
【学术前沿】基于缺陷检测和度量学习的CCTV视频污水管道缺陷自动跟踪
点击上方“公众号”可订阅哦!
声明:本文只是针对个人学习记录,侵权可删。本人自觉遵守《中华人民共和国著作权法》和《伯尔尼公约》等法律,其他个人或组织等转载请保留此声明,并自负法律责任。论文版权与著作权等全归原作者所有。

01
文章摘要
02
文章导读
基于视觉的下水道检查技术,如闭路电视(CCTV),通常被用于通过拍摄视频和图像来调查下水道管道的内部状况。在检验过程中,检验员需要手工发现已存在的缺陷,并根据相关的规范、手册或标准,记录每个缺陷的类型、位置和数量。检查后,捕捉到的视频可能需要再次审查,以确认缺陷信息和评估下水道条件。虽然在不同的国家和地区采用不同的标准,如管道评估认证项目(PACP)在美国和香港管道条件评价准则(HKCCEC)在香港,所需的主要信息评估排污条件相似,通常包括缺陷类型,位置或分布的视频帧,沿着管道距离,每种类型的缺陷的数量,以及缺陷严重程度评分。然而,获取这些信息的人工解释过程需要大量的时间和精力,并且由于不同检查人员对缺陷条件的不同理解,结果可能是不一致的,例如,条件可能被高估或低估。
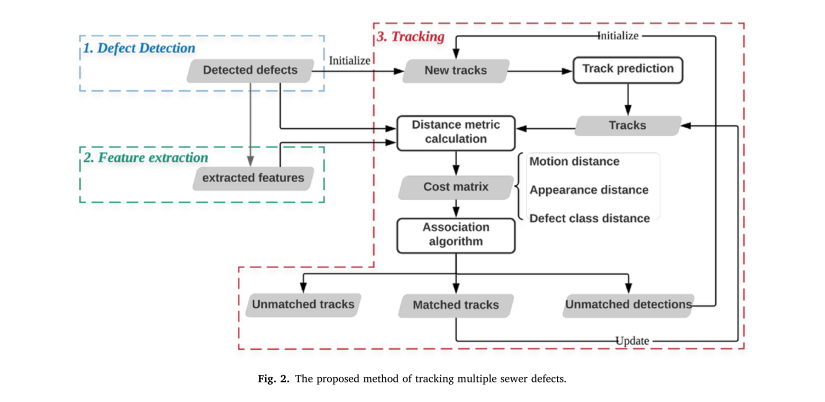
虽然下水道缺陷不是移动的物体,但在检查过程中,带有摄像头的检查设备是沿着管道移动并拍摄视频的。因此,在捕获的视频中,下水道缺陷可以看作是移动的物体。为了获得唯一的缺陷号,本文提出对视频中的每个缺陷进行跟踪,并为每个缺陷分配一个唯一的ID号。视频中各种下水道缺陷的跟踪问题类似于行人跟踪、车辆跟踪等多目标跟踪(MOT)问题,但并不完全相同。跟踪不同的下水道缺陷更像是多类多目标跟踪,因为需要跟踪不止一种类型的缺陷,而大多数MOT方法只跟踪同一类的对象。因此,除了MOT方法中常用的对象运动和外观特征外,我们还将对象类信息,即缺陷类型,纳入跟踪算法中,这是大多数最先进的MOT方法所没有考虑的。
03
基于缺陷检测和度量学习的缺陷跟踪
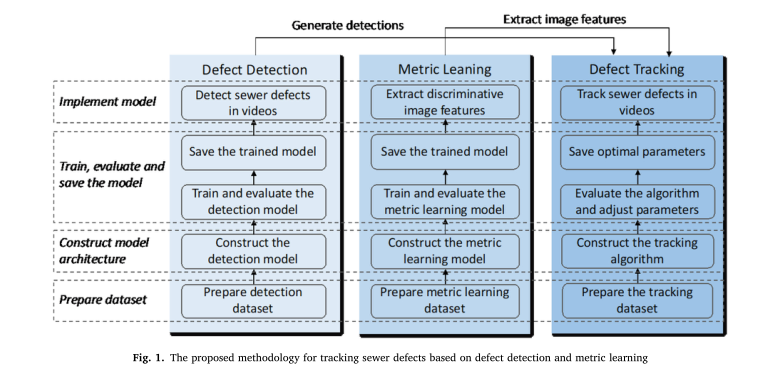
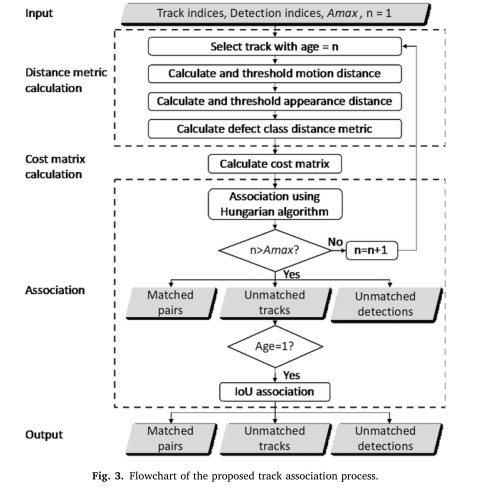
为了跟踪每一个缺陷并获得CCTV视频中唯一缺陷的数量,本文提出了一个跟踪多个下水道缺陷的框架。如图1所示,本文提出的框架中有三个主要模块,分别是(1)缺陷检测,(2)度量学习,(3)缺陷跟踪。检测模块利用包围盒检测视频中每一帧的缺陷,检测结果作为跟踪模块的输入。同时,度量学习模块的目的是训练一个能够提取下水道缺陷判别特征的模型,用于对视频中的缺陷进行重新识别。最后,跟踪模块通过度量学习模型提取检测到的缺陷的特征来跟踪缺陷,并根据外观特征、运动和缺陷类将检测与跟踪联系起来。对于每个模块,都有类似的过程,包括准备数据集、构建算法或模型架构、训练、评估和保存模型,以及实现模型以生成所需的结果。
04
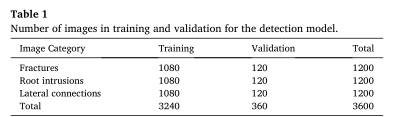
实验和结果
05
讨论
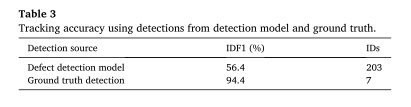
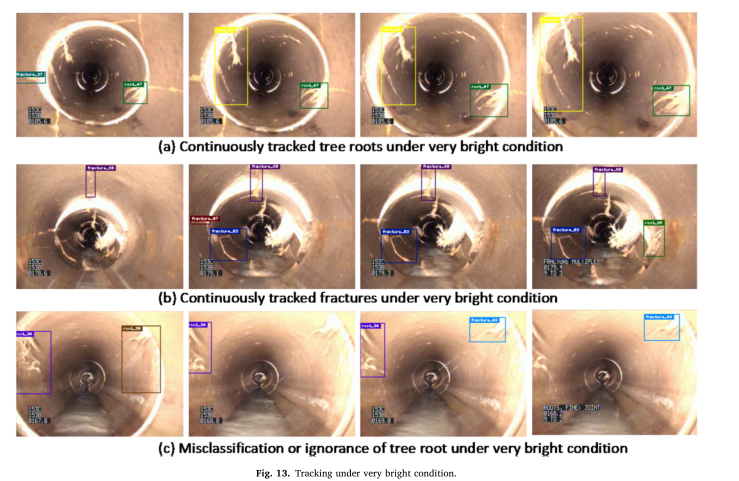
总的来说,实验结果证明了我们提出的框架能够在检查视频中跟踪多个下水道缺陷,并获得不错的IDF1分数。定性结果表明,即使在不同的摄像机运动和环境条件下,我们的模型也能够跟踪大多数视频中的缺陷。此外,实验定量结果表明,框架各模块的性能会在一定程度上影响整体跟踪精度。首先,我们在框架中采用了逐检测跟踪的方法,使得跟踪精度在很大程度上依赖于检测精度。基于地面真值检测的跟踪算法的IDF1达到94.4%,显著优于基于训练模型检测的算法。因此,提高下水道检测精度将是促进跟踪性能的优先事项。
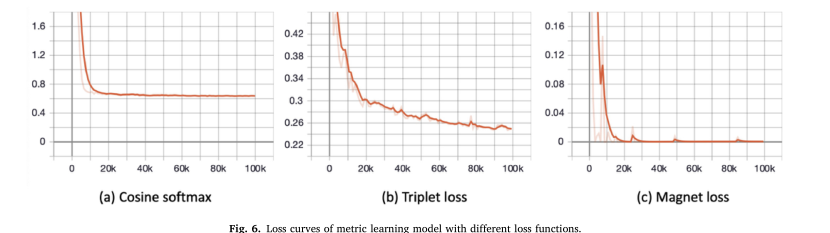
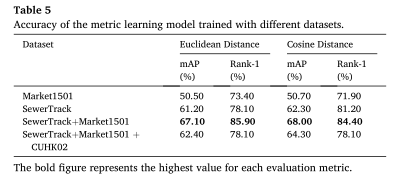
其次,由于度量学习模型用于提取跟踪过程中使用的特征,度量学习模型的质量也会影响跟踪结果。值得注意的是,图像匹配精度越高的度量学习模型,跟踪效果越好,尽管图像匹配精度越高,不一定跟踪效果越好。这可以部分归因于图像匹配任务中跟踪过程相对静态查询过程具有更多的动态特征。一般来说,可以采用不同的损失函数和多域数据集等策略来提高跟踪性能,减少数据准备工作。
06
结论
END

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述