
让你的模型acc更上一层楼:模型trick和数据方法总结

极市导读
本系列主要探究哪些模型trick和数据的方法可以大幅度让你的分类性能更上一层楼,本篇主要讲解了对于大的BatchSize下训练分类模型以及张航的Bag of Tricks for Image Classification with Convolutional Neural Networks中的一些方法以及自己实际使用的一些trick。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、前言
如何提升业务分类模型的性能,一直是个难题,毕竟没有99.999%的性能都会带来一定程度的风险,所以很多时候我们只能通过控制阈值来调整准召以达到想要的效果。本系列主要探究哪些模型trick和数据的方法可以大幅度让你的分类性能更上一层楼,不过要注意一点的是,tirck不一定是适用于不同的数据场景的,但是数据处理方法是普适的。
BatchSize&LARS
本篇文章主要是对于大的bs下训练分类模型的情况,如果bs比较小的可以忽略,直接看最后的结论就好了(这个系列以后的文章讲述的方法是通用的,无论bs大小都可以用)。
实验配置
模型:ResNet50 数据:ImageNet1k 环境:8xV100
BatchSize对精度的影响
所有的实验的超参都是统一的,warmup 5个epoch,训练90个epoch,StepLR进行衰减,学习率的设置和bs线性相关,公式为,优化器使用带有0.9的动量的SGD,baselr为0.1(如果采用Adam或者AdamW优化器的话,公式需要调整为),训练的数据增强只有RandomCropResize,RandomFlip,验证的数据增强为Resize和CenterCrop。
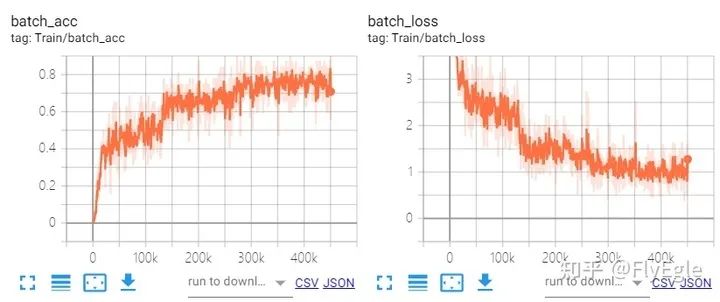
训练情况如下:
lr调整曲线如下:
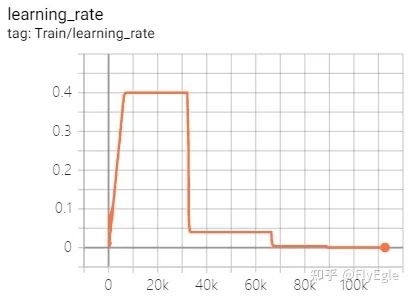
训练曲线如下:
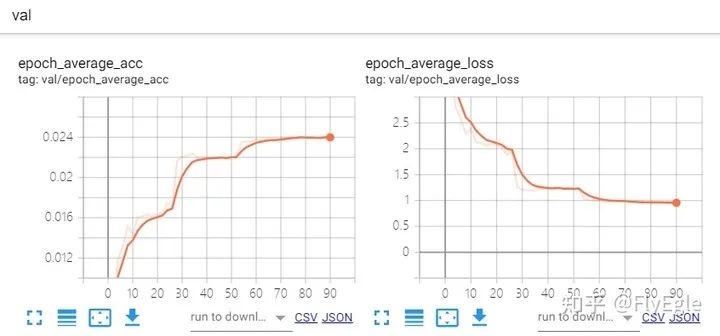
验证曲线如下:
我这里设计了4组对照实验,256, 1024, 2048和4096的batchsize,开了FP16也只能跑到了4096了。采用的是分布式训练,所以单张卡的bs就是bs = total_bs / ngpus_per_node。这里我没有使用跨卡bn,对于bs 64单卡来说理论上已经很大了,bn的作用是约束数据分布,64的bs已经可以表达一个分布的subset了,再大的bs还是同分布的,意义不大,跨卡bn的速度也更慢,所以大的bs基本可以忽略这个问题。但是对于检测的任务,跨卡bn还是有价值的,毕竟输入的分辨率大,单卡的bs比较小,一般4,8,16,这时候统计更大的bn会对模型收敛更好。
实验结果如下:
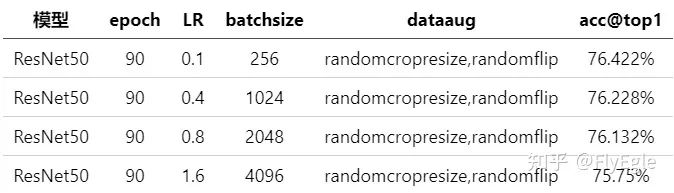
很明显可以看出来,当bs增加到4k的时候,acc下降了将近0.8%个点,1k的时候,下降了0.2%个点,所以,通常我们用大的bs训练的时候,是没办法达到最优的精度的。个人建议,使用1k的bs和0.4的学习率最优。
LARS(Layer-wise Adaptive Rate Scaling)
1. 理论分析
由于bs的增加,在同样的epoch的情况下,会使网络的weights更新迭代的次数变少,所以需要对LR随着bs的增加而线性增加,但是这样会导致上面我们看到的问题,过大的lr会导致最终的收敛不稳定,精度有所下降。
LARS的出发点则是各个层的更新参数使用的学习率应该根据自己的情况有所调整,而不是所有层使用相同的学习率,也就是每层有自己的local lr,所以有:
这里,表示的是第几层,表示的是超参数,这个超参数远小于1,表示每层会改变参数的confidence,局部学习率可以很方便的替换每层的全局学习率,参数的更新大小为:
与SGD联合使用的算法如下:

LARS代码如下:
class LARC(object):
def __init__(self, optimizer, trust_coefficient=0.02, clip=True, eps=1e-8):
self.optim = optimizer
self.trust_coefficient = trust_coefficient
self.eps = eps
self.clip = clip
def step(self):
with torch.no_grad():
weight_decays = []
for group in self.optim.param_groups:
# absorb weight decay control from optimizer
weight_decay = group['weight_decay'] if 'weight_decay' in group else 0
weight_decays.append(weight_decay)
group['weight_decay'] = 0
for p in group['params']:
if p.grad is None:
continue
param_norm = torch.norm(p.data)
grad_norm = torch.norm(p.grad.data)
if param_norm != 0 and grad_norm != 0:
# calculate adaptive lr + weight decay
adaptive_lr = self.trust_coefficient * (param_norm) / (
grad_norm + param_norm * weight_decay + self.eps)
# clip learning rate for LARC
if self.clip:
# calculation of adaptive_lr so that when multiplied by lr it equals `min(adaptive_lr, lr)`
adaptive_lr = min(adaptive_lr / group['lr'], 1)
p.grad.data += weight_decay * p.data
p.grad.data *= adaptive_lr
self.optim.step()
# return weight decay control to optimizer
for i, group in enumerate(self.optim.param_groups):
group['weight_decay'] = weight_decays[i]
这里有一个超参数,trust_coefficient,也就是公式里面所提到的, 这个参数对精度的影响比较大,实验部分我们会给出结论。
2. 实验结论
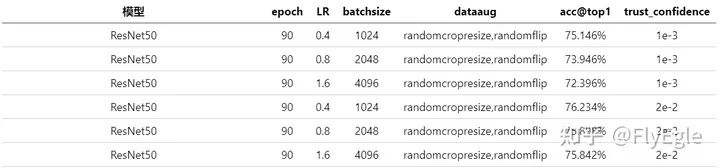
可以很明显发现,使用了LARS,设置turst_confidence为1e-3的情况下,有着明显的掉点,设置为2e-2的时候,在1k和4k的情况下,有着明显的提升,但是2k的情况下有所下降。
LARS一定程度上可以提升精度,但是强依赖超参,还是需要细致的调参训练。
结论
8卡进行分布式训练,使用1k的bs可以很好的平衡acc&speed。 LARS一定程度上可以提升精度,但是需要调参,做业务可以不用考虑,刷点的话要好好训练。
Bag of Tricks
主要是介绍张航的Bag of Tricks for Image Classification with Convolutional Neural Networks中的一些方法以及自己实际使用的一些trick。
ps: 文章比较长,不喜欢长文可以直接跳到结尾看结论。
使用大的batchsize训练会略微降低acc,可以使用lars进行一定程度的提升,但是需要进行适当的微调,对于业务来说,使用1k的batchsize比较合适。
实验配置
模型: ResNet50/ResNet50vd, CMT-tiny 数据: ImageNet1k & 业务数据 环境: 8xV100
CMT-tiny代码和文章看这里
ps: 简单的说明一下,由于部分实验是从实际的业务数据得到的结论,所以可能并不是完全适用于别的数据集,domain不同对应的方法也不尽相同。本文只是建议和参考,不能盲目的跟从。imagenet数据集的场景大部分是每个图片里面都会包含一个物体,也就是有主体存在的,我这边的业务数据的场景很多是理解性的,更加抽象,也更难。
Bag of Tricks
数据增强
朴素数据增强 通用且常用的数据增强有 random flip,colorjitter,random crop,基本上可以适用于任意的数据集,colorjitter注意一点是一般我们不给hue赋值。RandAug AutoAug系列之RandAug,相比autoaug的是和否的搜索策略,randaug通过概率的方法来进行搜索,对于大数据集的增益更强,迁移能力更好。实际使用的时候,直接用搜索好的imagnet的策略即可。 mixup & cutmix mixup和cutmix均在imagenet上有这不错的提升,实际使用发现,cutmix相比mixup的通用性更强,业务数据上mixup几乎没有任何的提升,cutmix会提高一点点。不过两者都会带来训练时间的开销, 因为都会导致简单的样本变难,需要更多的iter次数来update,除非0.1%的提升都很重要,不然个人觉得收益不高。在物体识别上,两者可以一起使用。公式如下:
\4. gaussianblur和gray这些方法,除非是数据集有这样的数据,不然实际意义不大,用不用都没啥影响。
实验结论:
20% imagenet数据集 & CMT-tiny
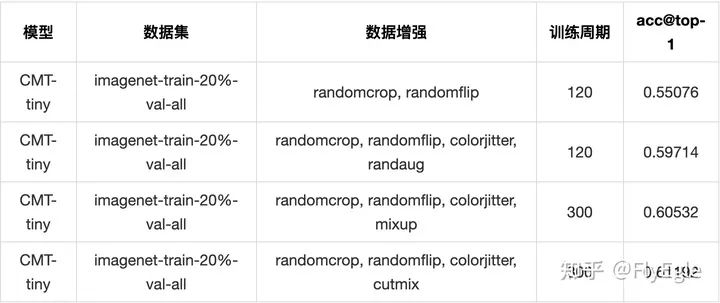
业务数据上(ResNet50) autoaug&randaug没有任何的提升(主要问题还是domain不同,搜出来的不适用),cutmix提升很小(适用于物体识别而不是内容理解)。
学习率衰减
warmup: 深度学习更新权重的计算公式为,如果bs过大,lr保持不变,会导致Weights更新的次数相对变少,最终的精度不高。所以要调整lr随着bs线性增加而增加,但是lr变大,会导致W更新过快,最终都接近于0,出现nan。所以需要进行warmup,在训练前几个epoch,按很小的LR(1e-6)线性增长为初始的LR后再进行decay。 LRdecay: 我们常用的LR decay方法一般是Step Decay,按照epoch或者iter的范围来进行线性衰减,对于SGD等优化器来说,效果稳定,精度高。进一步提升精度,可以使用CosineDecay,但是需要更长的训练周期。
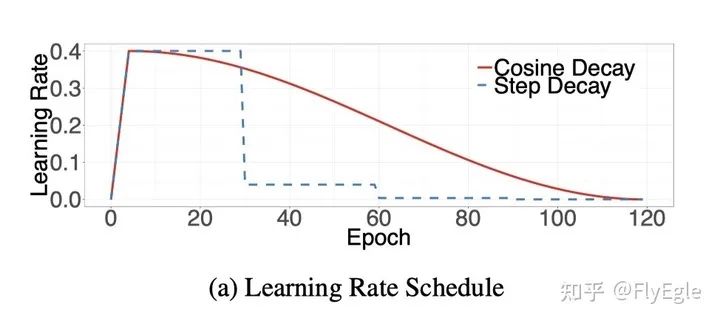
CosineDecay公式如下:
如果不计较训练时间,可以使用更暴力的方法,余弦退火算法(Cosine Annealing Decay), 公式如下:
这里的表示的是重启的序号,表示学习率,表示当前的epoch。
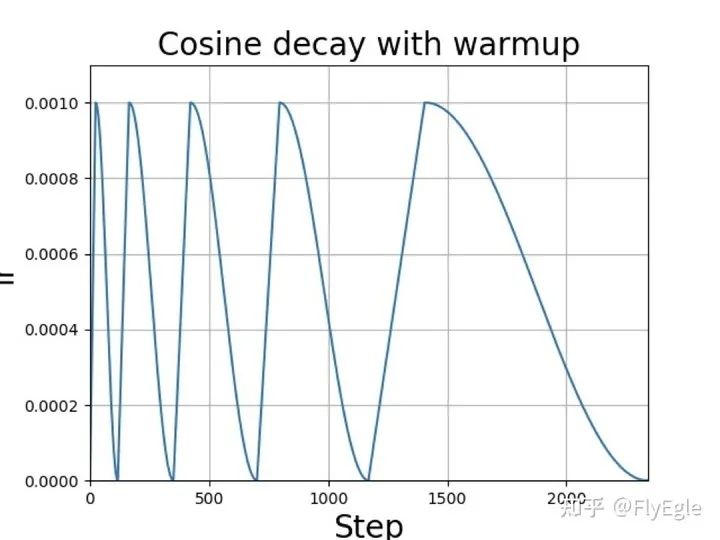
退火方法常用于图像复原等用于L1损失的算法,有着不错的性能表现。
个人常用的方法就是cosinedecay,比较喜欢最后的acc曲线像一条"穿天猴", 不过要相对多训练几k个iter,cosinedecay在最后的acc上升的比较快,前期的会比较缓慢。
跨卡同步bn&梯度累加
这两个方法均是针对卡的显存比较小,batchsize小(batchszie总数小于32)的情况。
SyncBN 虽然我们在训练的时候采用的是ddp,实际上就是数据并行训练,每个卡的batchnorm只会更新自己的数据,那么我们实际上得到的running_mean和running_std只是局部的而不是全局的,如果bs比较大,那么可以认为局部和全局的是同分布的,如果bs比较小,那么会存在偏差。所以需要SyncBN帮我们同步一下mean和std以及后向的更新。 GradAccumulate 梯度累加和同步BN机制并不相同,也并不冲突,同步BN可以用于任意的bs情况,只是大的bs下没必要用。跨卡bn则是为了解决小bs的问题所带来的性能问题,通过loss.backward的累加梯度来达到增大bs的效果,由于bn的存在只能近似不是完全等价。代码如下:
for idx, (images, target) in enumerate(train_loader):
images = images.cuda()
target = target.cuda()
outputs = model(images)
losses = criterion(outputs, target)
loss = loss/accumulation_steps
loss.backward()
if((i+1)%accumulation_steps) == 0:
optimizer.step()
optimizer.zero_grad()
backward是bp以及保存梯度,optimizer.step是更新weights,由于accumulation_steps,所以我们需要增加训练的迭代次数,也就是相应的训练更多的epoch。
标签平滑
LabelSmooth目前应该算是最通用的技术了 优点如下:
可以缓解训练数据中错误标签的影响; 防止模型过于自信,充当正则,提升泛华性。
但是有个缺点,使用LS后,输出的概率值会偏小一些,这会使得如果需要考虑recall和precision,卡阈值需要更加精细。代码如下:
class LabelSmoothingCrossEntropy(nn.Module):
"""
NLL loss with label smoothing.
"""
def __init__(self, smoothing=0.1):
"""
Constructor for the LabelSmoothing module.
:param smoothing: label smoothing factor
"""
super(LabelSmoothingCrossEntropy, self).__init__()
assert smoothing < 1.0
self.smoothing = smoothing
self.confidence = 1. - smoothing
def forward(self, x, target):
logprobs = F.log_softmax(x, dim=-1)
nll_loss = -logprobs.gather(dim=-1, index=target.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = self.confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
ResNet50-vd
ResNet50vd是由张航等人所提出的,相比于ResNet50,改进点如下:
头部的conv7x7改进为3个conv3x3,直接使用7x7会损失比较多的信息,用多个3x3来缓解。 每个stage的downsample,由 (1x1 s2)->(3x3)->(1x1)修改为(1x1)->(3x3 s2)->(1x1), 同时修改shortcut从(1x1 s2)为avgpool(2) + (1x1)。1x1+s2会造成信息损失,所以用3x3和avgpool来缓解。
实验结论:

上面的精度是我自己跑出来的比paper中的要低一些,不过paper里面用了蒸馏,相比于R50,提升了将近2个点,推理速度和FLOPs几乎没有影响,所以直接用这个来替换R50了,个人感觉还算不错,最近的业务模型都在用这个。代码和权重在git上,可以自行取用。
结论
LabelSmooth, CosineLR都可以用做是通用trick不依赖数据场景。 Mixup&cutmix,对数据场景有一定的依赖性,需要多次实验。 AutoAug,如果有能力去搜的话,就不用看我写的了,用就vans了。不具备搜的条件的话,如果domain和imagenet相差很多,那考虑用一下randaug,如果没效果,autoaug这个系列可以放弃。 bs比较小的情况,可以试试Sycnbn和梯度累加,要适当的增加迭代次数。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
