
Spring Boot 青睐的数据库连接池HikariCP为什么是史上最快的?
前言
现在已经有很多公司在使用HikariCP了,HikariCP还成为了SpringBoot默认的连接池,伴随着SpringBoot和微服务,HikariCP 必将迎来广泛的普及。
下面陈某带大家从源码角度分析一下HikariCP为什么能够被Spring Boot 青睐,文章目录如下:
零、类图和流程图
开始前先来了解下HikariCP获取一个连接时类间的交互流程,方便下面详细流程的阅读。
获取连接时的类间交互:
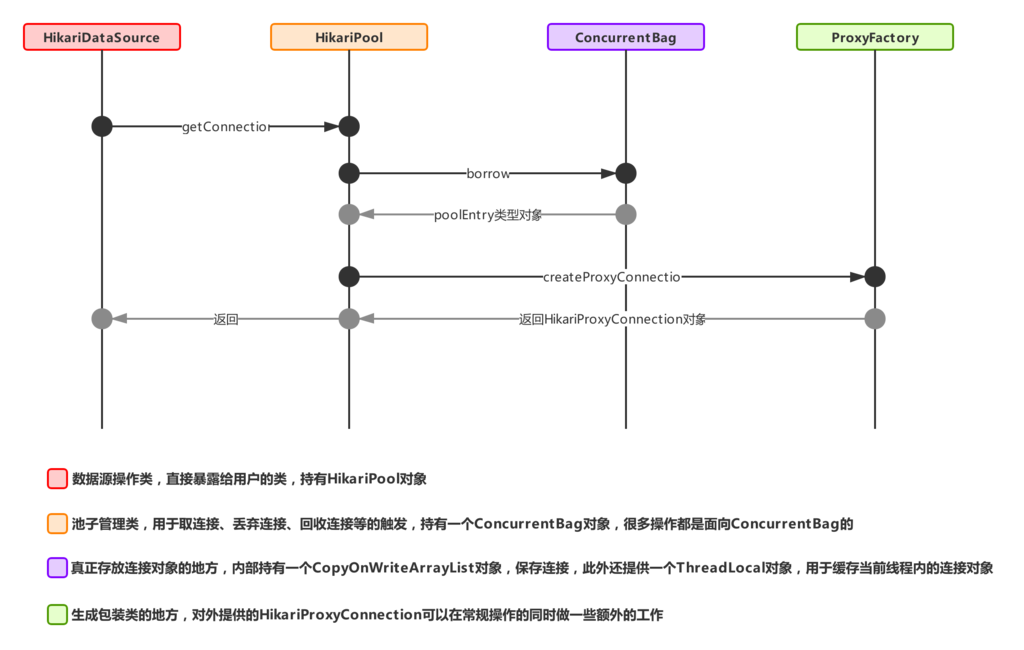
一、主流程1:获取连接流程
HikariCP获取连接时的入口是HikariDataSource里的getConnection方法,现在来看下该方法的具体流程:
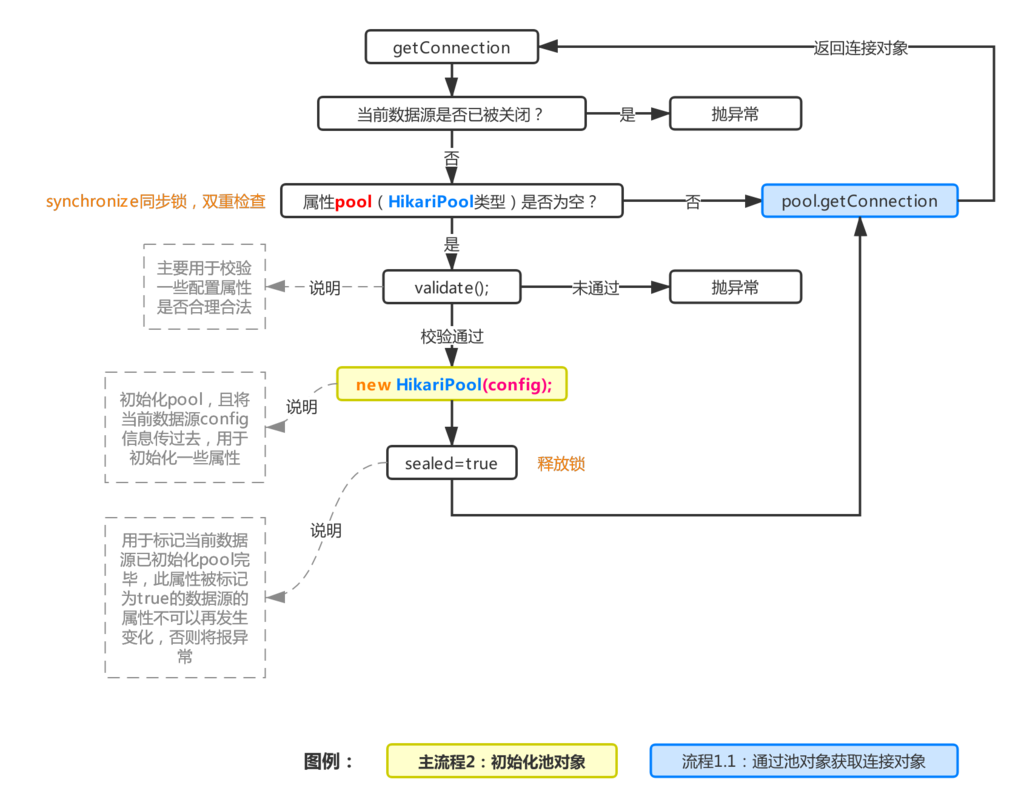
上述为HikariCP获取连接时的流程图,由图1可知,每个datasource对象里都会持有一个HikariPool对象,记为pool,初始化后的datasource对象pool是空的,所以第一次getConnection的时候会进行实例化pool属性(参考主流程1),初始化的时候需要将当前datasource里的config属性传过去,用于pool的初始化,最终标记sealed,然后根据pool对象调用getConnection方法(参考流程1.1),获取成功后返回连接对象。
二、主流程2:初始化池对象
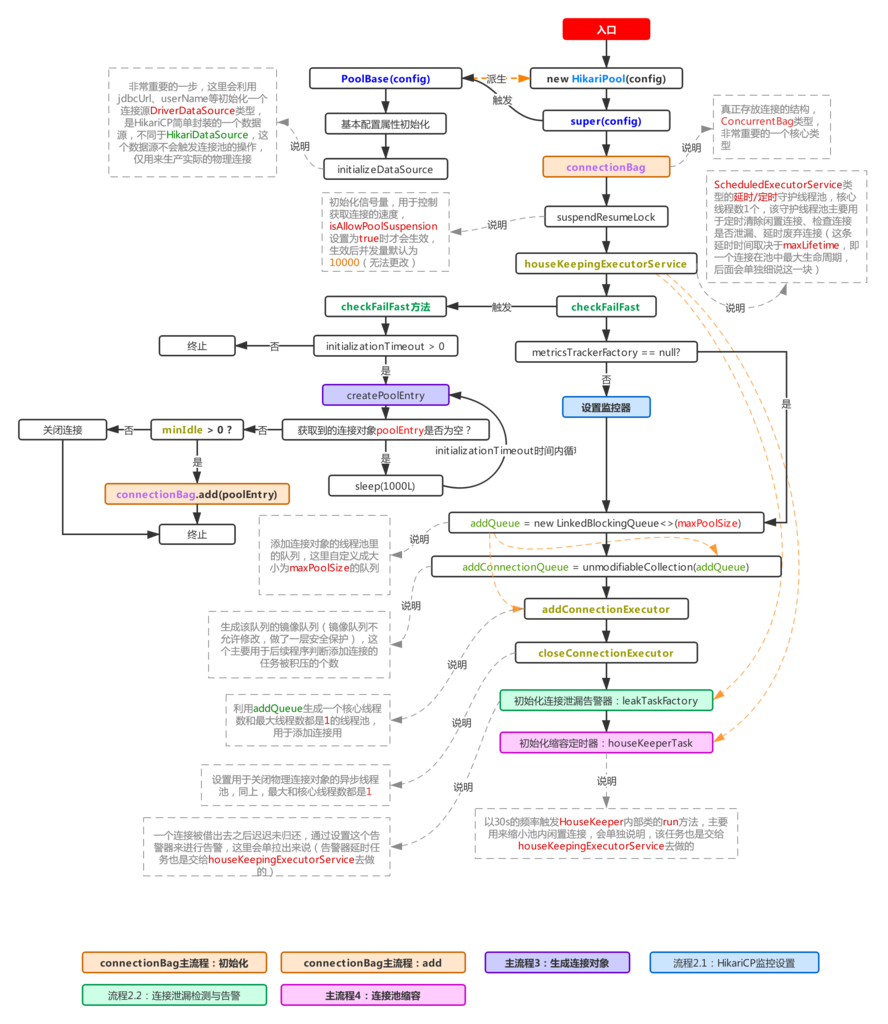
该流程用于初始化整个连接池,这个流程会给连接池内所有的属性做初始化的工作,其中比较主要的几个流程上图已经指出,简单概括一下:
利用 config初始化各种连接池属性,并且产生一个用于生产物理连接的数据源DriverDataSource初始化存放连接对象的核心类 connectionBag初始化一个延时任务线程池类型的对象 houseKeepingExecutorService,用于后续执行一些延时/定时类任务(比如连接泄漏检查延时任务,参考流程2.2以及主流程4,除此之外maxLifeTime后主动回收关闭连接也是交由该对象来执行的,这个过程可以参考主流程3)预热连接池,HikariCP会在该流程的 checkFailFast里初始化好一个连接对象放进池子内,当然触发该流程得保证initializationTimeout > 0时(默认值1),这个配置属性表示留给预热操作的时间(默认值1在预热失败时不会发生重试)。与Druid通过initialSize控制预热连接对象数不一样的是,HikariCP仅预热进池一个连接对象。初始化一个线程池对象 addConnectionExecutor,用于后续扩充连接对象初始化一个线程池对象 closeConnectionExecutor,用于关闭一些连接对象,怎么触发关闭任务呢?可以参考流程1.1.2
三、流程1.1:通过HikariPool获取连接对象
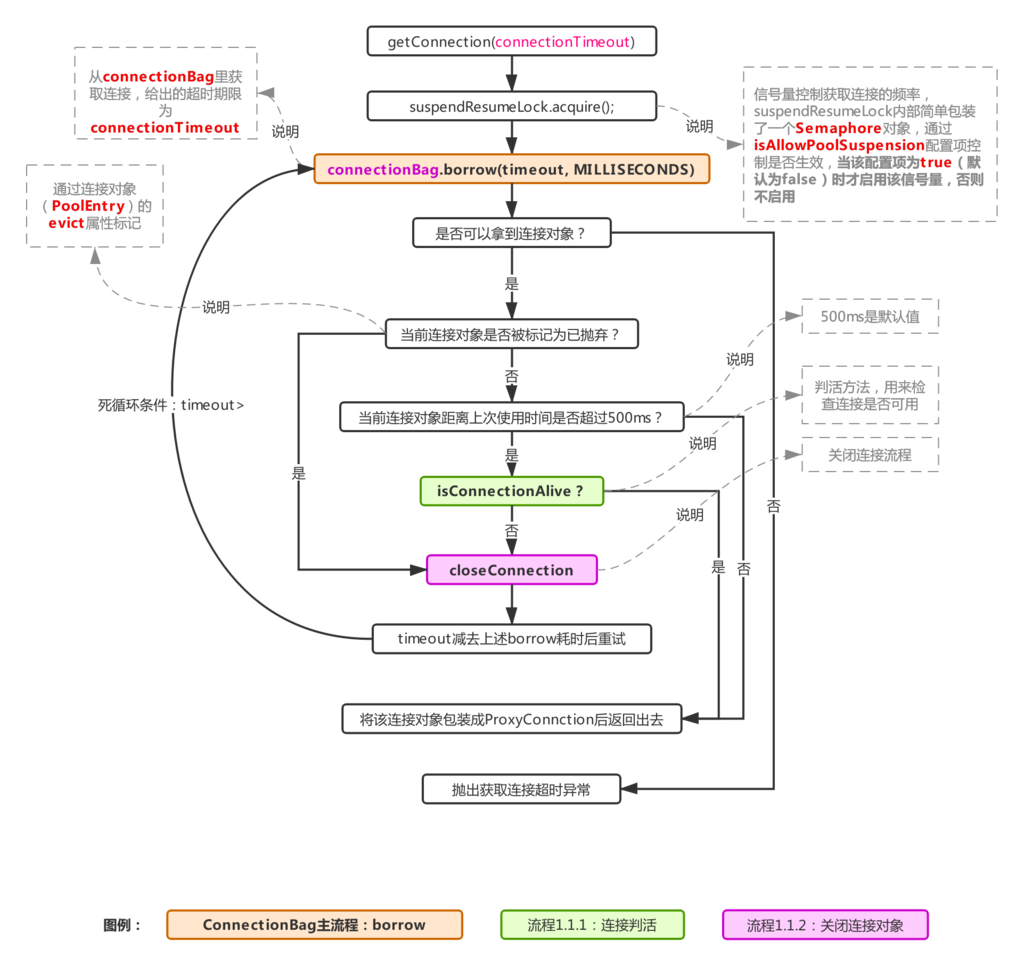
从最开始的结构图可知,每个HikariPool里都维护一个ConcurrentBag对象,用于存放连接对象,由上图可以看到,实际上HikariPool的getConnection就是从ConcurrentBag里获取连接的(调用其borrow方法获得,对应ConnectionBag主流程),在长连接检查这块,与之前说的Druid不同,这里的长连接判活检查在连接对象没有被标记为“已丢弃”时,只要距离上次使用超过500ms每次取出都会进行检查(500ms是默认值,可通过配置com.zaxxer.hikari.aliveBypassWindowMs的系统参数来控制),emmmm,也就是说HikariCP对长连接的活性检查很频繁,但是其并发性能依旧优于Druid,说明频繁的长连接检查并不是导致连接池性能高低的关键所在。
这个其实是由于HikariCP的无锁实现,在高并发时对CPU的负载没有其他连接池那么高而产生的并发性能差异,后面会说HikariCP的具体做法,即使是Druid,在获取连接、生成连接、归还连接时都进行了锁控制,因为通过上篇解析Druid的文章可以知道,Druid里的连接池资源是多线程共享的,不可避免的会有锁竞争,有锁竞争意味着线程状态的变化会很频繁,线程状态变化频繁意味着CPU上下文切换也将会很频繁。
回到流程1.1,如果拿到的连接为空,直接报错,不为空则进行相应的检查,如果检查通过,则包装成ConnectionProxy对象返回给业务方,不通过则调用closeConnection方法关闭连接(对应流程1.1.2,该流程会触发ConcurrentBag的remove方法丢弃该连接,然后把实际的驱动连接交给closeConnectionExecutor线程池,异步关闭驱动连接)。
四、流程1.1.1:连接判活
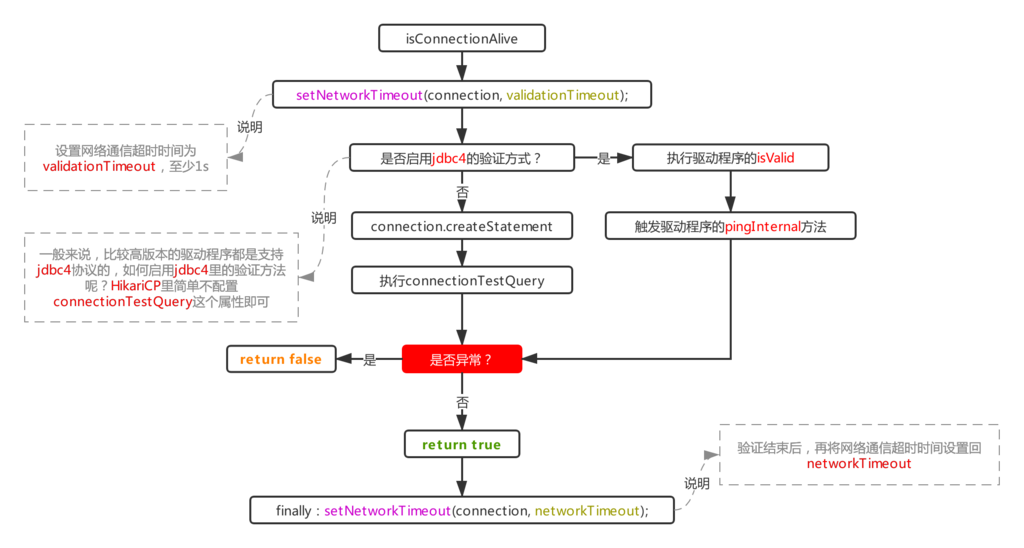
承接上面的流程1.1里的判活流程,来看下判活是如何做的,首先说验证方法(注意这里该方法接受的这个connection对象不是poolEntry,而是poolEntry持有的实际驱动的连接对象),在之前介绍Druid的时候就知道,Druid是根据驱动程序里是否存在ping方法来判断是否启用ping的方式判断连接是否存活,但是到了HikariCP则更加简单粗暴,仅根据是否配置了connectionTestQuery觉定是否启用ping:
this.isUseJdbc4Validation = config.getConnectionTestQuery() == null;
所以一般驱动如果不是特别低的版本,不建议配置该项,否则便会走createStatement+excute的方式,相比ping简单发送心跳数据,这种方式显然更低效。
此外,这里在刚进来还会通过驱动的连接对象重新给它设置一遍networkTimeout的值,使之变成validationTimeout,表示一次验证的超时时间,为啥这里要重新设置这个属性呢?因为在使用ping方法校验时,是没办法通过类似statement那样可以setQueryTimeout的,所以只能由网络通信的超时时间来控制,这个时间可以通过jdbc的连接参数socketTimeout来控制:
jdbc:mysql://127.0.0.1:3306/xxx?socketTimeout=250
这个值最终会被赋值给HikariCP的networkTimeout字段,这就是为什么最后那一步使用这个字段来还原驱动连接超时属性的原因;说到这里,最后那里为啥要再次还原呢?这就很容易理解了,因为验证结束了,连接对象还存活的情况下,它的networkTimeout的值这时仍然等于validationTimeout(不合预期),显然在拿出去用之前,需要恢复成本来的值,也就是HikariCP里的networkTimeout属性。
五、流程1.1.2:关闭连接对象
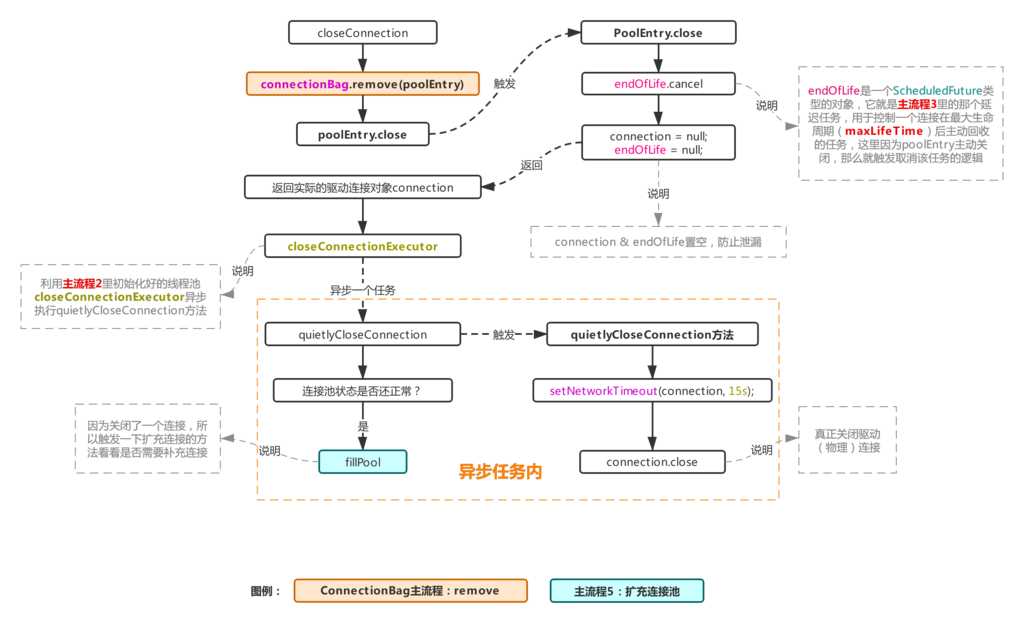
这个流程简单来说就是把流程1.1.1中验证不通过的死连接,主动关闭的一个流程,首先会把这个连接对象从ConnectionBag里移除,然后把实际的物理连接交给一个线程池去异步执行,这个线程池就是在主流程2里初始化池的时候初始化的线程池closeConnectionExecutor,然后异步任务内开始实际的关连接操作,因为主动关闭了一个连接相当于少了一个连接,所以还会触发一次扩充连接池(参考主流程5)操作。
六、流程2.1:HikariCP监控设置
不同于Druid那样监控指标那么多,HikariCP会把我们非常关心的几项指标暴露给我们,比如当前连接池内闲置连接数、总连接数、一个连接被用了多久归还、创建一个物理连接花费多久等,HikariCP的连接池的监控我们这一节专门详细的分解一下,首先找到HikariCP下面的metrics文件夹,这下面放置了一些规范实现的监控接口等,还有一些现成的实现(比如HikariCP自带对prometheus、micrometer、dropwizard的支持,不太了解后面两个,prometheus下文直接称为普罗米修斯):
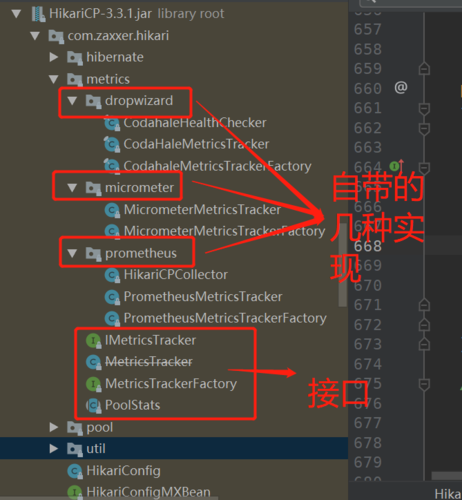
下面,来着重看下接口的定义:
//这个接口的实现主要负责收集一些动作的耗时
public interface IMetricsTracker extends AutoCloseable
{
//这个方法触发点在创建实际的物理连接时(主流程3),用于记录一个实际的物理连接创建所耗费的时间
default void recordConnectionCreatedMillis(long connectionCreatedMillis) {}
//这个方法触发点在getConnection时(主流程1),用于记录获取一个连接时实际的耗时
default void recordConnectionAcquiredNanos(final long elapsedAcquiredNanos) {}
//这个方法触发点在回收连接时(主流程6),用于记录一个连接从被获取到被回收时所消耗的时间
default void recordConnectionUsageMillis(final long elapsedBorrowedMillis) {}
//这个方法触发点也在getConnection时(主流程1),用于记录获取连接超时的次数,每发生一次获取连接超时,就会触发一次该方法的调用
default void recordConnectionTimeout() {}
@Override
default void close() {}
}
触发点都了解清楚后,再来看看MetricsTrackerFactory的接口定义:
//用于创建IMetricsTracker实例,并且按需记录PoolStats对象里的属性(这个对象里的属性就是类似连接池当前闲置连接数之类的线程池状态类指标)
public interface MetricsTrackerFactory
{
//返回一个IMetricsTracker对象,并且把PoolStats传了过去
IMetricsTracker create(String poolName, PoolStats poolStats);
}
上面的接口用法见注释,针对新出现的PoolStats类,我们来看看它做了什么:
public abstract class PoolStats {
private final AtomicLong reloadAt; //触发下次刷新的时间(时间戳)
private final long timeoutMs; //刷新下面的各项属性值的频率,默认1s,无法改变
// 总连接数
protected volatile int totalConnections;
// 闲置连接数
protected volatile int idleConnections;
// 活动连接数
protected volatile int activeConnections;
// 由于无法获取到可用连接而阻塞的业务线程数
protected volatile int pendingThreads;
// 最大连接数
protected volatile int maxConnections;
// 最小连接数
protected volatile int minConnections;
public PoolStats(final long timeoutMs) {
this.timeoutMs = timeoutMs;
this.reloadAt = new AtomicLong();
}
//这里以获取最大连接数为例,其他的跟这个差不多
public int getMaxConnections() {
if (shouldLoad()) { //是否应该刷新
update(); //刷新属性值,注意这个update的实现在HikariPool里,因为这些属性值的直接或间接来源都是HikariPool
}
return maxConnections;
}
protected abstract void update(); //实现在↑上面已经说了
private boolean shouldLoad() { //按照更新频率来决定是否刷新属性值
for (; ; ) {
final long now = currentTime();
final long reloadTime = reloadAt.get();
if (reloadTime > now) {
return false;
} else if (reloadAt.compareAndSet(reloadTime, plusMillis(now, timeoutMs))) {
return true;
}
}
}
}
实际上这里就是这些属性获取和触发刷新的地方,那么这个对象是在哪里被生成并且丢给MetricsTrackerFactory的create方法的呢?这就是本节所需要讲述的要点:主流程2里的设置监控器的流程,来看看那里发生了什么事吧:
//监控器设置方法(此方法在HikariPool中,metricsTracker属性就是HikariPool用来触发IMetricsTracker里方法调用的)
public void setMetricsTrackerFactory(MetricsTrackerFactory metricsTrackerFactory) {
if (metricsTrackerFactory != null) {
//MetricsTrackerDelegate是包装类,是HikariPool的一个静态内部类,是实际持有IMetricsTracker对象的类,也是实际触发IMetricsTracker里方法调用的类
//这里首先会触发MetricsTrackerFactory类的create方法拿到IMetricsTracker对象,然后利用getPoolStats初始化PoolStat对象,然后也一并传给MetricsTrackerFactory
this.metricsTracker = new MetricsTrackerDelegate(metricsTrackerFactory.create(config.getPoolName(), getPoolStats()));
} else {
//不启用监控,直接等于一个没有实现方法的空类
this.metricsTracker = new NopMetricsTrackerDelegate();
}
}
private PoolStats getPoolStats() {
//初始化PoolStats对象,并且规定1s触发一次属性值刷新的update方法
return new PoolStats(SECONDS.toMillis(1)) {
@Override
protected void update() {
//实现了PoolStat的update方法,刷新各个属性的值
this.pendingThreads = HikariPool.this.getThreadsAwaitingConnection();
this.idleConnections = HikariPool.this.getIdleConnections();
this.totalConnections = HikariPool.this.getTotalConnections();
this.activeConnections = HikariPool.this.getActiveConnections();
this.maxConnections = config.getMaximumPoolSize();
this.minConnections = config.getMinimumIdle();
}
};
}
到这里HikariCP的监控器就算是注册进去了,所以要想实现自己的监控器拿到上面的指标,要经过如下步骤:
新建一个类实现 IMetricsTracker接口,我们这里将该类记为IMetricsTrackerImpl新建一个类实现 MetricsTrackerFactory接口,我们这里将该类记为MetricsTrackerFactoryImpl,并且将上面的IMetricsTrackerImpl在其create方法内实例化将 MetricsTrackerFactoryImpl实例化后调用HikariPool的setMetricsTrackerFactory方法注册到Hikari连接池。
上面没有提到PoolStats里的属性怎么监控,这里来说下,由于create方法是调用一次就没了,create方法只是接收了PoolStats对象的实例,如果不处理,那么随着create调用的结束,这个实例针对监控模块来说就失去持有了,所以这里如果想要拿到PoolStats里的属性,就需要开启一个守护线程,让其持有PoolStats对象实例,并且定时获取其内部属性值,然后push给监控系统,如果是普罗米修斯等使用pull方式获取监控数据的监控系统,可以效仿HikariCP原生普罗米修斯监控的实现,自定义一个Collector对象来接收PoolStats实例,这样普罗米修斯就可以定期拉取了,比如HikariCP根据普罗米修斯监控系统自己定义的MetricsTrackerFactory实现(对应图2里的PrometheusMetricsTrackerFactory类):
@Override
public IMetricsTracker create(String poolName, PoolStats poolStats) {
getCollector().add(poolName, poolStats); //将接收到的PoolStats对象直接交给Collector,这样普罗米修斯服务端每触发一次采集接口的调用,PoolStats都会跟着执行一遍内部属性获取流程
return new PrometheusMetricsTracker(poolName, this.collectorRegistry); //返回IMetricsTracker接口的实现类
}
//自定义的Collector
private HikariCPCollector getCollector() {
if (collector == null) {
//注册到普罗米修斯收集中心
collector = new HikariCPCollector().register(this.collectorRegistry);
}
return collector;
通过上面的解释可以知道在HikariCP中如何自定义一个自己的监控器,以及相比Druid的监控,有什么区别。
工作中很多时候都是需要自定义的,我司虽然也是用的普罗米修斯监控,但是因为HikariCP原生的普罗米修斯收集器里面对监控指标的命名并不符合我司的规范,所以就自定义了一个,有类似问题的不妨也试一试。
🍁 这一节没有画图,纯代码,因为画图不太好解释这部分的东西,这部分内容与连接池整体流程关系也不大,充其量获取了连接池本身的一些属性,在连接池里的触发点也在上面代码段的注释里说清楚了,看代码定义可能更好理解一些。
七、流程2.2:连接泄漏的检测与告警
本节对应主流程2里的子流程2.2,在初始化池对象时,初始化了一个叫做leakTaskFactory的属性,本节来看下它具体是用来做什么的。
7.1:它是做什么的?
一个连接被拿出去使用时间超过leakDetectionThreshold(可配置,默认0)未归还的,会触发一个连接泄漏警告,通知业务方目前存在连接泄漏的问题。
7.2:过程详解
该属性是ProxyLeakTaskFactory类型对象,且它还会持有houseKeepingExecutorService这个线程池对象,用于生产ProxyLeakTask对象,然后利用上面的houseKeepingExecutorService延时运行该对象里的run方法。该流程的触发点在上面的流程1.1最后包装成ProxyConnection对象的那一步,来看看具体的流程图:
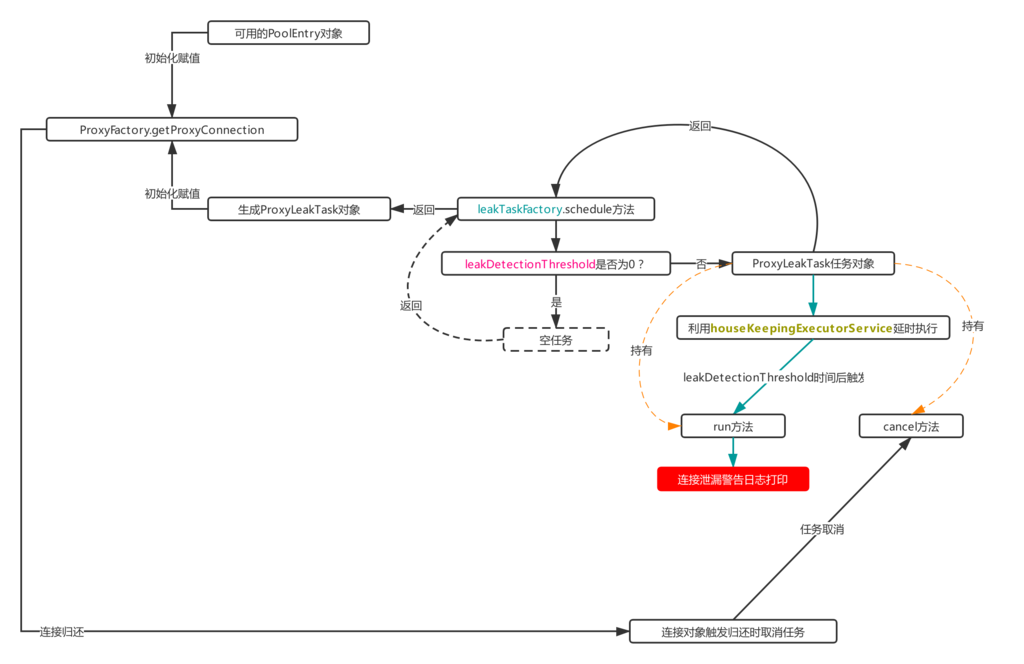
每次在流程1.1那里生成ProxyConnection对象时,都会触发上面的流程,由流程图可以知道,ProxyConnection对象持有PoolEntry和ProxyLeakTask的对象,其中初始化ProxyLeakTask对象时就用到了leakTaskFactory对象,通过其schedule方法可以进行ProxyLeakTask的初始化,并将其实例传递给ProxyConnection进行初始化赋值(ps:由图知ProxyConnection在触发回收事件时,会主动取消这个泄漏检查任务,这也是ProxyConnection需要持有ProxyLeakTask对象的原因)。
在上面的流程图中可以知道,只有在leakDetectionThreshold不等于0的时候才会生成一个带有实际延时任务的ProxyLeakTask对象,否则返回无实际意义的空对象。所以要想启用连接泄漏检查,首先要把leakDetectionThreshold配置设置上,这个属性表示经过该时间后借出去的连接仍未归还,则触发连接泄漏告警。
ProxyConnection之所以要持有ProxyLeakTask对象,是因为它可以监听到连接是否触发归还操作,如果触发,则调用cancel方法取消延时任务,防止误告。
由此流程可以知道,跟Druid一样,HikariCP也有连接对象泄漏检查,与Druid主动回收连接相比,HikariCP实现更加简单,仅仅是在触发时打印警告日志,不会采取具体的强制回收的措施。
与Druid一样,默认也是关闭这个流程的,因为实际开发中一般使用第三方框架,框架本身会保证及时的close连接,防止连接对象泄漏,开启与否还是取决于业务是否需要,如果一定要开启,如何设置leakDetectionThreshold的大小也是需要考虑的一件事。
八、主流程3:生成连接对象
本节来讲下主流程2里的createEntry方法,这个方法利用PoolBase里的DriverDataSource对象生成一个实际的连接对象(如果忘记DriverDatasource是哪里初始化的了,可以看下主流程2里PoolBase的initializeDataSource方法的作用),然后用PoolEntry类包装成PoolEntry对象,现在来看下这个包装类有哪些主要属性:
final class PoolEntry implements IConcurrentBagEntry {
private static final Logger LOGGER = LoggerFactory.getLogger(PoolEntry.class);
//通过cas来修改state属性
private static final AtomicIntegerFieldUpdater stateUpdater;
Connection connection; //实际的物理连接对象
long lastAccessed; //触发回收时刷新该时间,表示“最近一次使用时间”
long lastBorrowed; //getConnection里borrow成功后刷新该时间,表示“最近一次借出的时间”
@SuppressWarnings("FieldCanBeLocal")
private volatile int state = 0; //连接状态,枚举值:IN_USE(使用中)、NOT_IN_USE(闲置中)、REMOVED(已移除)、RESERVED(标记为保留中)
private volatile boolean evict; //是否被标记为废弃,很多地方用到(比如流程1.1靠这个判断连接是否已被废弃,再比如主流程4里时钟回拨时触发的直接废弃逻辑)
private volatile ScheduledFuture<?> endOfLife; //用于在超过连接生命周期(maxLifeTime)时废弃连接的延时任务,这里poolEntry要持有该对象,主要是因为在对象主动被关闭时(意味着不需要在超过maxLifeTime时主动失效了),需要cancel掉该任务
private final FastList openStatements; //当前该连接对象上生成的所有的statement对象,用于在回收连接时主动关闭这些对象,防止存在漏关的statement
private final HikariPool hikariPool; //持有pool对象
private final boolean isReadOnly; //是否为只读
private final boolean isAutoCommit; //是否存在事务
}
上面就是整个PoolEntry对象里所有的属性,这里再说下endOfLife对象,它是一个利用houseKeepingExecutorService这个线程池对象做的延时任务,这个延时任务一般在创建好连接对象后maxLifeTime左右的时间触发,具体来看下createEntry代码:
private PoolEntry createPoolEntry() {
final PoolEntry poolEntry = newPoolEntry(); //生成实际的连接对象
final long maxLifetime = config.getMaxLifetime(); //拿到配置好的maxLifetime
if (maxLifetime > 0) { //<=0的时候不启用主动过期策略
// 计算需要减去的随机数
// 源注释:variance up to 2.5% of the maxlifetime
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong(maxLifetime / 40) : 0;
final long lifetime = maxLifetime - variance; //生成实际的延时时间
poolEntry.setFutureEol(houseKeepingExecutorService.schedule(
() -> { //实际的延时任务,这里直接触发softEvictConnection,而softEvictConnection内则会标记该连接对象为废弃状态,然后尝试修改其状态为STATE_RESERVED,若成功,则触发closeConnection(对应流程1.1.2)
if (softEvictConnection(poolEntry, "(connection has passed maxLifetime)", false /* not owner */)) {
addBagItem(connectionBag.getWaitingThreadCount()); //回收完毕后,连接池内少了一个连接,就会尝试新增一个连接对象
}
},
lifetime, MILLISECONDS)); //给endOfLife赋值,并且提交延时任务,lifetime后触发
}
return poolEntry;
}
//触发新增连接任务
public void addBagItem(final int waiting) {
//前排提示:addConnectionQueue和addConnectionExecutor的关系和初始化参考主流程2
//当添加连接的队列里已提交的任务超过那些因为获取不到连接而发生阻塞的线程个数时,就进行提交连接新增连接的任务
final boolean shouldAdd = waiting - addConnectionQueue.size() >= 0; // Yes, >= is intentional.
if (shouldAdd) {
//提交任务给addConnectionExecutor这个线程池,PoolEntryCreator是一个实现了Callable接口的类,下面将通过流程图的方式介绍该类的call方法
addConnectionExecutor.submit(poolEntryCreator);
}
}
通过上面的流程,可以知道,HikariCP一般通过createEntry方法来新增一个连接入池,每个连接被包装成PoolEntry对象,在创建好对象时,同时会提交一个延时任务来关闭废弃该连接,这个时间就是我们配置的maxLifeTime,为了保证不在同一时间失效,HikariCP还会利用maxLifeTime减去一个随机数作为最终的延时任务延迟时间,然后在触发废弃任务时,还会触发addBagItem,进行连接添加任务(因为废弃了一个连接,需要往池子里补充一个),该任务则交给由主流程2里定义好的addConnectionExecutor线程池执行,那么,现在来看下这个异步添加连接对象的任务流程:
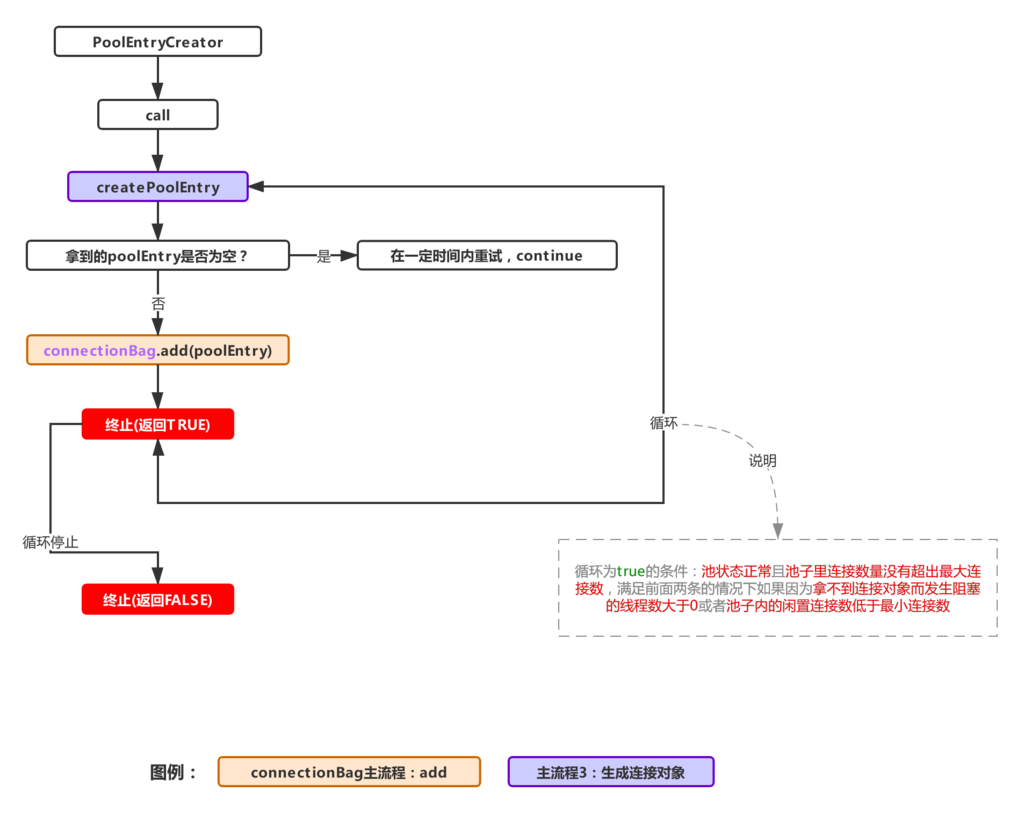
这个流程就是往连接池里加连接用的,跟createEntry结合起来说是因为这俩流程是紧密相关的,除此之外,主流程5(fillPool,扩充连接池)也会触发该任务。
九、主流程4:连接池缩容
HikariCP会按照minIdle定时清理闲置过久的连接,这个定时任务在主流程2初始化连接池对象时被启用,跟上面的流程一样,也是利用houseKeepingExecutorService这个线程池对象做该定时任务的执行器。
来看下主流程2里是怎么启用该任务的:
//housekeepingPeriodMs的默认值是30s,所以定时任务的间隔为30s
this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
那么本节主要来说下HouseKeeper这个类,该类实现了Runnable接口,回收逻辑主要在其run方法内,来看看run方法的逻辑流程图:
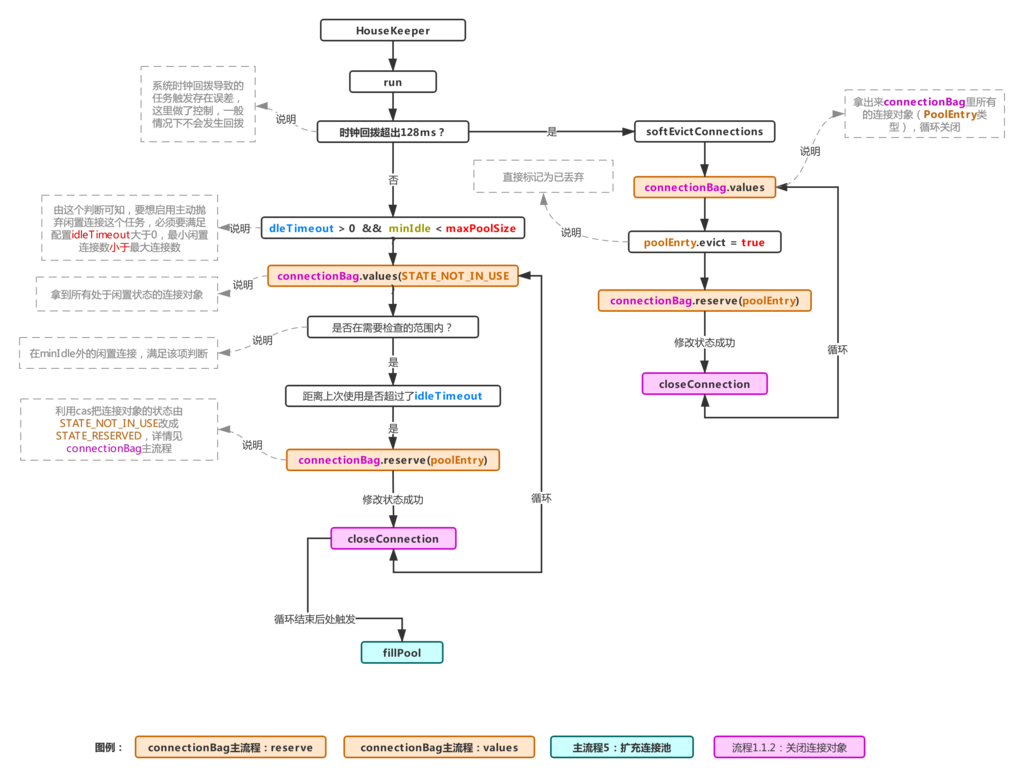
上面的流程就是HouseKeeper的run方法里具体做的事情,由于系统时间回拨会导致该定时任务回收一些连接时产生误差,因此存在如下判断:
//now就是当前系统时间,previous就是上次触发该任务时的时间,housekeepingPeriodMs就是隔多久触发该任务一次
//也就是说plusMillis(previous, housekeepingPeriodMs)表示当前时间
//如果系统时间没被回拨,那么plusMillis(now, 128)一定是大于当前时间的,如果被系统时间被回拨
//回拨的时间超过128ms,那么下面的判断就成立,否则永远不会成立
if (plusMillis(now, 128) < plusMillis(previous, housekeepingPeriodMs))
这是hikariCP在解决系统时钟被回拨时做出的一种措施,通过流程图可以看到,它是直接把池子里所有的连接对象取出来挨个儿的标记成废弃,并且尝试把状态值修改为STATE_RESERVED(后面会说明这些状态,这里先不深究)。如果系统时钟没有发生改变(绝大多数情况会命中这一块的逻辑),由图知,会把当前池内所有处于闲置状态(STATE_NOT_IN_USE)的连接拿出来,然后计算需要检查的范围,然后循环着修改连接的状态:
//拿到所有处于闲置状态的连接
final List notInUse = connectionBag.values(STATE_NOT_IN_USE);
//计算出需要被检查闲置时间的数量,简单来说,池内需要保证最小minIdle个连接活着,所以需要计算出超出这个范围的闲置对象进行检查
int toRemove = notInUse.size() - config.getMinIdle();
for (PoolEntry entry : notInUse) {
//在检查范围内,且闲置时间超出idleTimeout,然后尝试将连接对象状态由STATE_NOT_IN_USE变为STATE_RESERVED成功
if (toRemove > 0 && elapsedMillis(entry.lastAccessed, now) > idleTimeout && connectionBag.reserve(entry)) {
closeConnection(entry, "(connection has passed idleTimeout)"); //满足上述条件,进行连接关闭
toRemove--;
}
}
fillPool(); //因为可能回收了一些连接,所以要再次触发连接池扩充流程检查下是否需要新增连接。
上面的代码就是流程图里对应的没有回拨系统时间时的流程逻辑。该流程在idleTimeout大于0(默认等于0)并且minIdle小于maxPoolSize的时候才会启用,默认是不启用的,若需要启用,可以按照条件来配置。
十、主流程5:扩充连接池
这个流程主要依附HikariPool里的fillPool方法,这个方法已经在上面很多流程里出现过了,它的作用就是在触发连接废弃、连接池连接不够用时,发起扩充连接数的操作,这是个很简单的过程,下面看下源码(为了使代码结构更加清晰,对源码做了细微改动):
// PoolEntryCreator关于call方法的实现流程在主流程3里已经看过了,但是这里却有俩PoolEntryCreator对象,
// 这是个较细节的地方,用于打日志用,不再说这部分,为了便于理解,只需要知道这俩对象执行的是同一块call方法即可
private final PoolEntryCreator poolEntryCreator = new PoolEntryCreator(null);
private final PoolEntryCreator postFillPoolEntryCreator = new PoolEntryCreator("After adding ");
private synchronized void fillPool() {
// 这个判断就是根据当前池子里相关数据,推算出需要扩充的连接数,
// 判断方式就是利用最大连接数跟当前连接总数的差值,与最小连接数与当前池内闲置的连接数的差值,取其最小的那一个得到
int needAdd = Math.min(maxPoolSize - connectionBag.size(),
minIdle - connectionBag.getCount(STATE_NOT_IN_USE));
//减去当前排队的任务,就是最终需要新增的连接数
final int connectionsToAdd = needAdd - addConnectionQueue.size();
for (int i = 0; i < connectionsToAdd; i++) {
//一般循环的最后一次会命中postFillPoolEntryCreator任务,其实就是在最后一次会打印一次日志而已(可以忽略该干扰逻辑)
addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator);
}
}
由该过程可以知道,最终这个新增连接的任务也是交由addConnectionExecutor线程池来处理的,而任务的主题也是PoolEntryCreator,这个流程可以参考主流程3.
然后needAdd的推算:
Math.min(最大连接数 - 池内当前连接总数, 最小连接数 - 池内闲置的连接数)
根据这个方式判断,可以保证池内的连接数永远不会超过maxPoolSize,也永远不会低于minIdle。在连接吃紧的时候,可以保证每次触发都以minIdle的数量扩容。因此如果在maxPoolSize跟minIdle配置的值一样的话,在池内连接吃紧的时候,就不会发生任何扩容了。
十一、主流程6:连接回收
最开始说过,最终真实的物理连接对象会被包装成PoolEntry对象,存放进ConcurrentBag,然后获取时,PoolEntry对象又会被再次包装成ProxyConnection对象暴露给使用方的,那么触发连接回收,实际上就是触发ProxyConnection里的close方法:
public final void close() throws SQLException {
// 原注释:Closing statements can cause connection eviction, so this must run before the conditional below
closeStatements(); //此连接对象在业务方使用过程中产生的所有statement对象,进行统一close,防止漏close的情况
if (delegate != ClosedConnection.CLOSED_CONNECTION) {
leakTask.cancel(); //取消连接泄漏检查任务,参考流程2.2
try {
if (isCommitStateDirty && !isAutoCommit) { //在存在执行语句后并且还打开了事务,调用close时需要主动回滚事务
delegate.rollback(); //回滚
lastAccess = currentTime(); //刷新"最后一次使用时间"
}
} finally {
delegate = ClosedConnection.CLOSED_CONNECTION;
poolEntry.recycle(lastAccess); //触发回收
}
}
}
这个就是ProxyConnection里的close方法,可以看到它最终会调用PoolEntry的recycle方法进行回收,除此之外,连接对象的最后一次使用时间也是在这个时候刷新的,该时间是个很重要的属性,可以用来判断一个连接对象的闲置时间,来看下PoolEntry的recycle方法:
void recycle(final long lastAccessed) {
if (connection != null) {
this.lastAccessed = lastAccessed; //刷新最后使用时间
hikariPool.recycle(this); //触发HikariPool的回收方法,把自己传过去
}
}
之前有说过,每个PoolEntry对象都持有HikariPool的对象,方便触发连接池的一些操作,由上述代码可以看到,最终还是会触发HikariPool里的recycle方法,再来看下HikariPool的recycle方法:
void recycle(final PoolEntry poolEntry) {
metricsTracker.recordConnectionUsage(poolEntry); //监控指标相关,忽略
connectionBag.requite(poolEntry); //最终触发connectionBag的requite方法归还连接,该流程参考ConnectionBag主流程里的requite方法部分
}
以上就是连接回收部分的逻辑,相比其他流程,还是比较简洁的。
十二、ConcurrentBag主流程
这个类用来存放最终的PoolEntry类型的连接对象,提供了基本的增删查的功能,被HikariPool持有,上面那么多的操作,几乎都是在HikariPool中完成的,HikariPool用来管理实际的连接生产动作和回收动作,实际操作的却是ConcurrentBag类,梳理下上面所有流程的触发点:
主流程2:初始化HikariPool时初始化 ConcurrentBag(构造方法),预热时通过createEntry拿到连接对象,调用ConcurrentBag.add添加连接到ConcurrentBag。流程1.1:通过HikariPool获取连接时,通过调用 ConcurrentBag.borrow拿到一个连接对象。主流程6:通过 ConcurrentBag.requite归还一个连接。流程1.1.2:触发关闭连接时,会通过 ConcurrentBag.remove移除连接对象,由前面的流程可知关闭连接触发点为:连接超过最大生命周期maxLifeTime主动废弃、健康检查不通过主动废弃、连接池缩容。主流程3:通过异步添加连接时,通过调用 ConcurrentBag.add添加连接到ConcurrentBag,由前面的流程可知添加连接触发点为:连接超过最大生命周期maxLifeTime主动废弃连接后、连接池扩容。主流程4:连接池缩容任务,通过调用 ConcurrentBag.values筛选出需要的做操作的连接对象,然后再通过ConcurrentBag.reserve完成对连接对象状态的修改,然后会通过流程1.1.2触发关闭和移除连接操作。
通过触发点整理,可以知道该结构里的主要方法,就是上面触发点里标记为标签色的部分,然后来具体看下该类的基本定义和主要方法:
public class ConcurrentBag<T extends IConcurrentBagEntry> implements AutoCloseable {
private final CopyOnWriteArrayList<T> sharedList; //最终存放PoolEntry对象的地方,它是一个CopyOnWriteArrayList
private final boolean weakThreadLocals; //默认false,为true时可以让一个连接对象在下方threadList里的list内处于弱引用状态,防止内存泄漏(参见备注1)
private final ThreadLocal<List<Object>> threadList; //线程级的缓存,从sharedList拿到的连接对象,会被缓存进当前线程内,borrow时会先从缓存中拿,从而达到池内无锁实现
private final IBagStateListener listener; //内部接口,HikariPool实现了该接口,主要用于ConcurrentBag主动通知HikariPool触发添加连接对象的异步操作(也就是主流程3里的addConnectionExecutor所触发的流程)
private final AtomicInteger waiters; //当前因为获取不到连接而发生阻塞的业务线程数,这个在之前的流程里也出现过,比如主流程3里addBagItem就会根据该指标进行判断是否需要新增连接
private volatile boolean closed; //标记当前ConcurrentBag是否已被关闭
private final SynchronousQueue<T> handoffQueue; //这是个即产即销的队列,用于在连接不够用时,及时获取到add方法里新创建的连接对象,详情可以参考下面borrow和add的代码
//内部接口,PoolEntry类实现了该接口
public interface IConcurrentBagEntry {
//连接对象的状态,前面的流程很多地方都已经涉及到了,比如主流程4的缩容
int STATE_NOT_IN_USE = 0; //闲置
int STATE_IN_USE = 1; //使用中
int STATE_REMOVED = -1; //已废弃
int STATE_RESERVED = -2; //标记保留,介于闲置和废弃之间的中间状态,主要由缩容那里触发修改
boolean compareAndSet(int expectState, int newState); //尝试利用cas修改连接对象的状态值
void setState(int newState); //设置状态值
int getState(); //获取状态值
}
//参考上面listener属性的解释
public interface IBagStateListener {
void addBagItem(int waiting);
}
//获取连接方法
public T borrow(long timeout, final TimeUnit timeUnit) {
// 省略...
}
//回收连接方法
public void requite(final T bagEntry) {
//省略...
}
//添加连接方法
public void add(final T bagEntry) {
//省略...
}
//移除连接方法
public boolean remove(final T bagEntry) {
//省略...
}
//根据连接状态值获取当前池子内所有符合条件的连接集合
public List values(final int state) {
//省略...
}
//获取当前池子内所有的连接
public List values() {
//省略...
}
//利用cas把传入的连接对象的state从 STATE_NOT_IN_USE 变为 STATE_RESERVED
public boolean reserve(final T bagEntry) {
//省略...
}
//获取当前池子内符合传入状态值的连接数量
public int getCount(final int state) {
//省略...
}
}
从这个基本结构就可以稍微看出HikariCP是如何优化传统连接池实现的了,相比Druid来说,HikariCP更加偏向无锁实现,尽量避免锁竞争的发生。
12.1:borrow
这个方法用来获取一个可用的连接对象,触发点为流程1.1,HikariPool就是利用该方法获取连接的,下面来看下该方法做了什么:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException {
// 源注释:Try the thread-local list first
final List<Object> list = threadList.get(); //首先从当前线程的缓存里拿到之前被缓存进来的连接对象集合
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i); //先移除,回收方法那里会再次add进来
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry; //默认不启用弱引用
// 获取到对象后,通过cas尝试把其状态从STATE_NOT_IN_USE 变为 STATE_IN_USE,注意,这里如果其他线程也在使用这个连接对象,
// 并且成功修改属性,那么当前线程的cas会失败,那么就会继续循环尝试获取下一个连接对象
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry; //cas设置成功后,表示当前线程绕过其他线程干扰,成功获取到该连接对象,直接返回
}
}
// 源注释:Otherwise, scan the shared list ... then poll the handoff queue
final int waiting = waiters.incrementAndGet(); //如果缓存内找不到一个可用的连接对象,则认为需要“回源”,waiters+1
try {
for (T bagEntry : sharedList) {
//循环sharedList,尝试把连接状态值从STATE_NOT_IN_USE 变为 STATE_IN_USE
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 源注释:If we may have stolen another waiter's connection, request another bag add.
if (waiting > 1) { //阻塞线程数大于1时,需要触发HikariPool的addBagItem方法来进行添加连接入池,这个方法的实现参考主流程3
listener.addBagItem(waiting - 1);
}
return bagEntry; //cas设置成功,跟上面的逻辑一样,表示当前线程绕过其他线程干扰,成功获取到该连接对象,直接返回
}
}
//走到这里说明不光线程缓存里的列表竞争不到连接对象,连sharedList里也找不到可用的连接,这时则认为需要通知HikariPool,该触发添加连接操作了
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout); //这时候开始利用timeout控制获取时间
do {
final long start = currentTime();
//尝试从handoffQueue队列里获取最新被加进来的连接对象(一般新入的连接对象除了加进sharedList之外,还会被offer进该队列)
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
//如果超出指定时间后仍然没有获取到可用的连接对象,或者获取到对象后通过cas设置成功,这两种情况都不需要重试,直接返回对象
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
//走到这里说明从队列内获取到了连接对象,但是cas设置失败,说明又该对象又被其他线程率先拿去用了,若时间还够,则再次尝试获取
timeout -= elapsedNanos(start); //timeout减去消耗的时间,表示下次循环可用时间
} while (timeout > 10_000); //剩余时间大于10s时才继续进行,一般情况下,这个循环只会走一次,因为timeout很少会配的比10s还大
return null; //超时,仍然返回null
} finally {
waiters.decrementAndGet(); //这一步出去后,HikariPool收到borrow的结果,算是走出阻塞,所以waiters-1
}
}
仔细看下注释,该过程大致分成三个主要步骤:
从线程缓存获取连接 获取不到再从 sharedList里获取都获取不到则触发添加连接逻辑,并尝试从队列里获取新生成的连接对象
12.2:add
这个流程会添加一个连接对象进入bag,通常由主流程3里的addBagItem方法通过addConnectionExecutor异步任务触发添加操作,该方法主流程如下:
public void add(final T bagEntry) {
sharedList.add(bagEntry); //直接加到sharedList里去
// 源注释:spin until a thread takes it or none are waiting
// 参考borrow流程,当存在线程等待获取可用连接,并且当前新入的这个连接状态仍然是闲置状态,且队列里无消费者等待获取时,发起一次线程调度
while (waiters.get() > 0 && bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) { //注意这里会offer一个连接对象入队列
yield();
}
}
结合borrow来理解的话,这里在存在等待线程时会添加一个连接对象入队列,可以让borrow里发生等待的地方更容易poll到这个连接对象。
12.3:requite
这个流程会回收一个连接,该方法的触发点在主流程6,具体代码如下:
public void requite(final T bagEntry) {
bagEntry.setState(STATE_NOT_IN_USE); //回收意味着使用完毕,更改state为STATE_NOT_IN_USE状态
for (int i = 0; waiters.get() > 0; i++) { //如果存在等待线程的话,尝试传给队列,让borrow获取
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) { //线程内连接集合的缓存最多50个,这里回收连接时会再次加进当前线程的缓存里,方便下次borrow获取
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry); //默认不启用弱引用,若启用的话,则缓存集合里的连接对象没有内存泄露的风险
}
}
12.4:remove
这个负责从池子里移除一个连接对象,触发点在流程1.1.2,代码如下:
public boolean remove(final T bagEntry) {
// 下面两个cas操作,都是从其他状态变为移除状态,任意一个成功,都不会走到下面的warn log
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
// 直接从sharedList移除掉
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}
这里需要注意的是,移除时仅仅移除了sharedList里的对象,各个线程内缓存的那一份集合里对应的对象并没有被移除,这个时候会不会存在该连接再次从缓存里拿到呢?会的,但是不会返回出去,而是直接remove掉了,仔细看borrow的代码发现状态不是闲置状态的时候,取出来时就会remove掉,然后也拿不出去,自然也不会触发回收方法。
12.5:values
该方法存在重载方法,用于返回当前池子内连接对象的集合,触发点在主流程4,代码如下:
public List values(final int state) {
//过滤出来符合状态值的对象集合逆序后返回出去
final List list = sharedList.stream().filter(e -> e.getState() == state).collect(Collectors.toList());
Collections.reverse(list);
return list;
}
public List values() {
//返回全部连接对象(注意下方clone为浅拷贝)
return (List) sharedList.clone();
}
12.6:reserve
该方法单纯将连接对象的状态值由STATE_NOT_IN_USE修改为STATE_RESERVED,触发点仍然是主流程4,缩容时使用,代码如下:
public boolean reserve(final T bagEntry){
return bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_RESERVED);
}
12.7:getCount
该方法用于返回池内符合某个状态值的连接的总数量,触发点为主流程5,扩充连接池时用于获取闲置连接总数,代码如下:
public int getCount(final int state){
int count = 0;
for (IConcurrentBagEntry e : sharedList) {
if (e.getState() == state) {
count++;
}
}
return count;
}
以上就是ConcurrentBag的主要方法和处理连接对象的主要流程。
十三、总结
到这里基本上一个连接的生产到获取到回收到废弃一整个生命周期在HikariCP内是如何管理的就说完了,相比之前的Druid的实现,有很大的不同,主要是HikariCP的无锁获取连接,本篇没有涉及FastList的说明,因为从连接管理这个角度确实很少用到该结构,用到FastList的地方主要在存储连接对象生成的statement对象以及用于存储线程内缓存起来的连接对象;
除此之外HikariCP还利用javassist技术编译期生成了ProxyConnection的初始化,这里也没有相关说明,网上有关HikariCP的优化有很多文章,大多数都提到了字节码优化、fastList、concurrentBag的实现,本篇主要通过深入解析HikariPool和ConcurrentBag的实现,来说明HikariCP相比Druid具体做了哪些不一样的操作。
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
