
网易计费系统架构升级之路
项目背景
网易蜂巢计费系统为网易云计算基础服务提供整体的计费服务,业务范围涵盖完整的产品售卖流程,包含定价、订单、支付、计费、结算、优惠、账单等主体功能,支持十几种不同产品的售卖,产品形态上贯穿了IaaS、PaaS和SaaS类别。同时,计费方式还提供了了按量、包年包月、资源包等多种方式。该项目的业务范围之广,玩法种类之多,数据要求之严注定了它将成为一个烫手的山芋,而且还是一个吃力不讨好的工作。
该项目在人员上已经几经易手,就我所知,已经换过两拨完整的开发和测试团队了,而且已经全部离职。不得不说,该项目已经变得令人谈之色变,让人敬而远之。在这样的背景下,后期接手的开发和QA不得不硬着头皮上,踩着雷过河,小心翼翼的应对着不断涌来的业务需求。随之而来的是高居不下的bug率,越来越难以维护的代码,无法扩展的架构问题,我们开始意识到这样下去是不行的。于是我们从8月份开始了漫漫的架构升级之路。
重新出发
在我们开始优化架构之前,我们重新梳理了计费系统完整的业务,得到了如下图所示的业务领域: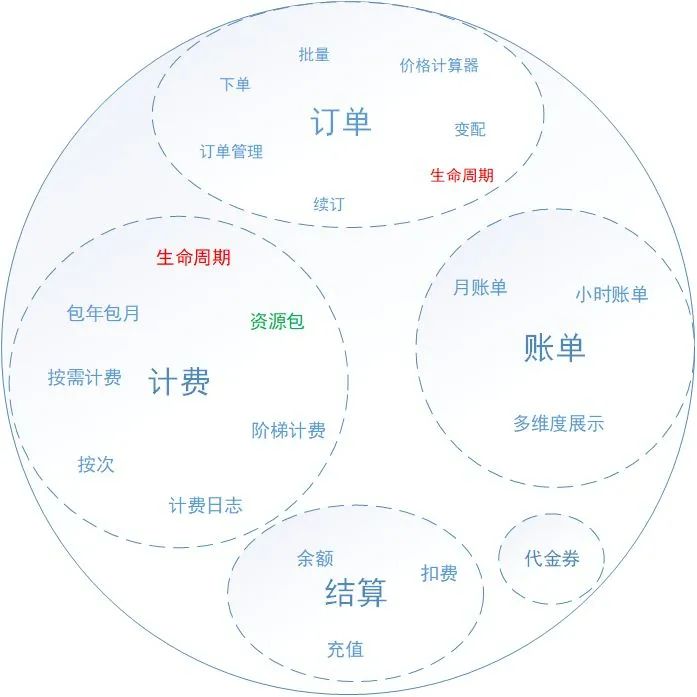
梳理以后发现,计费系统承载了太多非计费的业务,包含订单、账单、结算和代金券等,这些业务代码散落在各处,没有严格地业务边界划分,而是“奇迹般”的融合在了一个工程里面。造成这个局面的原因在于计费系统初版设计时,根本没有考虑到这些问题,当然也不可能考虑到,而在后面逐步地迭代过程中,也未能去及时地调整架构,架构腐化不是一天内完成的。当然,这方面有部分技术的原因,也有部分人为的原因所在,因为当时负责计费系统的开发就只有一人,还是刚毕业的同学。目前看来,也是难为这位同学了。
技术债务的问题不是小事,千里之堤毁于蚁穴。既然我们找到了问题的症结所在,那么解决的方式也就显而易见了,一个字:拆!我们分析了所有的业务,订单是最大也是最复杂的一个业务,而结算和账单考虑到后期有可能迁移到云支付团队,我们决定优先把订单系统拆分出去!
拆分的阵痛
订单拆分说起来容易,做起来难。套用一句业界常说的话,就是开着飞机换轮胎。因为在我们拆分的同时,不断地有新的业务需求进来,还有一些bug需要处理,所以不太可能让我们专门进行拆分的工作。因此,为了不影响正常的业务迭代,我们决定拉出独立分支进行开发。我们分出两人专门处理拆分的工作。
为了最小化风险,订单拆分我们分了两步进行:一,模块独立;二:系统独立。
模块独立
模块独立是将订单的代码首先在工程内部独立出来,我们采用独立Module的形式,将订单独立成了一个Order的模块。它拥有完全独立的服务层、业务层以及持久化层。其他模块可以依赖Order,而Order不能依赖除公共模块外的其他业务模块。整体的模块划分如下图所示。模块的拆分过程中我们也发现了原先很多不合理的地方,例如:其他服务直接操作订单的持久化层(DAO)、模块直接依赖关系混乱、Service所在的Pacakge不合理、存在大量无用的代码和逻辑、随意的命名等。我们边拆分边重构,虽然进度比预期要缓慢一些,但整体上在向着合理的方向进行。
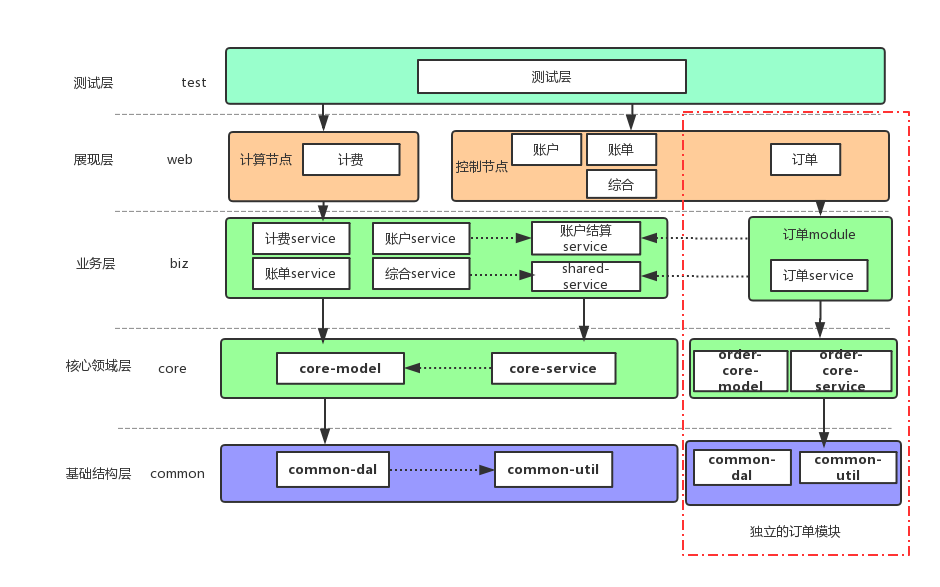
模块独立的过程中我们遇到了业务层级关系的问题。由于订单模块不再依赖于其他业务模块,而又有一些业务逻辑是由订单触发的,需要在计费模块完成,我们又不能直接调用计费模块的Service。针对这个问题,我们采用了领域事件的方式来解耦,简单来说就是订单通过发布事件的方式来与其他模块进行通信,当时实现的代码其实也相当简单。
我们并没有独立拆分web层,因为系统还没有独立,web层作为统一的打包入口也承载着订单的流量。而且,Controller层的逻辑相对比较简单,完全可以在系统独立时再做。通过大家的努力,8月底订单已独立模块的方式上线了,一切正常。
系统独立
模块拆分完成后,紧接着就是系统独立,此时我们需要将订单系统独立部署。这里一个关键的问题是,独立部署意味着单独提供服务,而依赖订单系统的业务方非常之多,包含前端、主站、大部分的PaaS业务和计费,都有需要直接依赖订单接口的地方,贸然独立风险很大。针对这个问题,我们采用使用haproxy七层转发代理来将流量分发到不同的vip来解决。虽然,在上线过程中遇到了一些坎坷,但最终还是成功了。现在看来这个选择是非常对的,因为这样可以在业务方无感知的情况下平滑升级。但长远来看,最终我们还是以独立的vip对外保留服务。
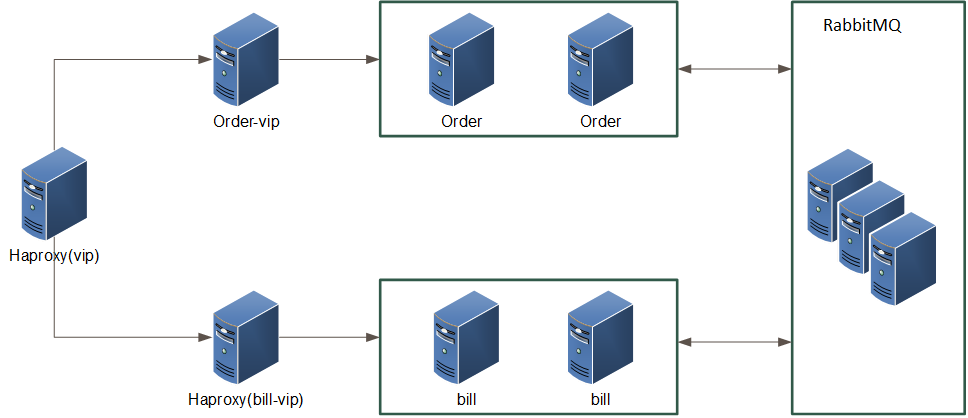
订单和计费直接我们采用RabbitMQ来完成主体通信,关于采用MQ还是HTTP调用我们内部还进行了一番争论。之所以最终还是采用MQ来进行通信,是因为我们发现很多业务流程并不需要计费系统立即响应(大部分流程都是订单触发的),也就是我们常说的弱依赖。另外,职责上计费系统的响应的质量也不应影响到订单的主体流程,举个例子:用户支付了一个云主机的订单,如果计费系统此时无法响应,业务上相对来说可以接受过一小会儿计费再处理,而不是把订单直接退款给用户。MQ的引入在技术和职责层面都将订单和计费分的更开了。当然,强依赖的服务是我们无法避免的,其中之一就是结算模块还留在计费中,订单需要通过接口调用结算服务来完成支付。
前期,我们在模块独立时采用事件解耦的方式,在此时也获得了收获。我们通过一个统一的转化层,将那些事件直接转化层RabbitMQ可以识别的消息,这样代码的改造工作就大大减少了。
系统独立后一个直接的表象就是每个系统的代码行数大大降低了。独立前,整体的代码行数已经达到了12W行以上(包含配置文件),独立后,计费系统降低到了10W以下,订单维持在4W以下。代码行数的降低将直接提高系统的可维护性。个人认为如果一个工程里的代码超过10W行,那么维护性将大大降低,除非是那些有着严格自律意识的团队,否则,我建议还是尽量降低代码行数。
经过大家一个月的努力,订单系统终于已独立的姿态提供服务了。过程很艰辛,但是收获良多。
拆分的收获
订单独立后,一个直接的好处就是我们能独立的思考问题了,这在以前是很难做到的一件事情,因为大家不得不小心翼翼的处理那些依赖,做事会畏手畏脚的。另外一个好处就是,我们的工作可以有侧重点的进行了。订单业务可以说是产品最为关注的业务,也是计费对外暴露的主要入口。下图就是我们在拆分后规划订单的业务架构,大家对后期的订单规划充满期待。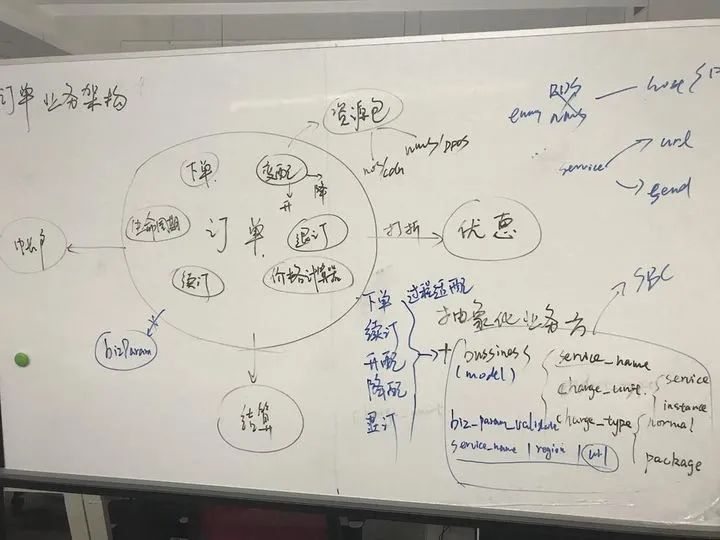
多Region的挑战
公有云产商面临的一大挑战就是多Region环境的支持。普通的互联网行业出于高可用的考虑,往往会把核心系统部署到多个机房,然后根据自己的实际应用场景选择冷备、双活甚至三活。我们经常听到的“两地三中心”、“三地五中心”等等高大上的名词就是多机房高可用的缩影。这些行业做多机房部署的主要目的是为了提高系统的可用性,不是其业务的必须属性。换句话说,他们不做多机房部署也可以,做了当然更好。而公有云产商不一样,多Region部署就是其行业属性之一。如果哪个云产商不提供多region产品的支持,那么它肯定是不完整的。不得不承认,我们在这方面的经验是比较欠缺的,在多Region的支持上走了一些弯路。
摸着石头过河
今年上半年的时候,蜂巢开始计划启动北京Region,预计年中交付,当时对我们横向业务提出了很大的技术挑战。一是在于横向系统设计之初并没有考虑到对Region环境的支持,我们很被动;二是我们并没有跨Region系统设计的经验,我们很着急。计费系统面临的问题更加严重,因为它对数据的一致性要求更高,而且出错的影响范围也更大。而且当时计费的技术债务已经很高了,产品的需求列表也拍了很长,套用一句很形象的话说,“留给我们的时间不多了”。
在这种情况下,我们“胆战心惊”的给出了第一版的多Region设计方案,主体架构如下所示:
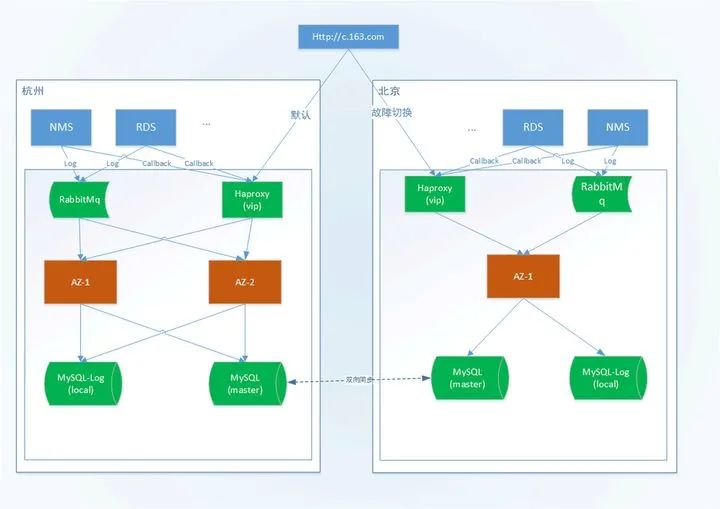
因为当时计费系统还没有拆分,所有的业务都在一个系统中完成的,就是我们常说的“大泥球”系统。这种情况下我们很难做到多Region部署,订单和账单其实只有在一个Region部署就可以了,而计费的数据采集和请求分发是要下沉到各个Region的,而计算过程可以集中完成。采用"双主"同步复制的方案实则是无奈之举。数据库的同步只能基于实例级别,而无法细分到表,我们各Region中计费数据库中存在资源的计量表,这个数据需要同步到杭州Region来完成。为了避免“脑裂”的问题,我们特别将该表的主键采用UUID的形式。存量表因为无法做大规模修改,我们通过限制北京MySQL用户的权限来避免写入和修改全局表。
这个设计很糟糕,但是当时的条件限制,我们也拿不出更好的设计了。虽然上线的过程有些曲折,这个架构还是成功运行了,这是令我们最为欣慰的事情。因为为了适配这个架构,团队的小伙伴做了很多工作。不可否认,这个架构存在诸多弊端,其中最大的隐患就在于数据库的“双主”同步,这就像一颗随时会爆的炸弹萦绕在我们心头。当时专线还没有搭建好,所有的流量均通过外网隧道代理,糟糕的网络质量无疑放大了这个风险。为此,DBA们向我们吐槽了好久,幸好我们抗打击能力很强。
涅槃重生
在做完双Region的支持以后,计费团队就继续做产品需求了,因为架构调整导致需求列表已经很长了。而且当时也说的是,短期内(至少今年)不会再有第三个Region了,我们也想着快点做完,多花点精力投入到重构中。但是计划赶不上变化,9月底我们被通知到第三个Region来了,而且已经被提高到第一优先级支持了。
有了第一版双Region的经验,这一次我们淡定了很多。当然,我们不可能在沿用第一版的设计了,因为DBA就会跟我们拼命的。回过头来梳理多Region支持面临的问题时,我发现一开始我们就自己给自己挖了一个坑,然后往里面跳。横向支撑系统显然都需要对所有Region提供支持,但这并不代表其需要在各个Region内部署(我还与团队其他的小伙伴分享了这方面的想法,网上应该还能找到这一次分享的ppt——《跨Region实践初探》)。因为公有云产商经常会提供多个Region的服务,有得甚至达到几十个Region,如果横向支持系统每个Region都要全量部署的话,那么我们花在运维上的精力就可以拖垮我们,更不要说还有最为困难的数据的一致性问题。
其实多Region的支持的问题我们总结出主要表现在一下两个方面,一是应用层面的接口互通;二是底层数据库的同步。
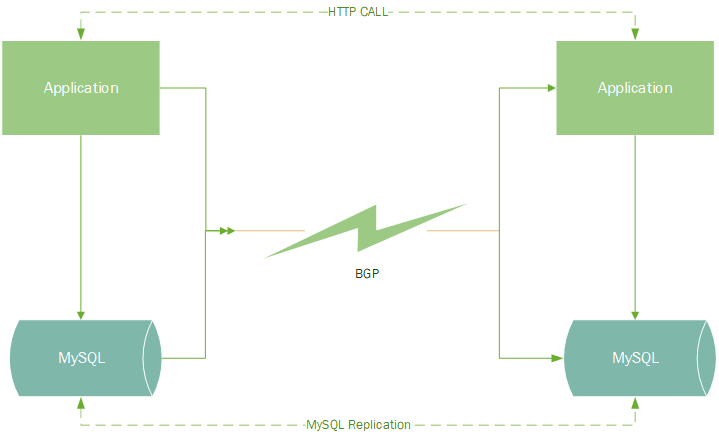
我们先说底层数据库的同步,对计费系统而言,数据的一致性是至关重要的,但多机房部署是在挑战CAP定律。是不是就没有了这样的数据库方案了呢,有,那就是Google的Spanner,号称可以在全球做到强一致的数据库。但是我们没有这样的数据库。其实我们也考虑使用NoSQL数据库——Cassandra,但是这个数据库运维起来太复杂,我们也没有这方面的经验,也就放弃了。还是回归到MySQL,受限于传统关系型数据库在扩展性方面的问题,我们不可能把整个库在各个Region都同步一份。但是计费原始数据又必须在各个Region内收集,于是我们决定——拆,把计费拆分成两个部分,分为bill-agent(数据采集)和bill-central(数据计算)两个部分。
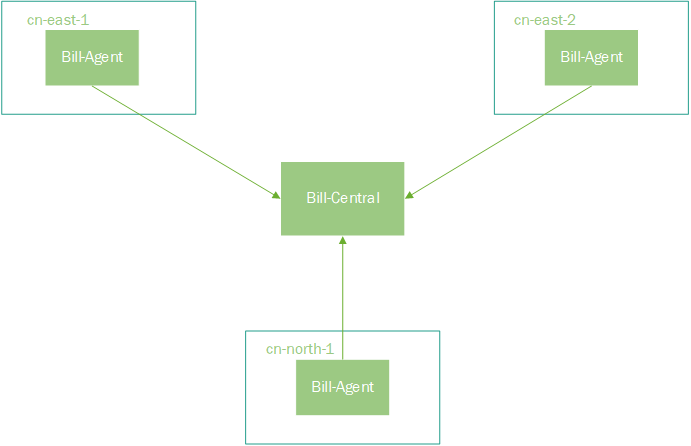
Bill-Agent负责Region内日志的收集和简单聚合。
Bill-Central负责日志收集外的全局事务处理。
通过这样的拆分,架构就清晰多了。再多加Region,我们只需要部署Bill-Agent就可以了。Bill-Agent将处理过的计费数据写入本地库的一张资源表,利用NDC(马进在网上分享过关于这个中间件的介绍)将资源表单向同步到Bill-Central的中央库,然后Bill-Central统一在对计费数据进行处理。有意思的是,这张资源表就是我们在第一版设计中新建的资源表,因为我们将主键修改为UUID,所有使用NDC同步表的方案是相当顺利的。当然,NDC在我们其他项目的跨Region支持上也发挥了重要作用,比如:跨机房缓存更新的问题。这一版的数据库方案在技术评审时大家都比较满意,DBA也肯定了我们的方案。
现在再来看跨Region调用的问题。在多Region的横向系统中,我们发现或多或少的存在着机房间的接口调用问题。这些问题有可能是某些Region的库不能写需要路由到主库来写导致的,也有可能是全局缓存的问题,还有就是Global业务向Region内服务发送指令。计费属于最后一种场景,我们有一些业务场景需要由杭州Region触发,然后调用各个Region内的服务的接口。在第一版的实现中,计费系统自己实现了跨Region代理部分,但是实现的不是很好,代码的可维护性比较差,加重了调试的难度。这一版的设计中,我们决定把跨Region接口代理单独拿出来重新做,结合多Region的应用场景,然后封装一些非功能性的特性,这就成了后面我们很重要的一个组件——RegionProxy。
RegionProxy最开始是为了解决跨Region调用的非功能性问题,简化应用系统处理的成本。但是设计上经历了比较大的调整。最开始的设计我们是希望Region内所有跨Region的HTTP调用都能通过RegionProxy来代理,RegionProxy之间能够发现对方并且相互通信,那么Region内的应用系统就只需要与本Region的RegionProxy通信就可以调到任意一个Region的应用系统了。但是在方案评审的过程中,我们发现如果都用RegionProxy代理,可能会导致跨Region调用多出一跳或者两跳,调试可能会比较困难。后来,我们放弃了这个方案。再后来,我们发现ServiceMesh的方案和我们最初RegionProxy的方案是十分相似的。
在RegionProxy的设计上我们进行了简化处理,我们将所有Region的业务系统录入到一个全局的配置中心(我们自己开发的ConfigCenter)中,然后通过一个自己开发的一个HttpProxy的Java库来与ConfigCenter通信来完成跨Region的调用。这样做的好处就是使用方用起来比较轻量,但是在网络连通性方面我们需要与所有Region的系统做到互通。在开发Proxy库的时候,我们不仅对跨Region的HTTP调用进行了封装,而且对普通的HTTP调用也加入了非功能性的封装,这样系统可以通过Proxy库完成所有的HTTP调用请求,极大的简化了代码的维护成本。后面,我们使用RegionProxy来代理请求后,确实删除了很多以前的无用代码,整体流程上也清晰了许多。
多Region的感悟
经过两版多Region的改造,我们确实收货了很多宝贵的经验,非常难得。实际上,在多Region的支持上,大家需要清晰地认识到为什么要支持多Region,以何种方式去支持多Region,多Region支持与高可用的关系等基本问题。如果这些问题回到不好,或者不清楚,那么很容易就会掉到陷阱中去。另外一个感悟就是结合业务的实际场景,第二版的多Region架构我们之所以能够这么设计,就在于计费系统不需要实时出账,我们完全可以把数据保存下来,离线计算以后再出账,这是可以接受的。但这并不适用于所有情况,有些性能要求很高的横向业务就不适合这种场景。
拿来主义
前面提过几次技术债务的问题,有些问题是可以通过工具来解决了,有些只能通过内部重构来解决。左耳朵耗子曾经说过一句话对我感触很大,大意是说有些公司在解决问题时偏流程,有些公司偏技术。我想我们既然是技术团队,在解决问题时能通过技术方式解决的就应该尽量用技术解决,流程和人都是不可靠的。
难以管理的配置文件
计费项目面临的诸多问题之一就有配置文件的管理,因为业务流程的原因,计费系统有着大量的各种各样的配置。以前我们把配置文件放到工程里面,通过自动化部署平台来指定使用不同的配置文件。这样做的一个显著问题就是代码和配置耦合起来了,每次修改什么配置都得提交代码,而我们提交又有着一套严格的流程,导致整体效率不高。另外一个问题就是可视化的问题。往往QA在线下环境测试都是通过的,而上线以后出了问题,基本上都是配置导致的问题。针对这几个的问题,我们决定使用Apollo来管理我们的配置,
替换定时任务框架
计费系统严重依赖于定时任务,有许多流程需要通过定时任务来推动。以前我们使用QUARTZ+MYSQL来作为我们分布式定时任务框架,但是这种做法的可维护性太差,而且对数据库侵入很高,对测试也不友好。在QA的不断吐槽中,我们决定替换掉现有的定时任务框架。在调研开源的定时任务框架后我们决定使用Elastic-Job来作为我们的分布式定时任务框架。目前,我们的两个项目的所有定时任务(除bill-agent外)都已迁移到Elastic-Job上来了。
抽象化设计
如果你要问我做蜂巢计费最困难的地方是什么?我的回答肯定是业务太复杂了。这种复杂性不是因为我们架构设计的不好导致的复杂,而是业务本身就是十分复杂的。现在计费系统需要支持十几种产品的售卖形式,涵盖IaaS、PaaS和SaaS的绝大部分产品,同时各个产品的售卖和计费模式都存在或多或少的差异,这让我们很难通过一个统一的模型就涵盖所有的场景。我们找到了一条缓解这个问题的方式——抽象化。
横向系统或者支持系统如果需要服务多个产品,那么抽象化设计是不可或缺的缓解。如果越早进行抽象化,那么后期对接和维护的成本也就会越低,还能把系统的边界划分得更清晰。计费系统早期的设计在抽象化方面没有过多的规划,在后期的对接方面又处于比较弱势的一方,导致计费系统出现了大量的特化代码。这些特化代码对一个服务十几个产品的支持系统无疑是伤害巨大的。现在我们已经意识到了问题的严重性,也着手在做这方面的重构工作了。但是挑战依然很大,因为业务的复杂性是无法通过技术手段就能降低的,这方面我们只有和产品、运营和销售各方面一起努力,打造一个合理、灵活、稳定的新计费。
推荐阅读: