
详解超强 ResNet 变体 NFNet:抛弃归一化后,性能却达到了最强!

极市导读
本文从模型结构到训练策略,以及实验结果出发,详解了DeepMind之前提出的不需要归一化的深度学习模型NFNet。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 NFNet:无需 BN 的 ResNet 变体
(来自 DeepMind)
1 NFNet 论文解读
1.1 背景:Batch Norm 的优点
1.2 背景:Batch Norm 的缺点以及 Normalizer-Free 的 ResNet 模型
1.3 去掉 Batch Norm 的网络
1.4 自适应梯度裁剪
1.5 自适应梯度裁剪的消融实验结果
1.6 NFNet 模型架构改进
1.7 NFNet 实验结果
1.8 NFNet 的大规模预训练
太长不看版
从上古时期一直到今天,Batch Norm (BN) 一直都是视觉骨干架构里面很重要的一个环节。BN 使得研究人员可以训练更深的网络,并在训练集和测试集上实现更高的精度。Batch Norm 还可以平滑 Loss Landscape[1],使得我们可以在更大的 Batch Size 和学习率实现稳定训练,具有正则化效果[2]。
但是,BN 也有一些不理想的特性,比如依赖于 Batch Size,引入了模型在 training 期间和 inference 期间的行为差异等等。
本文提出一种不含 BN 的神经网络模型 NFNet,在当时超越了 EfficientNet 系列,如下图1所示。本文还提出一种自适应梯度裁剪用以拉大 Batch Size 的同时保持训练的稳定,来支持 Large Batch 的训练。
1 NFNet 视觉大模型:无需 BN 的 ResNet 变体,以及匹敌 ViT 性能的大规模预训练
论文名称:High-Performance Large-Scale Image Recognition Without Normalization (ICML 2021)
论文地址:
https://arxiv.org/pdf/2102.06171.pdf
1.1 背景:Batch Norm 的优点
计算机视觉中很多 Backbone 模型是经过了 Batch Norm[3]的训练的 ResNet 的变体。这两种架构的结合使得研究人员可以训练更深的网络,并在训练集和测试集上实现更高的精度。Batch Norm 还可以平滑 Loss Landscape[1],使得我们可以在更大的 Batch Size 和学习率实现稳定训练,具有正则化效果[2]。
总结 Batch Norm 具有4个主要的优点:
-
Batch Norm 缩小了 Residual Branch 的幅值: 当把 BN 放置在残差分支上时,减少了在模型训练初始化时残差分支上激活的比例。这会使网络的特征更多地偏向 Shortcut 这条路径,也就确保了网络在训练早期具有良好的梯度,从而便于实现高效的优化。 -
Batch Norm 消除了 mean-shift: ReLU 或 GELU 等激活函数不是对称的,具有非零的平均激活值。这就使得即使输入特征之间的内积接近于零,非线性激活值通常也是很大的正数。随着网络深度的增加,这个问题也变得更加严重,给激活值带来了一个 mean-shift,可能导致模型在初始化时对所有输入图片的预测结果都为相同的标签。Batch Norm 消除了 mean-shift,因为可以确保每个 channel 的平均激活值为零。 -
Batch Norm 有正则化效果: 因为一个 Batch 中的噪声是在训练数据的子集上计算的,因此 BN 也可以扮演正则化器的角色增强测试集的准确性。 -
Batch Norm 允许较大 Batch 的训练: Batch Norm 可以平滑 Loss Landscape,这可以增加模型的最大稳定学习率。虽然 large-batch training 没有在给定 Epoch 数的限制下实现更好的测试集精度,但是它能够以较少的参数更新次数的条件下实现给定的测试集精度。
1.2 背景:Batch Norm 的缺点以及 Normalizer-Free 的 ResNet 模型
但是,Batch Norm 具有3个显着的实际缺点:
-
Batch Norm 会产生内存开销,并显著增加某些网络中计算梯度所需的时间。 -
Batch Norm 引入了模型在 training 期间和 inference 期间的行为差异。 -
Batch Norm 打破了小 Batch 中训练示例之间的独立性。
第3个缺点有一系列负面后果:
-
带有 Batch Norm 的网络通常难以在不同的硬件上精确复制,尤其是在分布式训练期间,Batch Norm 通常是细微实现错误的原因。 -
Batch Norm 不能用于某些任务,因为 Batch 中训练 instance 之间的交互使网络能够 "欺骗" 某些损失函数。比如,在对比学习任务[4][5]中,BN 需要特别注意防止信息泄漏。这也是序列建模任务的主要问题,它驱使 Transformer 这样的语言模型使用 Layer Norm 的替代品。 -
如果在训练期间某个 Batch 的数据存在着较大的方差,Batch Norm 网络的性能也会下降。BN 的性能对于 Batch Size 的大小很敏感,当 Batch Size 太小时,Batch Size 网络的表现不佳,这限制了我们在有限硬件上训练的最大模型的尺寸。
因此,从这个角度来看,尽管 BN 层使得深度学习社区近年来取得了可观的收益,但是从长远来看,可能会阻碍长远的发展。目前已有一些替代 BN 的归一化层,比如 Layer Normalization[6],Group Normalization[7],但这些替代方案通常可以实现较差的测试精度并引入他们自己的缺点,例如推理的额外计算成本。
近年来出现了两个有前途的研究课题:其一是研究 BN 对于训练的好处的起源[1][2][8]。其二是旨在训练无归一化层的 ResNet,并实现具有竞争力的精度[9][10][11][12][13]。
1.3 去掉 Batch Norm 的网络
许多无归一化层的 ResNet 工作的一个关键做法是:可以通过抑制残差分支上的特征值的比例来训练非常深的 ResNet 模型,而无需进行归一化。实现这一点的最简单方法是在每个残差分支的末尾引入一个可学习的标量,初始化为0[14][12]。但是只有此技巧不足以在具有挑战性的 ImageNet 上获得有竞争力的测试精度。另一项工作表明,ReLU 激活函数引入了 "mean shift",这导致随着网络深度的增加,不同训练示例的激活值变得越来越相关。[10]提出 Normalizer-Free ResNet,通过 Scaled Weight Standardization 技术来去掉 "mean shift"。这种技术将卷积层重新参数化为

其中, 代表扇入系数。
ReLU 激活函数也由非线性特定标量增益 来缩放, 这确保了激活函数和 BN 层的组合保持方差不变, 对于 ReLU 激活函数有 。
这里证明下这个结论
待证明: , 则:
证:
因为有 , 因此需要分别计算 和 。
的计算: 因为 , 因此有 。基于此: 。 的计算: 因此有 证毕。
以上结论说明:对于 ReLU 激活函数有 , 即对于正态分布 输 激活函数输出的方差是 。
通过额外正则化比如 Dropout 或者 Stochastic Depth,在 Batch Size 为1024时,无需归一化的模型在 ImageNet 上匹配了带有 Batch Norm 的 ResNet 的性能,甚至在小 Batch Size 时表现更好,但它们在大 Batch 下表现出不稳定。
本文 NFNet 这个模型的设计基于 NF-ResNets[10],是一种 Normalizer-Free 的 ResNet。NF-ResNets 每个 Block 内部的表达式可以写为:

其中, 代表第 个残差块的输入, 代表第 个残差块内部的操作。函数 在初始化时保证了方差的不变性: 。
标量 为每个残差块之后激活的方差增加的速率并且通常设置为一个小值, 比如0.2。标量 是通过预测输入到第 个残差块的标准差 来确定的, 其中
1.4 自适应梯度裁剪
为了扩大训练的 Batch Size, 作者使用了梯度裁剪 (gradient clipping) 策略。梯度裁剪策略也允许使用更大的学习率, 以加快收玫过程。对于梯度向量 , 其中 是损失函数, 是参数向量, 标准的梯度裁剪算法在更新参数之前裁剪梯度为:
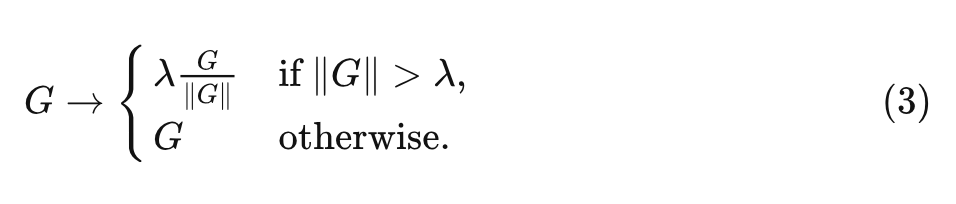
式中,裁剪阈值 是一个要调整的超参数。根据经验,作者发现虽然这种裁剪算法能够以比以前更高的 Batch Size 进行训练,但训练稳定性对裁剪阈值的选择非常敏感,需要在改变深度、Batch Size 或学习率时进行细粒度的调整。
为了解决这个问题,本文提出自适应梯度裁剪 (Adaptive Gradient Clipping, AGC)。
假设 为第 层的参数矩阵, 为对应的权重矩阵。
, 其中 代表 Frobenius 范数。
AGC 算法的动机是通过梯度 与权值 的范数之比 来作为一种简单的度量, 即梯度下降一步可以改变多少比例的权重。比如, 如果在没有动量的情况下使用梯度下降进行训练, 则 , 其中 是学习率。
对于 AGC 算法, 第 层的每个梯度 被裁剪为:
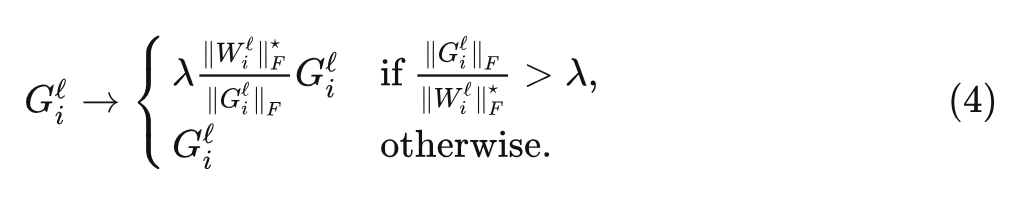
式中, 是裁剪阈值, 并定义 , 这可以防止零初始化的参数总是将它们的梯度裁剪为零。注意到最优的裁剪阈值 可能取决于优化器的选择、学习率和 Batch Size。根据经验,作者发现对于较大的 Batch Size, 应该更小。
1.5 自适应梯度裁剪的消融实验结果
为了测试 AGC 的效果,作者对 ImageNet 上对 NF-ResNet-50 和 NF-ResNet-200 进行了实验,使用 SGD 和 Nesterov 动量在 256 到 4096 之间的 Batch Size 范围内进行 90 个 Epochs 的训练。对 Batch Size 为 256 使用 0.1 的基本学习率,该学习率随着 Batch Size 进行线性缩放。作者考虑一系列的 λ\lambda\lambda 值 [0.01, 0.02, 0.04, 0.08, 0.16]。
如下图 2(a) 所示为 AGC 可以有效地将 NF-ResNets 扩展到更大的 Batch Size。图 2(b) 所示是不同裁剪阈值 λ\lambda\lambda 的性能且当 Batch Size 很大时就需要更小的裁剪阈值。
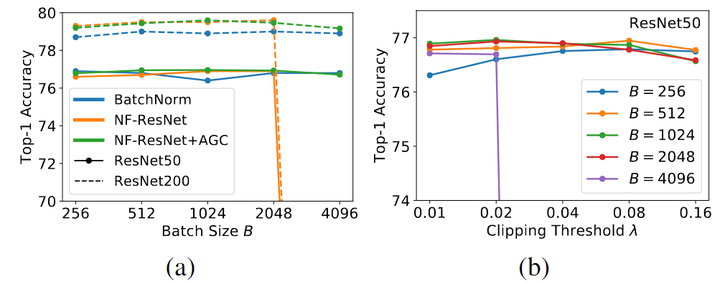
本文又通过一些消融实验发现,除了最终的线性层之外,将 AGC 应用于其他所有层比较好,因此后续就按照这种做法。
1.6 NFNet 模型架构改进
在模型设计的过程中,可以有多重度量的范式:
-
理论 FLOPs -
目标设备上的 inference latency -
加速器上的 training latency
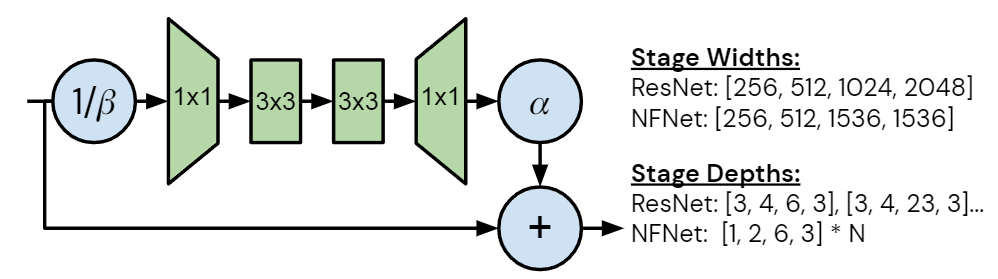
每个度量的性质将产生不同的设计要求,本文中作者专注于加速器上的 training latency。未来的加速器可能能够利用潜在的训练速度,开发在当前硬件上提高训练速度的模型将有助于加速研究。作者注意到 GPU 和 TPU 等加速器倾向于密集计算,虽然这两个平台之间存在差异,但为一个设备设计的模型很可能在另一个设备上快速训练。如图3所示是 NFNet bottleneck block design 的改进和不同,图4是细节架构。作者从具有 GELU 激活函数的 SE-ResNeXt-D 模型开始,因为发现它是 Normalizer-Free 的不错的基线。然后,作者做了几处改进:
将 3×3 卷积的组宽度设置为128: 较小的组宽度减少了理论FLOPs,但计算密度的降低意味着在许多现代加速器上,没有实现实际的加速。
深度缩放模式: 作者注意到 ResNet 的默认深度缩放模式 (例如从 ResNet50 中增加深度以构建 ResNet101 或 ResNet200 的方法) 是不均匀地增加第2和3个 Stage 的层数,同时保持第1和4个 Stage 的层数不变。作者发现这种策略是次优的。早期阶段的层以更高的分辨率运行,需要更多的内存和计算,并且倾向于学习一般性的特征。而后期的层以较低分辨率运行,包含大部分模型的参数,并学习更多特定任务相关的特征。但是,在早期阶段过于简约可能会损害性能,因为模型需要足够的容量来提取良好的局部特征。最小的模型 NFNet-F0 的各个 Stage 的层数是 [1, 2, 6, 3]。
宽度模式: 作者考虑了 ResNet 中的默认宽度模式,其中第1个 Stage 有256个 channel,在随后的每个 Stage 都会翻倍,得到的 channel 数分别为 [256, 512, 1024, 2048]。作者发现只有 [256, 512, 1536, 1536] 这一个选择优于默认值,这种深度的模式旨在增加第三阶段的容量,同时在第二阶段略微降低容量,且可以大致保持训练速度。作者发现第3阶段是增加容量的最佳位置,且假设这是因为这个阶段足够深,有较大的感受野,同时具有比最终阶段稍高的分辨率。
缩放策略 (如何把模型做大): 作者使用上述固定宽度、同时缩放深度以及缩放训练分辨率,使得每个变体的训练速度大约是其前面更小的模型的约一半。同时,作者以稍高的分辨率进行推理,选择的分辨率使得推理速度大约是训练速度的 33%。
正则化强度: 作者还发现,随着模型容量的增加,增加正则化强度有帮助。但是,修改权重衰减或 stochastic depth rate 并不有效,而修改 Dropout 比较有效。因为 NFNet 模型模型缺乏 BN 带来的隐式正则化,而如果再缺乏显式的正则化作用就会导致过拟合。
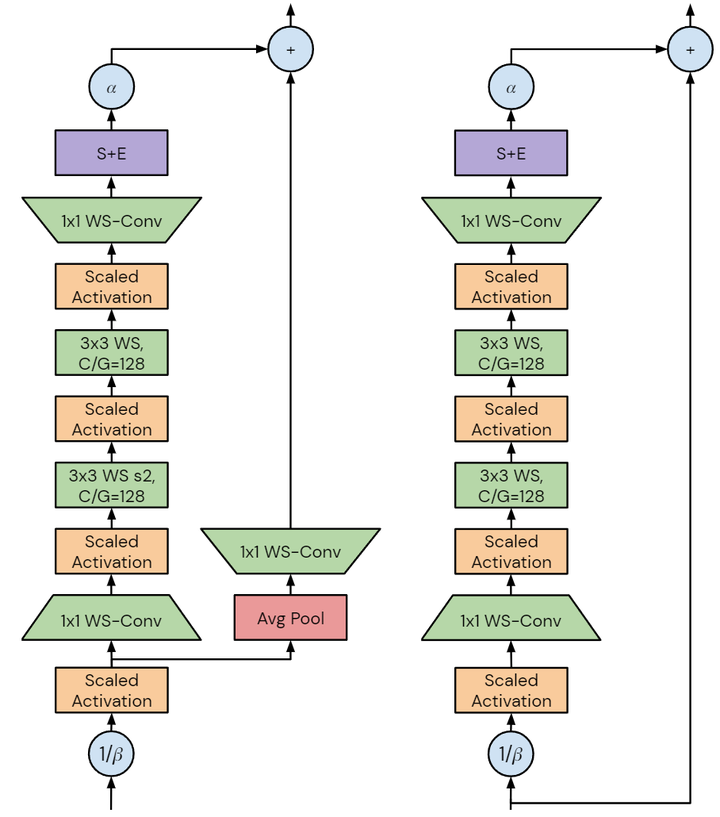
最后,再来总结下 NFNet 的 training recipe:
-
将 Normalizer-Free 模型的策略应用于 SE-ResNeXt-D。 -
修改宽度模式和深度缩放模式,以及第2个空间卷积。 -
除了分类器层的线性权重外,将 AGC 应用于每个参数。 -
强正则化和数据增强。
1.7 NFNet 实验结果
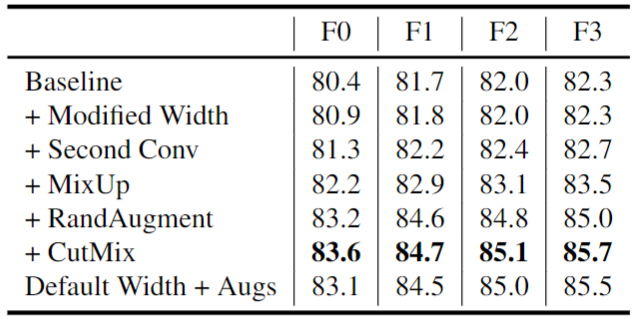
作者在 ImageNet 上训练 NFNet 模型,Batch Size 为 4096,训练300 Epochs,使用 Nesterov's Momentum,momentum coefficient 是 0.9,学习率在5个 Epoch 内,线性地从0增加到1.6。从下图5的前3行中,可以看到本文的方法都可以使得性能略有提高,而训练延迟仅略有变化。另外,数据增强也显着提高了性能。
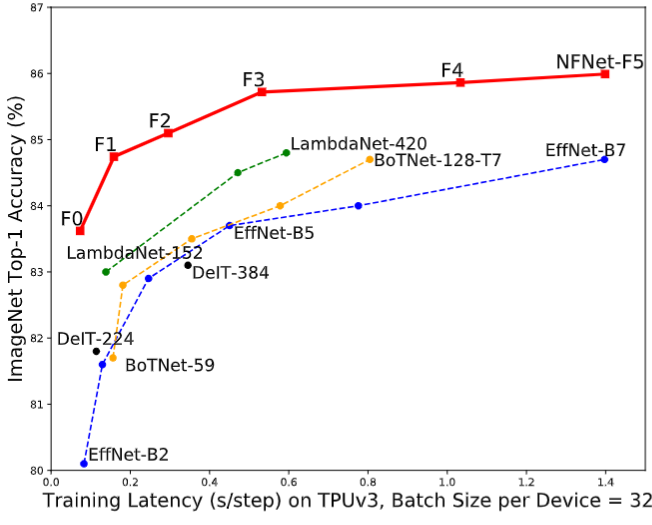
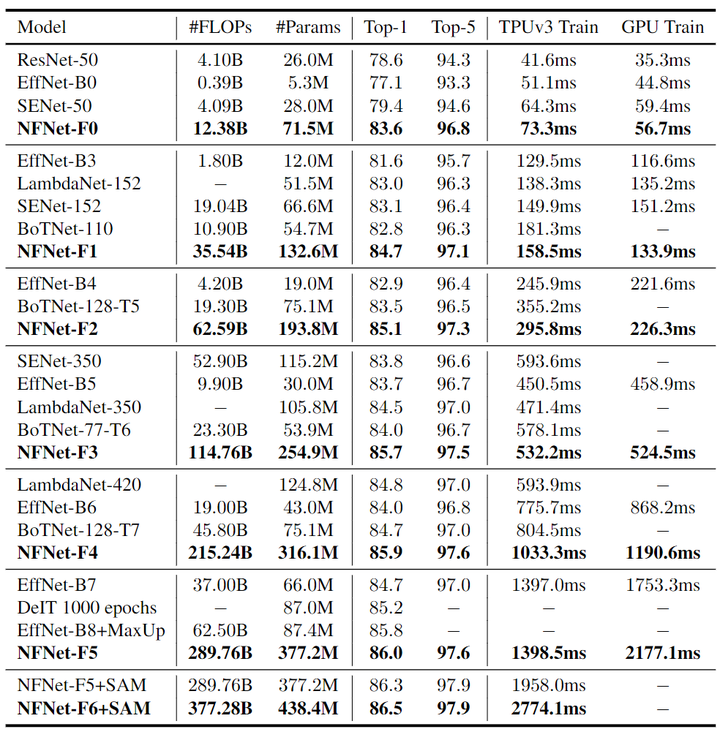
作者在下图6中提供了6个 NFNet 模型变体 NFNet-F0 到 F5 的大小、训练延迟 (TPUv3 和 V100) 和 ImageNet 精度的详细比较,以及与其他具有相似训练延迟的模型的比较。NFNet-F5 模型达到了 86.0% 的 Top-1 精度,比 EfficientNet-B8 小幅提升。NFNet-F1 模型的性能与 84.7% 的 EfficientNet-B7 相当,同时训练速度快 8.7 倍。
1.8 NFNet 的大规模预训练
NFNet 由于不含 BN 带来的隐式正则化效果,除非显式正则化,否则对于像 ImageNet 这样的数据集往往会过拟合。但是当在极大规模的数据集上进行预训练时,这种正则化可能不仅是不必要的,而且对性能有害,降低了模型将其全部容量投入到训练集的能力。
基于这一点,作者假设 Normalizer-Free 的模型天然适用大规模预训练,及其后续的迁移学习,并在 300 million labeled images 数据集上进行预训练。
预训练的做法是:对一系列带 BN 的 ResNets 和 NF-ResNets 预训练10 个 Epochs,然后同时使用 Batch Size 为2048,和 0.1 的小学习率同时在 ImageNet 上微调所有层,输入图像分辨率范围为 [224, 320, 384]。结果如图7所示,Normalizer-Free 网络在每种情况下都优于其 Batch-Normalized 对应模型,说明在迁移学习机制中,去除 BN 可以直接有利于最终性能。
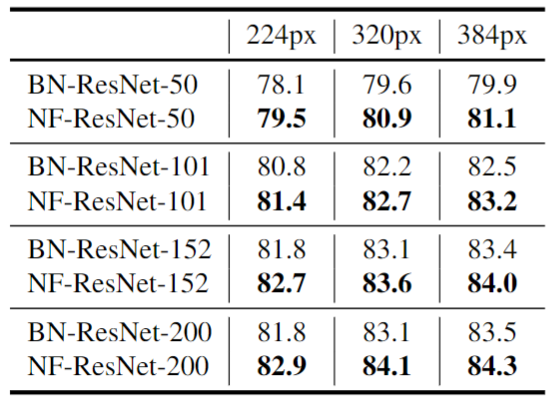
作者又使用 NFNet 模型进行了相同的实验,预训练的模型是 NFNet-F4 和一个稍微宽点的变体 NFNet-F4+。经过 20 个 epoch 的预训练,NFNet-F4+ 获得了 89.2% 的 ImageNet Top-1 精度。这是在当时使用迁移学习实现的最高精度。
参考
-
^abcHow Does Batch Normalization Help Optimization -
^abcTowards Understanding Regularization in Batch Normalization -
^Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift -
^A Simple Framework for Contrastive Learning of Visual Representations -
^Momentum Contrast for Unsupervised Visual Representation Learning -
^Layer Normalization -
^Group Normalization -
^Understanding Batch Normalization -
^Batch normalization biases residual blocks towards the identity function in deep networks -
^abcCharacterizing signal propagation to close the performance gap in unnormalized resnets -
^Is normalization indispensable for training deep neural network -
^abFixup Initialization: Residual Learning Without Normalization -
^How to Start Training: The Effect of Initialization and Architecture -
^Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour -
^Normalization Propagation: A Parametric Technique for Removing Internal Covariate Shift in Deep Networks -
^MetaFormer Baselines for Vision
公众号后台回复“极市直播”获取100+期极市技术直播回放+PPT
极市干货

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
