
[灵魂拷问] MySQL面试高频100问(工程师方向)
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包
真爱,请设置“星标”或点个“在看”

来源:juejin.im/post/5d351303f265da1bd30596f9
前言
索引相关
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询.
hash索引不支持使用索引进行排序,原理同上.
hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测.AAAA和AAAAB的索引没有相关性.
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询.
hash索引虽然在等值查询上较快,但是不稳定.性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差.而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低.
select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询.使用不等于查询,
列参与了数学运算或者函数
在字符串like时左边是通配符.类似于'%aaa'.
当mysql分析全表扫描比使用索引快的时候不使用索引.
当使用联合索引,前面一个条件为范围查询,后面的即使符合最左前缀原则,也无法使用索引.
事务相关
脏读: A事务读取到了B事务未提交的内容,而B事务后面进行了回滚.
不可重复读: 当设置A事务只能读取B事务已经提交的部分,会造成在A事务内的两次查询,结果竟然不一样,因为在此期间B事务进行了提交操作.
幻读: A事务读取了一个范围的内容,而同时B事务在此期间插入了一条数据.造成"幻觉".
未提交读(READ UNCOMMITTED)
已提交读(READ COMMITTED)
REPEATABLE READ(可重复读)
SERIALIZABLE(可串行化)
表结构设计
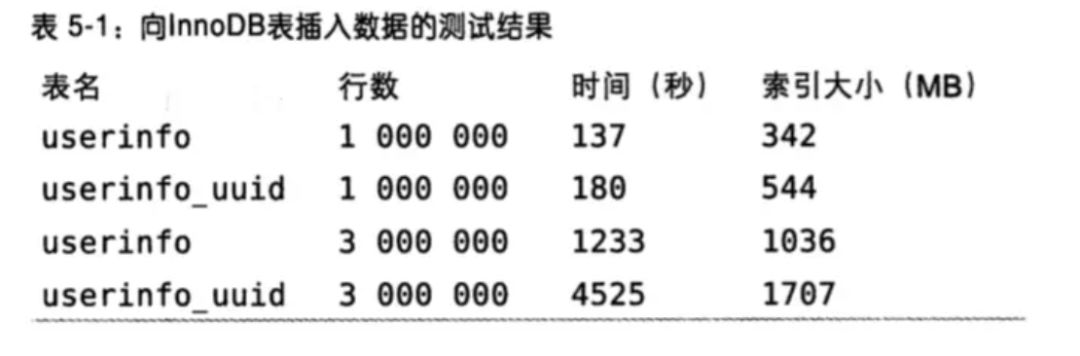
If you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. If you do not define a PRIMARY KEY for your table, MySQL picks the first UNIQUE index that has only NOT NULL columns as the primary key and InnoDB uses it as the clustered index.
NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
存储引擎相关
InnoDB和MyISAM有什么区别?
InnoDB支持事物,而MyISAM不支持事物
InnoDB支持行级锁,而MyISAM支持表级锁
InnoDB支持MVCC, 而MyISAM不支持
InnoDB支持外键,而MyISAM不支持
InnoDB不支持全文索引,而MyISAM支持。
零散问题
char(10)的空间,那么无论实际存储多少内容.该字段都占用10个字符,而varchar是变长的,也就是说申请的只是最大长度,占用的空间为实际字符长度+1,最后一个字符存储使用了多长的空间.statement模式下,记录单元为语句.即每一个sql造成的影响会记录.由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制.
row级别下,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大.
mixed. 一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row.
数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于
select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select * from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种,但是核心思想都一样,就是减少load的数据.从需求的角度减少这种请求….主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.

首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写.
分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引.
如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表.
id-摘要-内容.而系统中的展示形式是刷新出一个列表,列表中仅包含标题和摘要,当用户点击某篇文章进入详情时才需要正文内容.此时,如果数据量大,将内容这个很大且不经常使用的列放在一起会拖慢原表的查询速度.我们可以将上面的表分为两张.id-摘要,id-内容.当用户点击详情,那主键再来取一次内容即可.而增加的存储量只是很小的主键字段.代价很小.最后,这里再跟大家推荐一本程序员必知的硬核基础知识,这是一本非常入门的经典 PDF,看完能让你对计算机有一个基础的了解和入门,是培养你 内核 的基础,我们看下目录大纲

计算机基础 来领取这本 PDF。最近热文
• 突发!Windows XP 源代码泄露 • 为什么我强烈建议大家使用 Linux 开发? • 灵魂一问:一个TCP连接可以发多少个HTTP请求? • 保送北大,连发三篇Science,这位80后川妹子近日再发重磅级研究成果! 最近整理了一份大厂算法刷题指南,包括一些刷题技巧,在知乎上已经有上万赞。同时还整理了一份6000页面试笔记。关注下面公众号,在公众号内回复「刷题」,即可免费获取!回复「加群」,可以邀请你加入读者群!
明天见(。・ω・。)ノ♡