
Java 8 中 HashMap 到底有啥不同?
点击关注公众号,Java干货及时送达
作者:废物大师兄
来源:www.cnblogs.com/cjsblog/p/8207211.html

JDK1.8中的HashMap实现跟JDK1.7中的实现有很大差别。
下面分析JDK1.8中的实现,主要看put和get方法。


构造方法的时候并没有初始化,而是在第一次put的时候初始化:

putVal方法的主要逻辑是这样的:
2、通过hash方法计算key的hash值,进而计算得到应该放置到数组的位置
5、如果是链表,则遍历链表,如果找到相等的元素则替换,否则插入到链表尾部
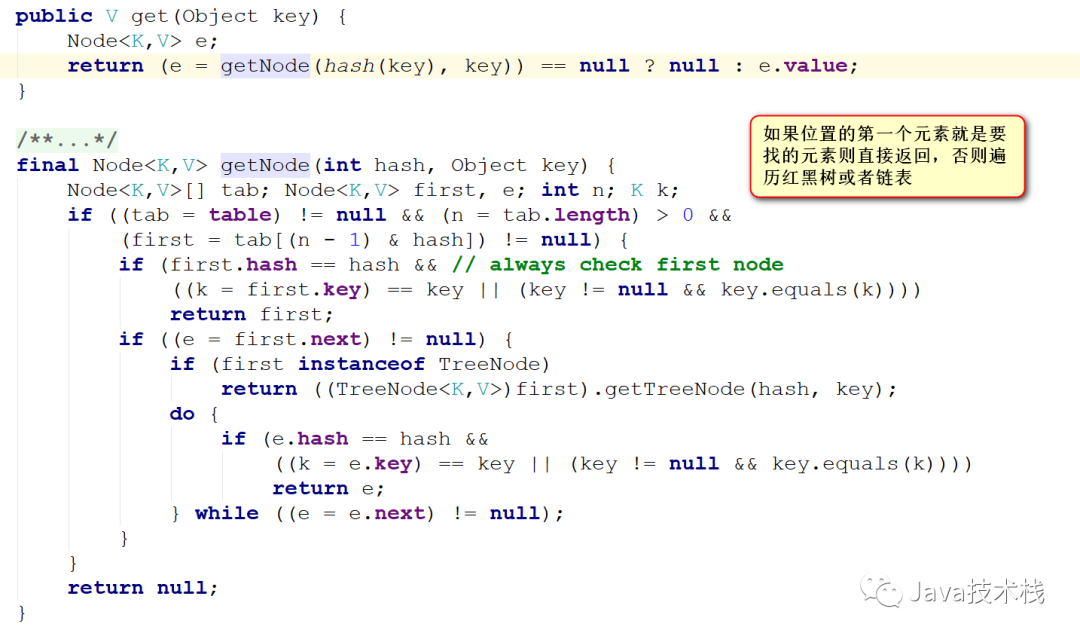
1、计算hash求位置
2、看第一个元素是不是要找的,是则返回,否则遍历

扩容就是将旧数组的元素移动到新数组。
总结:
1、HashMap底层是用数组+双向链表+红黑树实现的
2、插入元素的时候,首先通过一个hash方法计算得到key的哈希值,进而计算出待插入的位置
3、如果该位置为空,则直接插入(包装成Node)
4、如果该位置有值,则依次遍历。比较的规则是,hash值相同,key值相等的元素视为相同,则用新值替换旧值并返回旧值。
5、如果该位置的元素是红黑树结构,则同理,查找,找到则替换,没找到则插入。
另外,关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 Java 系统面试题和答案,非常齐全。
划重点:
JDK1.8中HashMap与JDK1.7中有很多地方不一样
1、1.8中引入了红黑树,而1.7中没有
2、1.8中元素是插在链表的尾部,而1.7中新元素是插在链表的头部
3、扩容的时候,1.8中不会出现死循环,而1.7中容易出现死循环,而且链表不会倒置







关注Java技术栈看更多干货

评论