
川普跳「鸡你太美」这么专业?一定是AI合成的
来源:机器之心
去年,来自上海科技大学和腾讯 AI Lab 的研究者的研究论文《Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis》入选计算机视觉顶会 ICCV 2019。经过一年的努力,该论文所提方法的改进版诞生了。先来看看效果如何?



论文地址:https://arxiv.org/pdf/2011.09055.pdf
GitHub 地址:https://github.com/iPERDance/iPERCore
项目主页:https://www.impersonator.org/work/impersonator-plus-plus.html
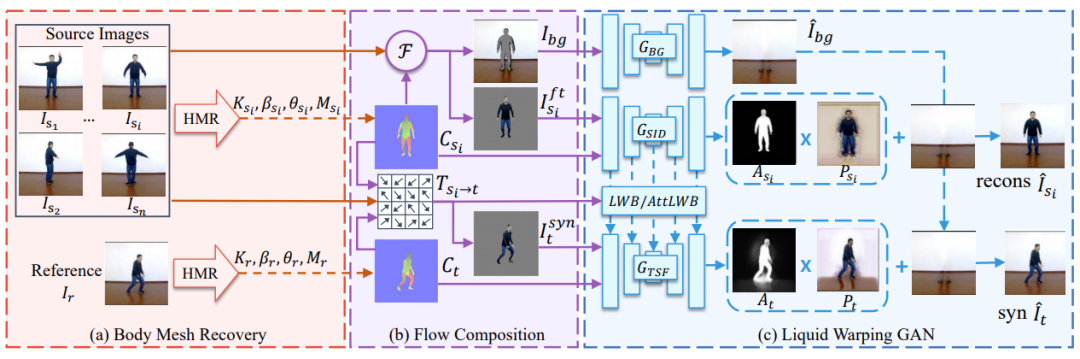
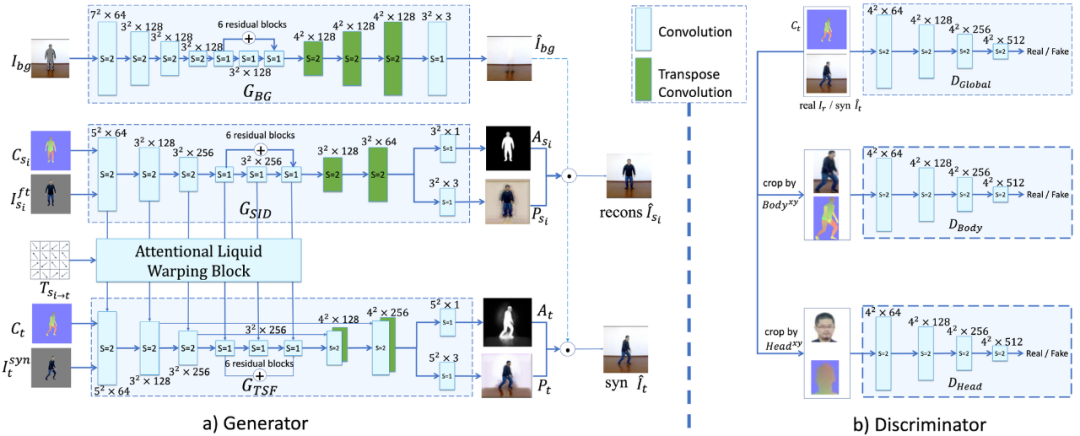
人体网格复原模块估计每个图像的 3D 网格,并渲染对应图 C_s 和 C_t。
流组成模块首先基于两张对应图及其在图像空间中的投影顶点来计算变换流 T。然后它将源图像 I_s_i 分离成前景图 I_s_i^ft 和背景蒙版 I_bg。最后该模块基于变换流 T 对源图像进行处理,生成扭曲(warped)图像 I_syn。
在 GAN 模块,生成器由 3 个流组成:生成背景图像的 G_BG、重建源图像的 G_SID、在参考条件下合成目标图像的 G_TSF。
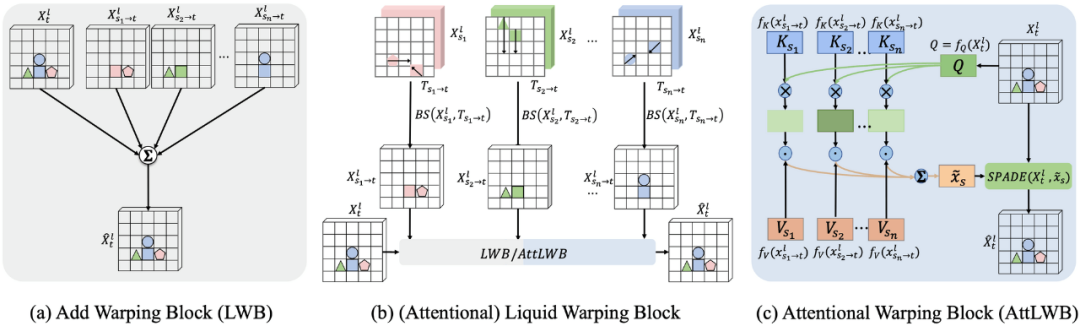
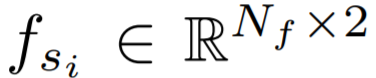 。
。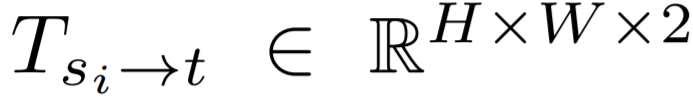 ,并以同样的方法计算参考对应图的变换流。
,并以同样的方法计算参考对应图的变换流。合成背景图像;
根据可见部分预测不可见部分的颜色;
从 SMPL 的重建中生成衣服、头发等像素。


微信扫描关注,查看更多内容
评论