
全新FPN | 通道增强特征金字塔网络(CE-FPN)提升大中小目标检测的鲁棒性(文末附论文)
共 14908字,需浏览 30分钟
·
2021-03-24 18:48

本文提出了一种新的通道增强特征金字塔网络(CE-FPN),实验表明,CE-FPN在MS COCO基准上与最先进的FPN-based的检测器相比有所提升。
1 简介
特征金字塔网络(FPN)已成为目标检测中提取多尺度特征的有效框架。然而,目前FPN-based的方法大多存在Channel Reduction的固有缺陷,导致语义信息的丢失。而融合后的各种特征图可能会造成严重的混叠效果。
本文提出了一种新的通道增强特征金字塔网络(CE-FPN),该网络由3个简单而有效的模块组成。具体来说,受亚像素卷积的启发,提出了一种既实现Channel增强又实现上采样的sub-pixel skip fusion方法。它代替了原来的 卷积和线性上采样,减少了由于Channel Reduction而造成的信息丢失。然后,然后本文还提出了一种sub-pixel context enhancement模块来提取更多的特征表示,Sub-pixel Convolution利用了丰富的通道信息,优于其他context方法。
在此基础上,引入了一个通道注意力引导模块对每一层的最终集成特征进行优化,从而在较少的计算量下减轻了混叠效应。实验表明,CE-FPN在MS COCO基准上与最先进的FPN-based的检测器相比,具有竞争性的性能。
2 方法简介
2.1 Information loss of channel reduction

图1(a)中FPN-based的方法采用1×1 convolutional layers对backbone的输出特征映射 进行Channel降维,丢失了Channel信息。 通常在高级特征映射中提取数千个通道,这些通道在 中被缩减为一个小得多的常数(比如说2048缩减为256)。


现有的方法主要是在Channel Redection映射上增加额外的模块,而不是像图1(b)、1(c)所示的充分利用 。EfficientDet开发不同FPN通道的各种配置。这表明,增加FPN通道可以提高性能,同时增加更多的参数和FLOPs,所以EfficientDet仍然采用相对较少的通道,并提出了复杂连接的BiFPN以获得更好的精度。因此,从主干网输出的Channel Redection大大减少了后续预测的计算消耗,但也带来了精度损失。
2.2 Information decay during fusion
在目标检测中, low-level和high-level是互补的,而在自顶向下的特征融合过程中,语义信息会被稀疏化。
PAFPN和Libra R-CNN提出了融合方法,充分利用每一层的特征。然而,high-level语义特征的表征能力并没有被广泛应用于更大的感受野。而利用context信息是一种改善特征表示的比较好的方法,它避免了直接添加更深的卷积层而带来的计算负担。
2.3 Aliasing effects in cross-scale fusion
Cross-scale fusion和skip connections已经被广泛用于提高模型的性能。简单的连接实现了在每个层次上的各种功能的充分利用。
然而,Cross-scale特征图存在语义差异,插值后直接融合可能会产生混叠效应。各种综合特征可能会混淆定位和识别任务。通过对融合特征的非局部注意的细化,可以设计更多的注意模块来优化融合的混叠特征,提高其识别能力。
3 本文方法
3.1 overall
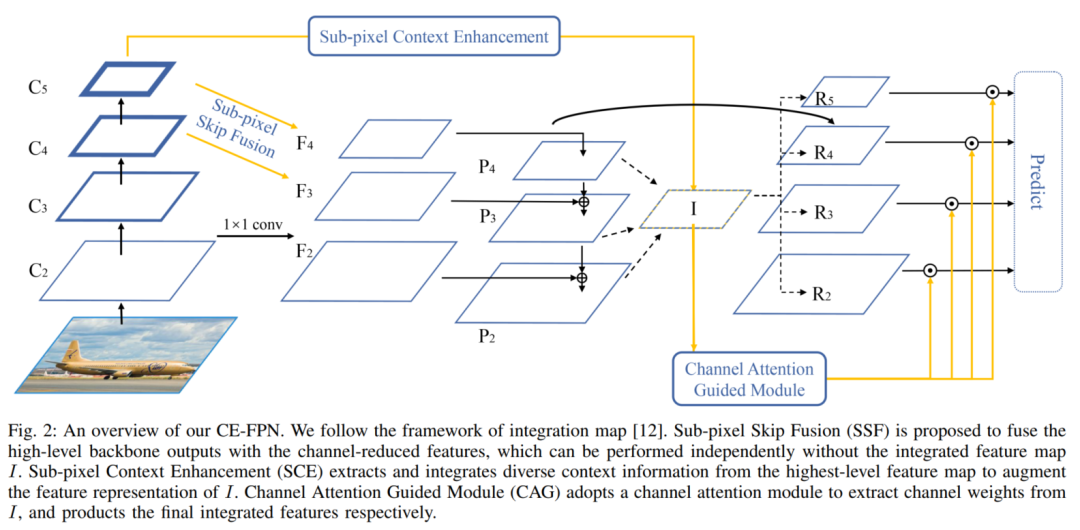
整体网络架构如图所示。根据FPN的设置,CE-FPN生成一个4级特征金字塔。表示主干的输出为 ,它们相对于输入图像有 像素的stride。 是经过 卷积后,Channel Redection后256维度的特征。特征金字塔 是通过FPN中的自上而下通路产生的。
作者去掉了 和 的节点,这2个节点是FPN原始的具有语义信息的最高级特征。因为提出的方法充分利用了来自 的Channel信息。重复的特征融合不仅会造成更严重的混叠效果,而且会造成不必要的计算负担。所有最终结果 都独立执行预测,这与原始FPN的特征金字塔相对应。
3.2 Sub-pixel Skip Fusion
在FPN中,残差网络被广泛用作骨干网络,输出通道为{256,512,1024,2048},其中high-level特征 包含丰富的语义信息。

如图3(a)所示,为了提高计算效率,采用 卷积层来降低 的Channel维数,导致Channel信息严重丢失。进一步研究的FPN-based的方法一般集中在256个Channel的特征金字塔 上开发有效的模块,而 的Channel信息丰富却没有得到充分利用。
基于这一观察,作者期望可以开发丰富通道的特征 来提高得到的特征金字塔的性能。为此,引入了一种直接融合方法,将低分辨率(LR)特征与高分辨率(HR)特征融合在一起。亚像素卷积是一种上采样方法,它通过对channel的尺寸进行变换来增加宽度和高度的尺寸。像素shuffle操作符将形状 的特征重新排列为 ,数学上定义为:

其中,r为upscaling factor,F为输入特征, 为坐标 位置的特征像素。

如图b所示,在使用亚像素卷积进行上采样时,首先需要增加LR图像通道的尺寸,这带来了额外的计算量。HR图像是不可靠的,需要额外的训练。因此,FPN采用了最近邻上采样。然而,作者观察到 (1024,2048)中的通道数量足以执行亚像素卷积。
因此引入了亚像素跳变融合(SSF),在不进行channel缩减的情况下直接对LR图像进行上采样,如图3(c)所示。

SSF利用 丰富的channel信息,并将它们合并到 中,描述为:

其中 为减少信道的1x1卷积,i为金字塔层的指数, 为channel变换。采用亚像素卷积中的因子r作为2,使空间尺度加倍进行融合。采用1×1卷积或分割操作改变通道尺寸,实现双亚像素上采样。如果通道维度满足要求, 执行id映射。然后 通过元素求和和最近邻上采样得到与FPN相同的特征金字塔 。
如网络架构图所示,SSF可以看作是 到 和 到 的2个额外的连接。SSF同时进行上采样和channel融合,然后利用high-level特征 丰富的channel信息,增强了特征金字塔的表示能力。
3.3 Sub-pixel Context Enhancement
一方面,传统的FPN通过融合来自high-level的语义信息,自然地赋予low-level特征图不同的context信息;但最高级的特征只包含单一尺度的context信息,不能从其他信息中获益。
另一方面,高分辨率的输入图像需要具有更大感受野的神经元来获取更多的语义信息,以捕捉大的目标。
为了解决这两个问题,作者采用了融合映射的框架,并引入了亚像素上下文增强(Subpixel Context Enhancement,SCE),在 上利用更多的context信息和更大的感受野。将提取的context特征融合到集成图I中。

如图4所示。SCE的核心思想是融合大域局部信息和全局context信息,生成更具判别性的特征。假设输入特征图 的形状为 ,输出的积分图I为 。C采用256。通过如下的平行路径执行3个context特征量表。
第1步
在C5上应用3×3卷积来提取局部信息。同时,对通道尺寸进行变换,实现亚像素上采样。然后采用亚像素卷积进行双尺度上采样;
第2步
输入特征通过3×3的最大池化下行采样到w×h,并经过1×1卷积层来扩展Channel维度。然后进行4个亚像素卷积上采样。这个pathway可以为更大的感受野获得丰富的context信息。
第3步
在C5上对全局context信息执行全局平均池化。然后,得到了1×1×8C被压缩到1×1×C,并广播到大小4w×4h的feat map。第1和第3条路径分别提取局部和全局context信息。
第4步
3个生成的特征映射将按元素的总和聚合到集成映射I。通过扩展3个尺度的特征表征,SCE有效地扩大了 的感受野,提高了I的表征能力。因此,最高级特征中的语义信息在FPN中得到了充分的利用。为了简单起见,删除了 和 的节点。
3.4 Channel Attention Guided Module
跨尺度特征map存在语义差异,综合的特征可能会产生混叠效应,混淆定位和识别任务。在FPN中,每一个合并的特征映射都要进行3×3的卷积,生成最终的特征金字塔。
本文提出的SSF和SCE融合了更多的跨尺度特征,使得混叠效应比原来的FPN更加严重。为了减轻混叠的负面影响,一个直观的解决方案是在特征金字塔上应用注意力模块。然而,在金字塔的每一层执行独立的注意力模块会带来巨大的计算,因为一些检测器采用6级金字塔甚至更多。同时,作者期望不同层次的注意机制能够从其他层次的信息中学习。
为此,作者提出了一个受CBAM启发的通道注意引导模块(CAG),它可以引导金字塔的各个层次来缓解混叠效应。CAG只通过集成映射I提取Channel权值,然后将Channel权值乘以每个输出特征。
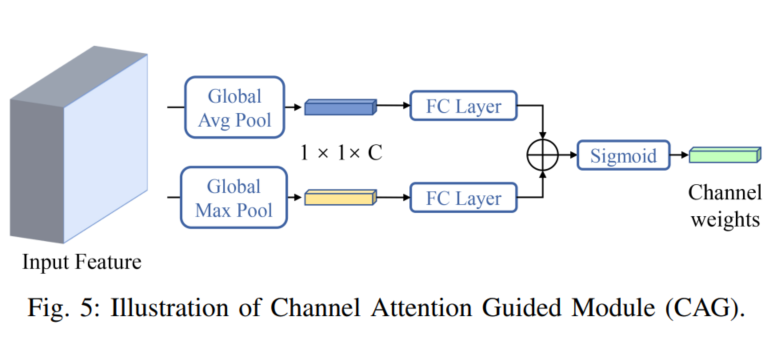
CAG的流程如图5所示。首先分别使用全局平均池化和全局最大池化来聚合2种不同的空间context信息。接下来,这2个描述符分别被转发到FC层。最后,通过元素求和和sigmoid函数对输出特征向量进行合并。该过程可以表述为:

其中CA()为通道注意函数, 为sigmoid函数,i为金字塔级指数。
CAG的设计只是为了减少混叠特征的误导,而不是通过复杂的架构来增强特征的更有区别性的能力。因此,轻量级计算是设计的核心,而且CA()对其他注意力模型来说也是鲁棒的。
4 实验结果
4.1 COCO数据集实验
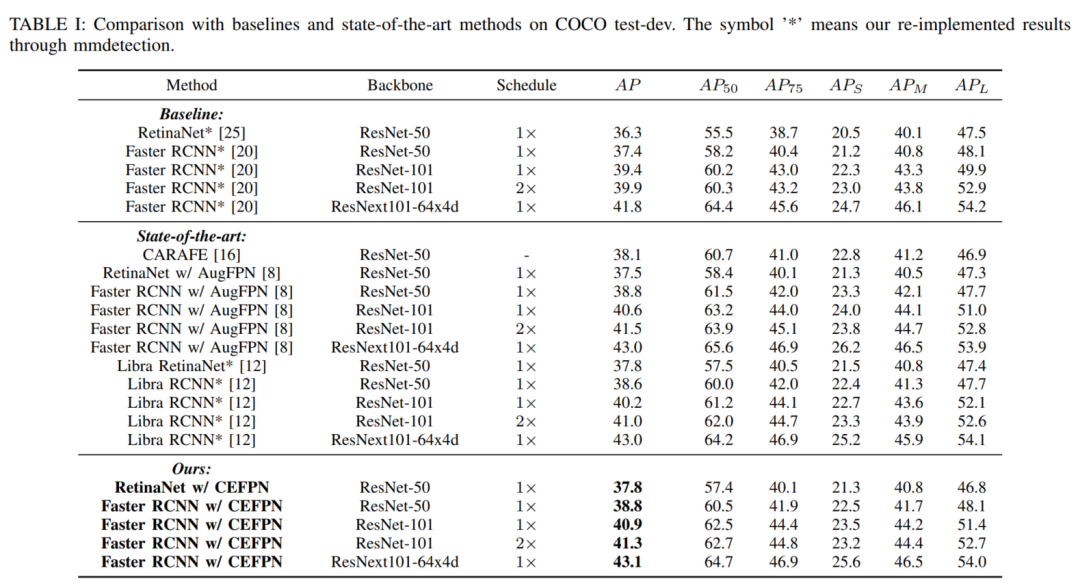
如表所示,CE-FPN替代FPN后,以ResNet-50和ResNet-101为骨干的Faster R-CNN分别达到38.8和40.9AP,分别比baseline高1.4和1.5点。当使用ResNext101-64x4d backbone时模型达到43.1AP。

通过图6可以看出CE-FPN对小、中和大的目标都可以得到满意的结果,而典型的FPN产生较差的结果。典型的FPN模型偶尔会遗漏一些目标,因为这些目标可能太小。
6 参考
[1].CE-FPN: Enhancing Channel Information for Object Detection
7 推荐阅读
CVPR2021全新Backbone | ReXNet在CV全任务以超低FLOPs达到SOTA水平(文末下载论文和源码)
你的YOLO V4该换了 | YOLO V4原班人马改进Scaled YOLO V4,已开源(附论文+源码)
CVPR2021-即插即用 | Coordinate Attention详解与CA Block实现(文末获取论文原文)
Backbone | 谷歌提出LambdaNetworks:无需注意力让网络更快更强(文末获取论文源码)
最强检测 | YOLO V4?都是弟弟! CenterNet2以56.4mAP超越当前所有检测模型(附源码与论文)
本文论文原文获取方式,扫描下方二维码
回复【CE-FPN】即可获取论文
长按扫描下方二维码加入交流群
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()