配置细粒度的数据访问策略。
推荐阅读
Apache Flink 1.12.2集成Hudi 0.9.0运行指南
引用链接
[1] How Nielsen built a multi-petabyte data platform using Amazon EMR: https://virtual.awsevents.com/media/t/1_ymtl9193/186983973[2] Contextual targeting and ad tech migration best practices: https://virtual.awsevents.com/media/1_0n1tx6s5[3] The right tool for the job: Enabling analytics at scale at Intuit: https://virtual.awsevents.com/media/1_pyv5726q[4] How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets: https://aws.amazon.com/blogs/big-data/how-the-allen-institute-uses-amazon-emr-and-aws-step-functions-to-process-extremely-wide-transcriptomic-datasets/[5] How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale: https://aws.amazon.com/blogs/big-data/how-the-zs-covid-19-intelligence-engine-helps-pharma-med-device-manufacturers-understand-local-healthcare-needs-gaps-at-scale/[6] Dream11’s journey to building their Data Highway on AWS: https://aws.amazon.com/blogs/big-data/dream11s-journey-to-building-their-data-highway-on-aws/[7] Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake: https://aws.amazon.com/blogs/big-data/enhancing-customer-safety-by-leveraging-the-scalable-secure-and-cost-optimized-toyota-connected-data-lake/[8] Apache Hudi: https://hudi.apache.org/[9] 使用Amazon EMR和AWS数据库迁移服务上的Apache Hudi将记录级别变更从关系数据库应用于Amazon S3数据湖: (https://aws.amazon.com/blogs/big-data/apply-record-level-changes-from-relational-databases-to-amazon-s3-data-lake-using-apache-hudi-on-amazon-emr-and-aws-database-migration-service/)[10] 宣布支持查询Hudi表: https://aws.amazon.com/about-aws/whats-new/2020/07/amazon-athena-adds-support-querying-apache-hudi-datasets-amazon-s3-based-data-lake/[11] 宣布支持查询Hudi表: https://aws.amazon.com/about-aws/whats-new/2020/09/amazon-redshift-spectrum-adds-support-for-querying-open-source-apache-hudi-and-delta-lake/[12] Amazon EMR中的Apache Hudi: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hudi-work-with-dataset.html