
马赛克,克星,真来了!

大家好,我是 Jack。
马赛克的克星,真的来了!
何恺明大神的新作,Kaiming 讲故事能力和实验能力,一如既往的强!
MAE 的论文,21 年的 11 月份就发出来了。
但是一直没有开源,我也就一直没有写文,最近代码发出来了,可以一睹为快了!
我们先说下 MAE 的任务:
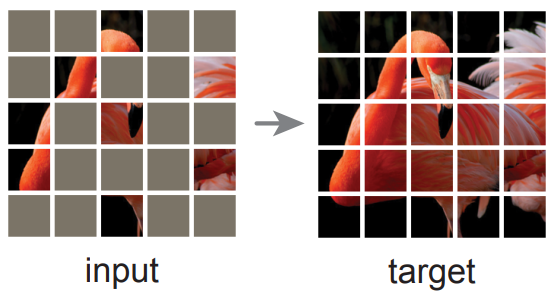
简单讲:将图片随机遮挡,然后复原。
并且遮挡的比例,非常大!超过整张图的 80% ,我们直接看效果:

第一列是遮挡图,第二列是修复结果,第三列是原图。
图片太多,可能看不清,我们单看一个:

看这个遮挡的程度,表针、表盘几乎都看不见了。但是 MAE 依然能够修复出来:
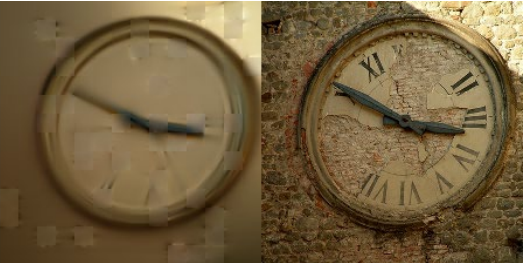
这个效果真的很惊艳!
甚至对于遮挡 95% 的面积的图片依然 work。

看左图,你能看出来被遮挡的是蘑菇吗??
MAE 却能轻松修复出来。接下来,跟大家聊聊 MAE。
MAE
MAE 的意义不仅在这个修复遮挡,去掉 mask 本身。
更在于为 CV 领域提供大一统的预训练模型提供了无限的想像。
做过 NLP 的小伙伴应该知道,在 NLP 任务中,Bert 已经一统江湖。
各子任务(如翻译、生成、文本理解等)均可使用相同的无监督预训练模型。
这保证了每个任务都能有非常不错的效果。
但在 CV 任务中,却各玩各的,分类任务有自己的无监督学习,检测任务有自己的无监督学习,每个 CV 领域的子任务,都有自己一套无监督学习,一直无法统一。
而 MAE 一出,可以想象大一统的 CV 无监督预训练模型的时代已不远矣。
可能这段话,一些刚入门的小伙伴看不太懂。
没关系,慢慢学。学了 Bert,你就明白这意味着什么了。MAE 就是类似 Bert 存在的东西,可以认为它就是 Bert 的一个 CV 版。
好久没有讲解算法原理了,今天简单讲解下 MAE。
Vit
讲解 MAE 之前不得不先说下 Vit。
红遍大江南北的 Vision Transformer,ViT。
领域内的小伙伴,或多或少都应该听说过。
它将 Transformer 应用到了 CV 上面,将整个图分为 16 * 16 的小方块,每个方块做成一个词,然后放进 Transformer 进行训练。
Transformer 的公式推导,原理讲解,我写过一篇文章,忘记的小伙伴可以先回顾下:
从 ViT 开始,CV 小伙伴们终于可以更优雅地使用 Transformer了。
MAE
MAE 结构设计的非常简单:
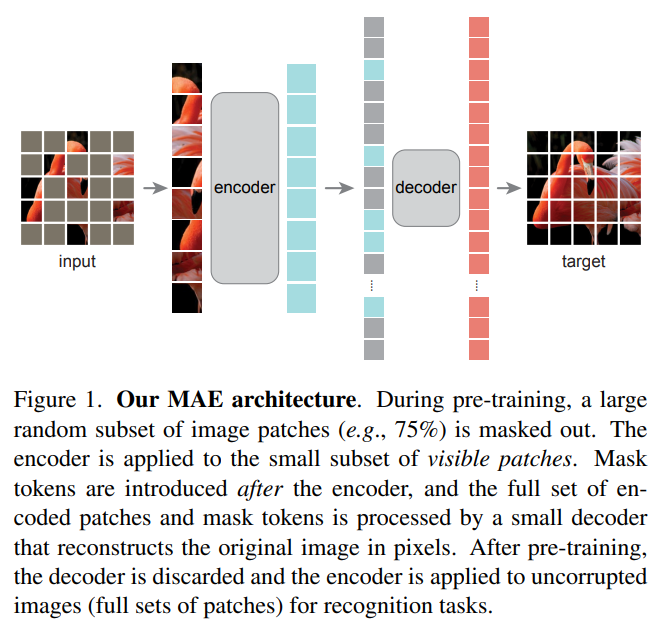
将一张图随机打 Mask,未 Mask 部分输入给 Encoder 进行编码学习,这个 Encoder 就是 Vit,然后得到每个块的特征。
再将未 Mask 部分以及 Mask 部分全部输入给 Decoder 进行解码学习,最终目标是修复图片。
而 Decoder 就是一个轻量化的 Transformer。
它的损失函数就是普通的 MSE。
所以说, MAE 的 Encoder 和 Decoder 结构不同,是非对称式的。Encoder 将输入编码为 latent representation,而 Decoder 将从 latent representation 重建原始信号。
熬夜写文时间有限,更详细的细节大家可以直接看看论文:
https://arxiv.org/abs/2111.06377
算法测试
官方刚刚开源6天,就已经获得了1.5k+的 Star,关注度可见一斑。
项目地址:
https://github.com/facebookresearch/mae
项目提供了 Colab,如果你能登陆,那么可以直接体验:
https://colab.research.google.com/github/facebookresearch/mae/blob/main/demo/mae_visualize.ipynb

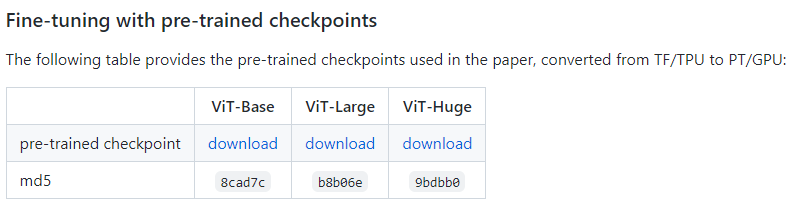
如果不能登陆,可以直接本地部署,作者提供了预训练模型。
如果环境搭建有问题的,可以参考之前我发布的一期视频:
https://www.bilibili.com/video/BV14R4y1g7qs
也可以加群探讨,很多新来的小伙伴在折腾开发环境。公众号后台回复加群,即可找到加群方式。
最后看下,我跑的效果:

这个修复效果,你打几分?
最后
MAE 可以用来生成不存在的内容,就像 GAN 一样。
我知道很多小伙伴,又有了一些“大胆”的想法,不过玩笑归玩笑,自己玩玩就好,大家还是要遵纪守法哦~

