
深入解读SQL优化中的执行计划
数据库的执行计划是SQL优化的最重要手段,执行计划怎么来的、包含什么内容、我们应该关注哪些点,这些是需要我们掌握的,基于这些知识再去理解SQL优化将更加容易。
本文由腾讯云数据库高级架构师何敏带来TDSQL PostgreSQL执行计划详解,以下为分享实录:
在了解PostgreSQL执行计划之前,需要先知道执行计划由来。TDSQL PostgreSQL版任何查询都会经过语法和语义解析,生成查询表达式树,也就是常用查询数,解析器会去解析语法,分析器会把语法对应对象进行展开,通过重写器对规则进行重写,最后生成查询数。

根据查询树执行器经过查询再进行预处理,找出最小代价路径,最终创建出计划树。再把查询计划交由执行器进行执行。最终执行完成会把结果返回给前端应用。这些操作都是在每个连接对应Backend进程去进行处理。执行器在执行时,会去访问共享内存,内存没有数据,则从磁盘读取。最终将查询的结果缓存在数据库中,逐步输出给用户进程。
进程会涉及到例如Work memory、temp buffer等进程级内存,可以通过我们的Explain命令来查看执行计划,对不合理的资源进行调整,提高SQL执行效率。在SQL前面加上Explain,就可以直接看到执行计划。不管是在pgadmin还是其它工具都可以简单进行查看。
我们的执行计划有几个特点:首先查询规划是以规划为节点的树形结构,以查询的一些路径作为树形结构,树最底层节点是扫描节点,去扫描表中原始行数。不同表也有不同扫描类型,比如顺序扫描或索引扫描、位图索引扫描。也有非表列源,比如说Values子句。还有查询,可能需要关联、聚合、排序以便操作,同时也会在扫描节点上增加节点进行操作提示以及消耗。Expain输出总是以每个树节点显示一行,内容是基本节点类型和执行节点的消耗评估。可能会出现同级别节点,从汇总行节点缩进显示其它属性。第一行一般都是我们汇总的消耗,这个值是越小越好。

在看一个执行计划,我们创建一个测试表,插入1万条数据做分析后,可以看到它的执行计划,这个执行计划很简单,全面扫描它只有一行。执行计划我们从左到右去看,先是评估开始的消耗,这里因为没有别的步骤,所以这个步骤是从0开始,然后是一个总消耗评估。
Rows是输出的行数,它是一个评估结果;然后是每一行的平均字节数,这是一个评估结果,这个评估结果依赖于pg_stats和pg_statistic统计信息。
那么我们怎么去看执行计划呢?就是上级节点的消耗,其中包含了其子节点的消耗,这个消耗值反映在规划器评估这个操作需要的代价。一般这个消耗不包括将数据传输到客户端,只是在数据库后台的执行代价。评估的行数不是执行和扫描节点查询的节点数量,而是返回的数量。同时消耗它不是一个秒的,它是我们规划器的一个参数。Cost是描述一个执行计划代价是多少,而不是具体时间。
代价评估的一些基准值一般会关注哪几个参数?seq_page_cost,即扫描一个块需要的消耗,我们默认为是1,而随机扫描random_page我们默认为是4,这个在优化的环节需要进行优化,比如说现在使用SSD,随机页的访问效率肯定比其它的磁盘更快,而这里值就可以改为1。另外就是cpu_tuple_cost,我们CPU去扫描一个块里具体行数,一行大概0.01的消耗。索引是cpu_index_tuple_cost,0.005的消耗。
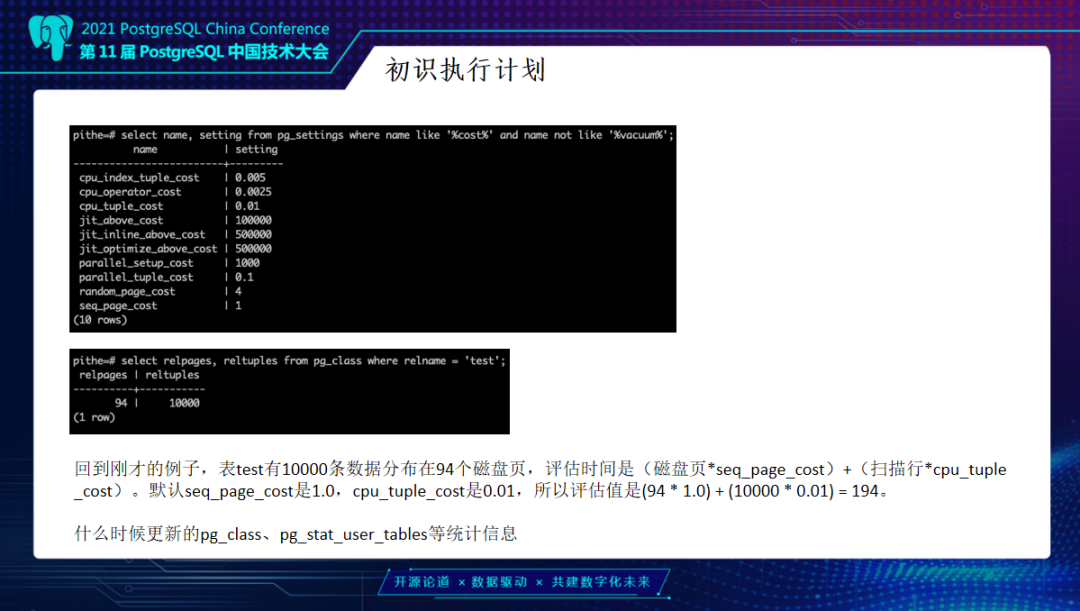
举个例子,新建Test表有一万行,它分配了94个页。而根据刚刚执行计划可以大概估算消耗:磁盘页乘顺序扫描的Cost,加上扫描行数。这个值就是94个页乘以1,加上1万行乘以0.01的消耗就是194。
那什么时候去更新pg_class以及pg_stat_user_tables的统计信息?它分为两个部分,一部分主要还是通过analyze以及部分DDL语句去触发更新统计信息。所以执行计划准确与否和统计信息也很有关联。这里加上条件,比如说Where Id小于1000,会去增加一个筛选条件。这样扫描的同时它会去增加损耗,比如扫描的行数不变,但是增加了CPU的计算比较时间,就变为219。
执行计划最底层是表的扫描,而扫描又分为两种方式,全表扫描以及索引扫描。全表扫描顾名思义去整个表上扫描。就算是有些表加了索引,它也不一定会走索引扫描,如果说满足条件的数据集比较大,索引扫描代价比全表扫描更大,它就会走全表扫描。如前面所说,扫描全表,这个时候重新扫描,会先走索引,再走对应的块,这个代价会比走全表扫描更慢。
另一个问题是索引扫描Index Scan。在上面的测试表对查询列建一个索引,举例查询条件是小于1000这个值,cost减少还不够直观,如果条件是小于10之类小数据量查询,索引效果更好,直接走Index Scan。但如果查询条件筛选率不够高,查询会先走索引扫描,再重新扫描行,扫描后他会去判断每一个行的条件,Cost可能相应就变更高。在优化的时候,尤其要去关注这一点,一定要关注索引的筛选率。
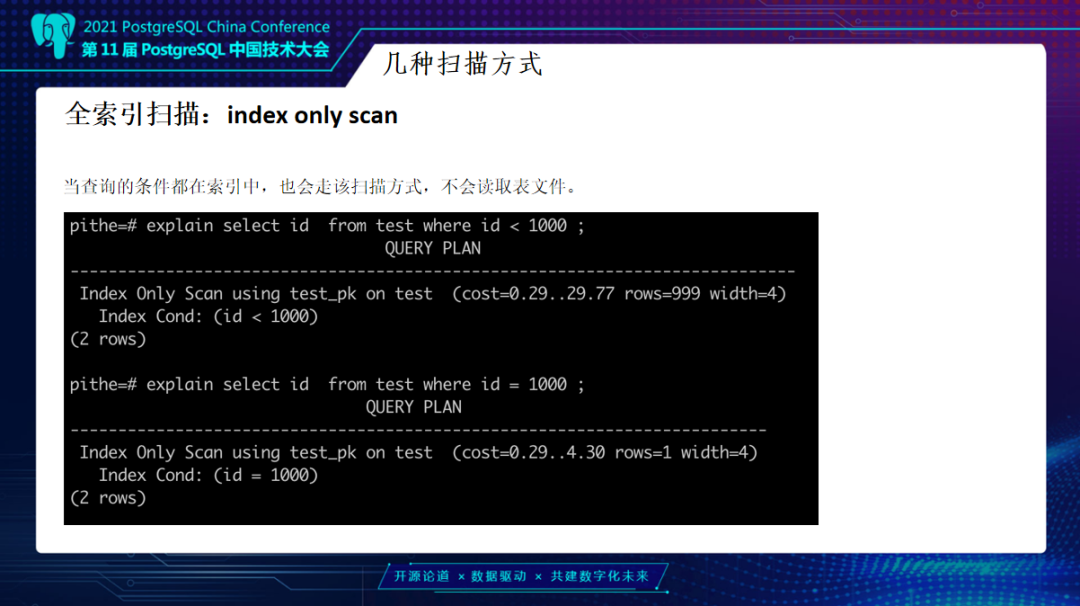
索引扫描里还有一个Index Only Scan,也就是投影列、查询条件都在索引里面,它就会走一个Index Only Scan,不会再去读其它具体的行值,扫描完索引之后就返回,效率非常高。
还有一种扫描方式是位图扫描,在PG里没有位图索引,但是它是有位图扫描的,一般是在on、and或in子句里面去走。举个例子,上面查询ID小于1000,同时ID要大于9000,这时候它会先做两次索引扫描。扫描时它不会去读具体数据,会先去做一个Bitmap Scan,之后我们的条件是Or,会先做一个聚集后再去做Check,看一下具体实现方式。它是先去启动时间两个Bitmap Scan总和,因为是具体扫描会有扫描时间,所以这个组合会花费大量时间。同时Index Scan输出的是Tuple,先扫描索引块,得到对应ctid再去扫描具体数据。如果一次只读一条索引项然后去判断行是否满足条件,一个PAGE可以多次访问。
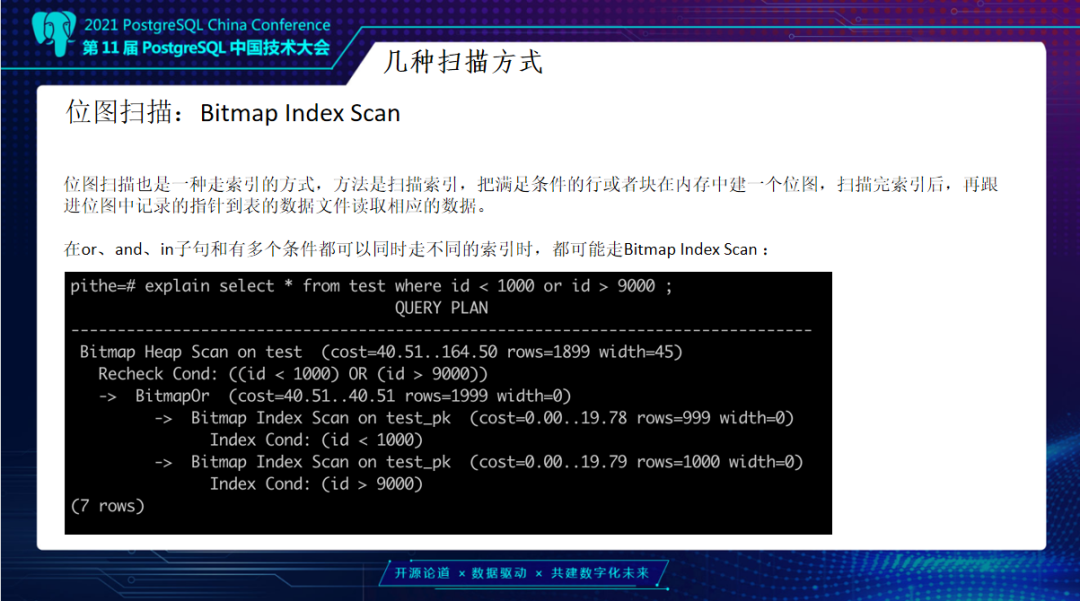
而Bitmap Scan会去输出所有满足条件的索引项,然后组合到一起做or等操作,最后才交给上一个节点Bitmap Heap Scan去扫描具体数据,由于会先去根据索引扫描的物理数据进行排序,一次性将块中满足条件索引项数据取出来。这样可以说一个块,一次扫描就扫描完了,可以想象这个效率是非常高的。
在底层的数据扫描完之后会去做表连接。连接方式一般在两表关联的时候才有连接可能。一般简单说自然选择、左连接、右连接等等。但具体的到数据库的执行计划里一般主要有hash join、nested loop、merge join。
Hash Join,它是以Hash方式来进行表连接,首先它确定是两个表里的大小,使用小表去建立Hash map,去扫描大表比较Hash值获取最终查询结果。我们示例中建立另外一张表Test1,并建一个索引进行两张表关联查询,当他们的T1的ID小于10,它Info相等,做一个关联查询。首先开始的时候,因为两个表大小一样,一张有索引,一张没有,会优先选择有索引的表去做一个Hash桶,另外一张表进行一个循环比较Hash值。如果说变一下条件把Test1表删除一部分数据,优化器会以Test1去做一个Hash表,Test表在上面去做驱动。
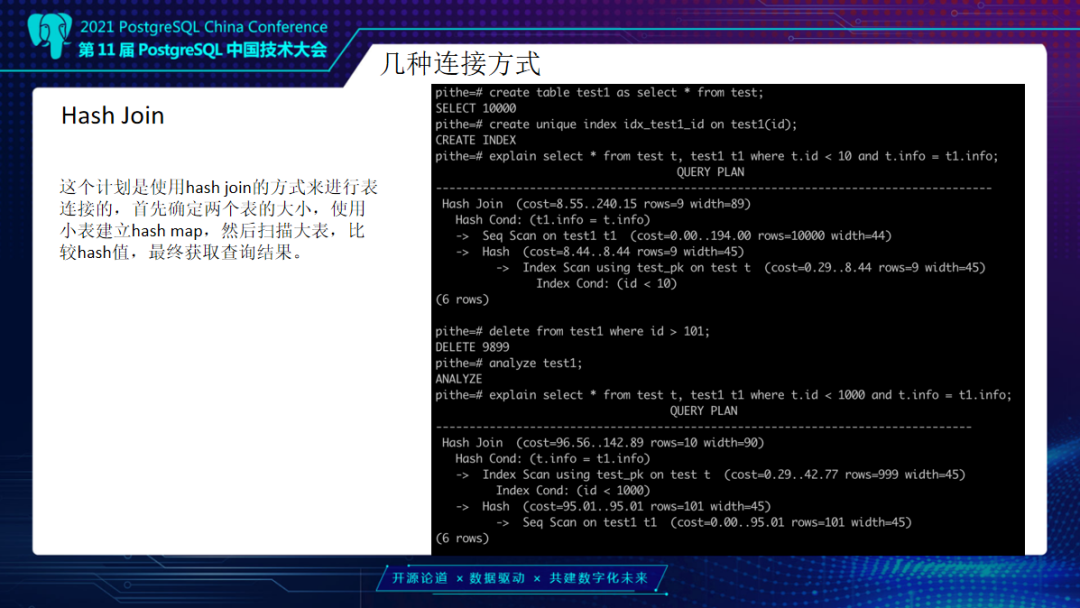
做一个简单梳理。Hash连接是在做大数据连接时非常有用的方式,就是在两个大表进行join。那么这里也是为什么PG在和MySQL比的时候,说它的分析能力要强一点的原因,因为我们的Hash join支持非常好。另外现在MySQL已经支持Hash了,但是还不是那么完善。
Hash它有个问题,如果Hash的小表也比较大,Hash表的结果非常大,你的内存放不下,这时就可能会写到你的磁盘中去,就会导致性能急剧下降。在这个时候就要提高work_mem。hash join的时间消耗是什么?我们的外层Cost请求,加上内层一个请求就可以了。
另外一个连接方式就是Nested Loop循环扫描,在这个扫描上写了两个循环去扫描。一般在优化的时候,特别是用PG数据库,要去重点看Nested Loop是不是合理。那么什么时候用Nested Loop呢?就是小表和大表进行关联的时候,小表作为驱动表,那大表作为下面的内层表会比较合理。
首先它会确定一个驱动表,另外是一个内层的表,驱动表每一行与它里面那张表进行一个查询,一个嵌套循环查询比较,代价非常高。就比如每次都是外层的表,乘以外面的条件消耗,这一看就比较大了。
像这种情况,每次扫描时,外层的表每次在驱动时它会去扫描层内层的表,这样效率非常低。而如果内层的表它结果集是相对固定的,那么就可以扫描一次把它做一个物化,下次再循环比较的时就不用再去查询里面的表,类似于Hash join。Hash join是做什么的呢?它前面也是一个Loop,只是把内存的表建立一个Hash表,这样去扫描就会快很多。Materialize就是这么一个优化的方向,这个也依赖于我们的work_mem。
最后一种连接方式叫Merge join,主要针对于数据量不是特别大的情况下,而且两个表如果结构相似,做好排序,这时反而会比散列连接会好一点。示例中原来是走了一个Nested Loop,我们把索引删除,它就去走了Merge join。一般对于这种数值比较效率还可以,因为排序数值效率是高一点。如果是字符串一类,走Merge join效率会更低。
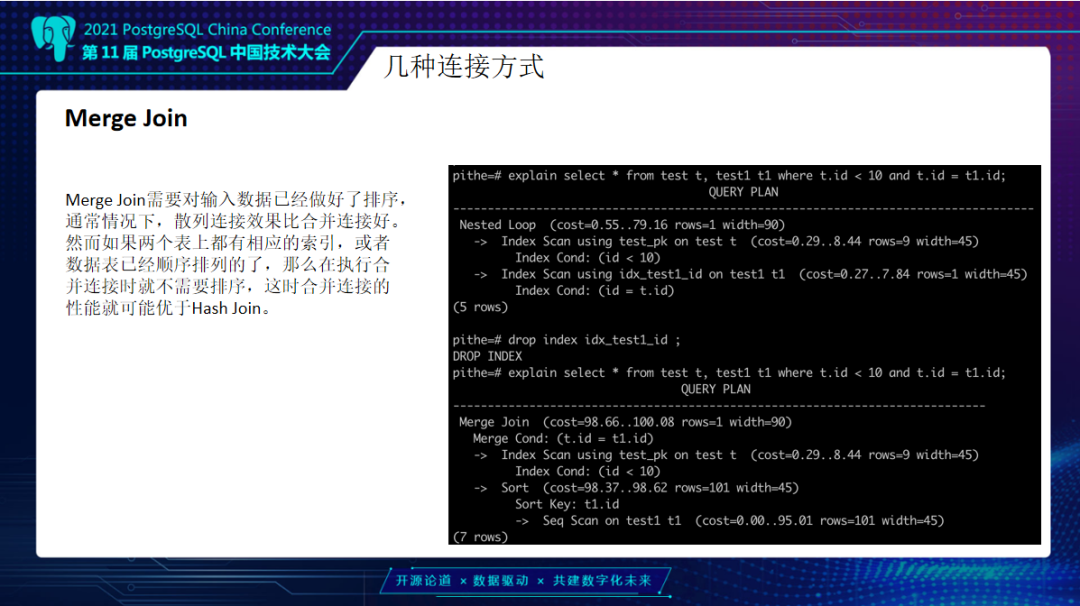
看一下具体的实现,它是先将两个表进行一个排序。Id 1等于1先比较完后,再去比较Id等于2时,就不会再去比较Id1等于1的位置块,会直接从另外一张表的2开始去比较。
做一个简单比较,Hash join是将一个小表做为一个内存表做Hash运算,将列数据根据hash值放到Hash行列表中,再从另外一张表去抽取记录做Hash运算找到匹配的值,一般是小表做Hash表。
Nested Loop是一张表读取数据,访问另外一张表做匹配。Nested Loop在关联表比较小的时候效率最高。小表做驱动,比如这个表只有百来行,而大表很大,循环100次查询,大表会进行索引扫描,相对会快很多。
Merge join如果数据做好了排序,而且是数字类型排序,Merge join可能反而比Hash要快。但一般来说如果数据量比较大,Hash基本会比Merge join更快。
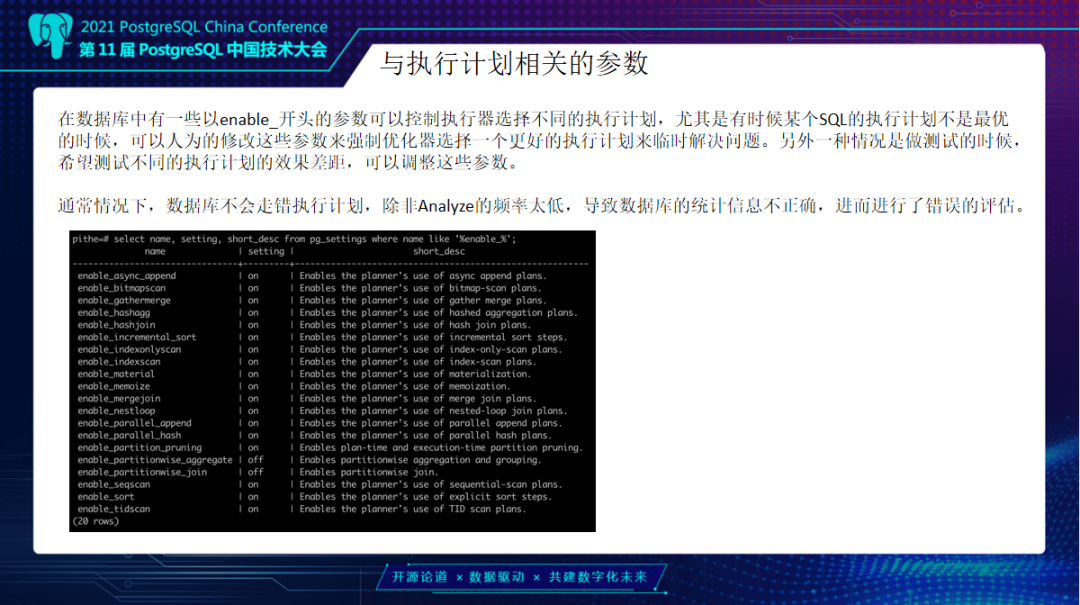
另外是关联相关参数一般以Enable开头。刚刚那几种连接Nested Loop、Merge join、Hash join、Bitmap Scan都是可以去控制的,参数可以是session级别控制。
查看执行计划首先是看扫描方式和连接方式,不论再怎么复杂,都是通过这两个进行组合。一般是看它在扫描和关联是不是合理的。这两个判断之后,再去看它的条件是不是合理,或需不需要改写。有了执行计划之外,在看具体执行时间,就要加上Explain Analyze来看具体执行时间。这里有一个不一样的点,在这里有了一个实际执行时间,这个时间是真实时间。可以很精确知道每一步花费时间。
在Analyze之外,还有一些其它参数,可以通过\H Explain的方式去查看详细的语法,有verbos显示具体执行日志,还有Cost消耗、Settings显示特殊设置,buffers内存的一些分配情况。wal、Timing时间,Summary,format输出的格式TXT或者xml、json。如果加上,它的显示信息会多很多。主要是buffers比较有用,显示说你申请了多少,现在多少磁盘块是要命中,多少是进行读取的。在第二次查询的时候,它的磁盘读取会变少,第一次读取是94块,第二次50块块。
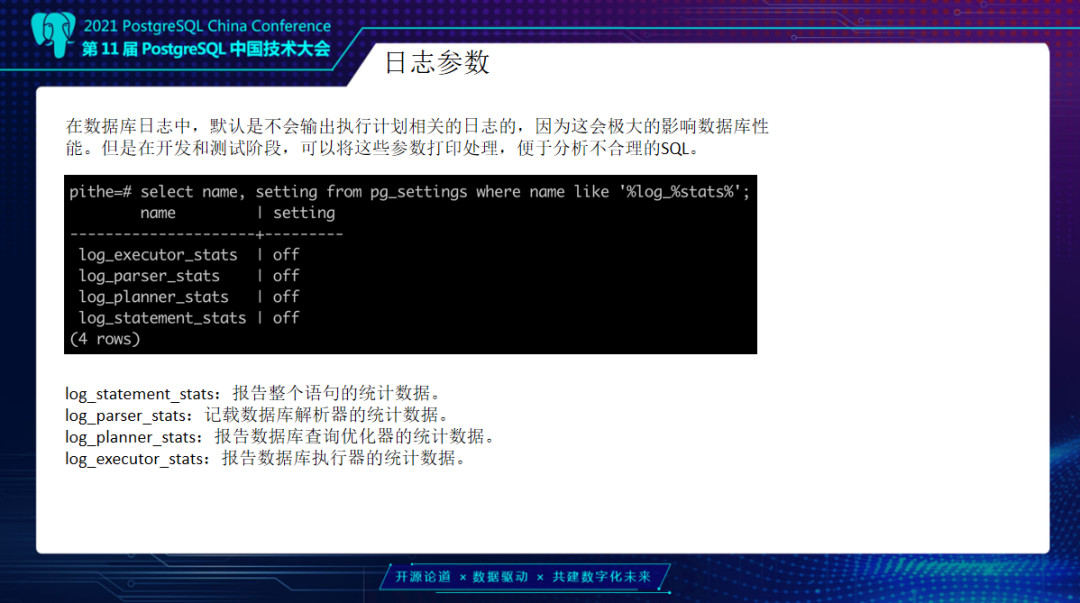
除了上述内容,还有一个日志参数。我们的log_planner_stats可以输出你的执行计划到日志文件中,Oracle的执行计划是从表里去看,而我们PG是没有的。那么怎么办?可以通过一些参数去控制,导到日志里来。就目前这个日志它是输入到运行日志里的,没有单独去进行记录。当然这个也是我们优化的一个方向。
通过设置这些参数,把这里日志打印出来,显示出执行计划,语法分析、语义分析、重写,这几个阶段它会显示出来。如果开启了执行计划状态,会把这些进行打印。
最后看执行计划之外,从执行计划去反推SQL优化方向。从最底层一个扫描去入手,要尽量走索引扫描。另外索引扫描这里有很多方式,就是看它是否是合理索引,要看类型是不是选择合理的。比如数字类型、字符串类型,我们选用gin索引,还是一些btree索引。PG默认是btree索引,但btree索引不是所有类型和操作符都会适用。另外还需要减少不必要的索引、避免单条SQL插入,要单条变为批量进行插入。
前面说执行计划表连接类型是不是正确合理,另外要从SQL本身进行入手,我们目的是为了减少它的消耗。如果SQL语句比较复杂,而扫描类型已经无法改动,那这时只能去改写SQL语句,尽量减少嵌套,减少子查询。还可以通过物化视图临时表,去做SQL拆分。

尽量把in语法用Exits方式做连接。另外还要注意一些类型的转换失真,在扫描时,如果它可以走索引扫描,结果走了全面扫描,可能是转换失真了,比如说一个in类型,结果输入是一个字符串类型,它有可能会转换失败,只能走全面扫描,不能索引。
另外从数据库参数来入手,就需要精确的统计信息,我们在生成执行计划时,可能autovacuum没有去执行,也可能统计信息落后,那么执行计划就是错误的。这时候就要对应表作为一个analyze。
最后就是干涉执行计划,干涉执行计划有两种方式,除了前面的enable几个参数,我们的pg_hint_plan插件也可以做一些Hint控制。还有一些新参数调整,例如调整work_mem、temp_buffers、shared_buffers等参数。还有一些连接池的使用,我们操作系统参数、硬件的性能参数调整等等。
其实往往数据库优化,除了这些以外,还有我们去看操作系统的一些硬件性能,比如CPU是不是Performance模式,磁盘调度方式是不是最优的,网卡Bond模式等其他参数。
﹀
﹀
﹀

开源数据库TDSQL PG版再升级:分区表性能提升超10倍

一文详解TDSQL PG版Oracle兼容性实践
↓↓点击阅读原文,了解更多优惠