
ZooKeeper系列文章:ZooKeeper 源码和实践揭秘(二)


导语
ZooKeeper 是个针对大型分布式系统的高可用、高性能且具有一致性的开源协调服务,被广泛的使用。对于开发人员,ZooKeeper 是一个学习和实践分布式组件的不错的选择。本文对 ZooKeeper 的源码进行简析,也会介绍 ZooKeeper 实践经验,希望能帮助到 ZooKeeper 初学者 。文章部分内容参考了一些网络文章,已标注在末尾参考文献中。

ZooKeeper简介
1. 初衷
在业务中使用了 ZooKeeper 作为消息系统,在开发和运维过程中,也遇到一些问题,萌发了阅读源码窥视实现细节的想法。同时我们运维的 ZooKeeper 集群规模和数据规模非常大,也想把运维的经验分享出来供参考去规避风险点和性能调优。
2.目标读者
本文是介绍 ZooKeeper 基础知识和源码分析的入门级材料,适合用于初步进入分布式系统的开发人员,以及使用 ZooKeeper 进行生产经营的应用程序运维人员。
Zookeeper系列文章介绍
第 1 篇:主要介绍 ZooKeeper 使命、地位、基础的概念和基本组成模块,以及 ZooKeeper 内部运行原理,此部分主要从书籍《ZooKeeper 分布式过程协同技术详解》摘录,对于有 ZooKeeper 基础的可以略过。坚持主要目的,不先陷入解析源码的繁琐的实现上,而是从系统和底层看 ZooKeeper 如何运行,通过从高层次介绍其所使用的协议,以及 ZooKeeper 所采用的在提高性能的同时还具备容错能力的机制。
第 2 章节:简析 ZooKeeper 的源码实现,主要目的去介绍 ZooKeeper 集群的工作流程,给出看源码的简要指引,能更快上手去深入阅读源码
第 3 章节:主要介绍业务用 zookeeper 做消息系统的实践,在实践中的优化点和踩坑的地方,由于业务场景和规模的差别,关注点和优化点也差别很大,也欢迎在评论区更新使用 ZooKeeper 共性问题。
在大数据和云计算盛行的今天,应用服务由很多个独立的程序组成,这些独立的程序则运行在形形色色,千变万化的一组计算机上,而如何让一个应用中的多个独立的程序协同工作是一件非常困难的事情。而 ZooKeeper 就是一个分布式的,开放源码的分布式应用程序协调服务。它使得应用开发人员可以更多的关注应用本身的逻辑,而不是协同工作上。从系统设计看,ZooKeeper 从文件系统 API 得到启发,提供一组简单的 API,使得开发人员可以实现通用的协作任务,例如选举主节点,管理组内成员的关系,管理元数据等,同时 ZooKeeper 的服务组件运行在一组专用的服务器之上,也保证了高容错性和可扩展性。
本章节是Zookeeper系列文章的第二篇,本文将为大家解析Zookeeper源码,帮助大家更好的理解源码。
ZooKeeper源码解析
以 3.5.5 版本作为分析。主要从服务端,客户端,以及服务端和客户端结合的部分分析源码。在分析源码时,主要从数据结构,类结构,线程模型,流程等方面看。(注:本章节参考了网上 ZooKeeper 的分析文章,借用了不少文字描述。)
服务端
ZooKeeper 服务的启动方式分为三种,即单机模式、伪分布式模式、分布式模式。本章节主要研究分布式模式的启动模型,其主要要经过 Leader 选举,集群数据同步,启动服务器。
- 解析 config 文件;
- 数据恢复;
- 监听 client 连接(但还不能处理请求);
- bind 选举端口监听 server 连接;
- 选举;
- 初始化 ZooKeeperServer;
- 数据同步;
同步结束,启动 client 请求处理能力。
服务端启动流程(分布式模式)
注:本章节主要是参考网上 blog 文章,对部分内容作了调整与处理。
具体细节如下,
1. ZooKeeper 启动类是 QuorumPeerMain,是将配置文件通过参数方式传入。
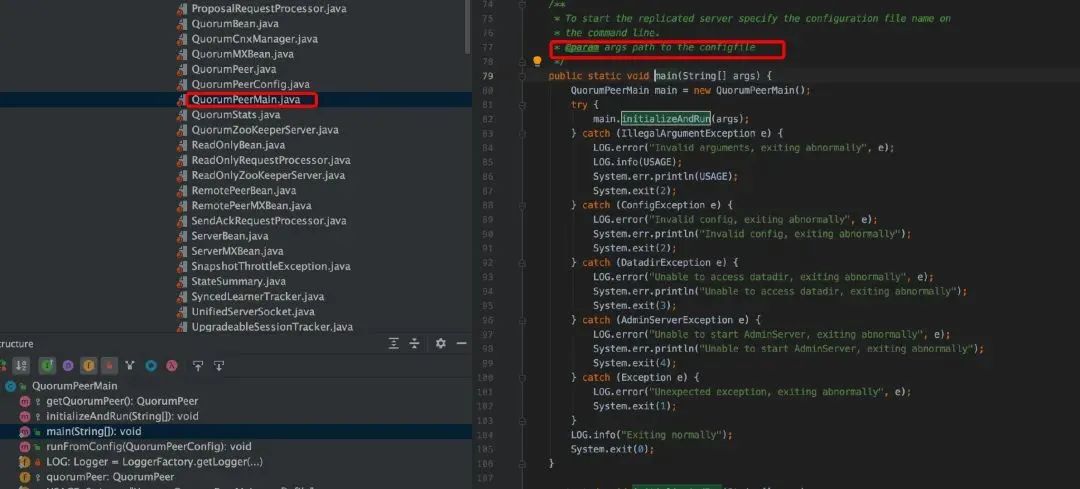
2. DatadirCleanupManager 线程,由于 ZooKeeper 的任何一个变更操作都产生事务,事务日志需要持久化到硬盘,同时当写操作达到一定量或者一定时间间隔后,会对内存中的数据进行一次快照并写入到硬盘上的 snapshop 中,快照为了缩短启动时加载数据的时间从而加快整个系统启动。而随着运行时间的增长生成的 transaction log 和 snapshot 将越来越多,所以要定期清理,DatadirCleanupManager 就是启动一个 TimeTask 定时任务用于清理 DataDir 中的 snapshot 及对应的 transaction log。
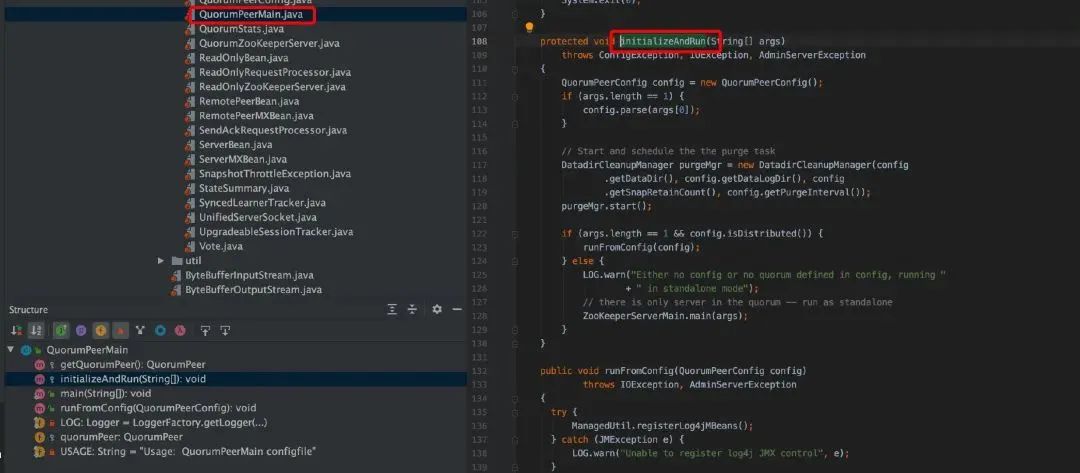
3. 根据配置中的 servers 数量判断是集群环境还是单机环境,如果单机环境以 standalone 模式运行直接调用 ZooKeeperServerMain.main()方法,否则进入集群模式中。
4. 创建 ServerCnxnFactory 实例, ServerCnxnFactory 从名字就可以看出其是一个工厂类,负责管理 ServerCnxn,ServerCnxn 这个类代表了一个客户端与一个 server 的连接,每个客户端连接过来都会被封装成一个 ServerCnxn 实例用来维护了服务器与客户端之间的 Socket 通道。
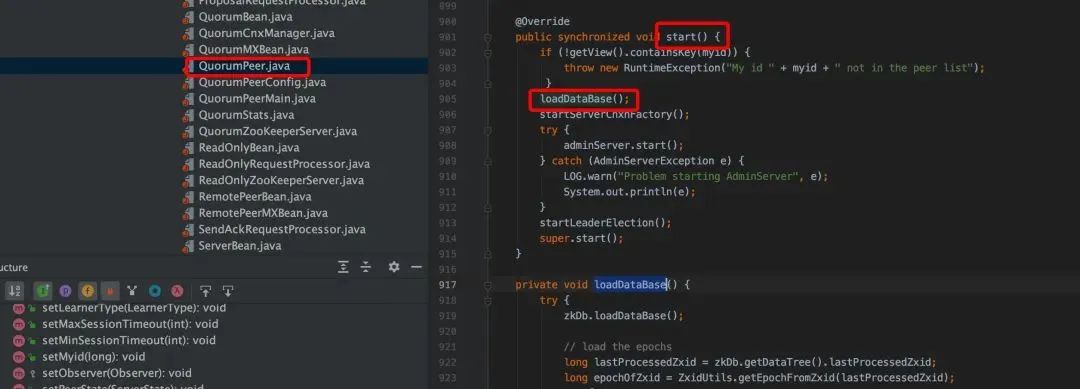
5. QuorumPeer.start()是 ZooKeeper 中非常重要的一个方法入口,
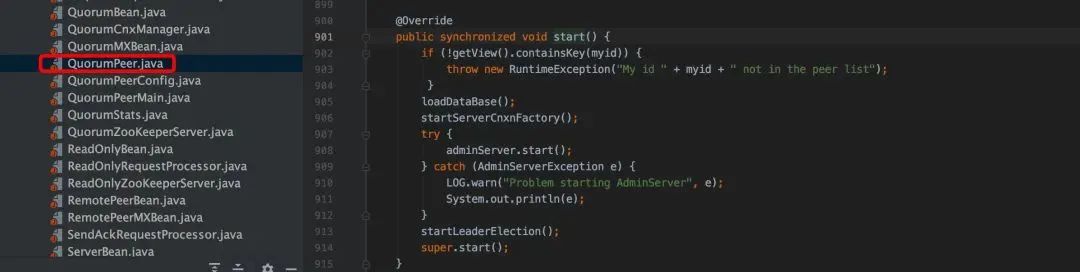
- loadDataBase:涉及到的核心类是 ZKDatabase,并借助于 FileTxnSnapLog 工具类将 snap 和 transaction log 反序列化到内存中,最终构建出内存数据结构 DataTree。
- cnxnFactory.start:之前介绍过 ServerCnxnFactory 作用,ServerCnxnFactory 本身也可以作为一个线程。
startLeaderElection():这个主要是初始化一些 Leader 选举工作。
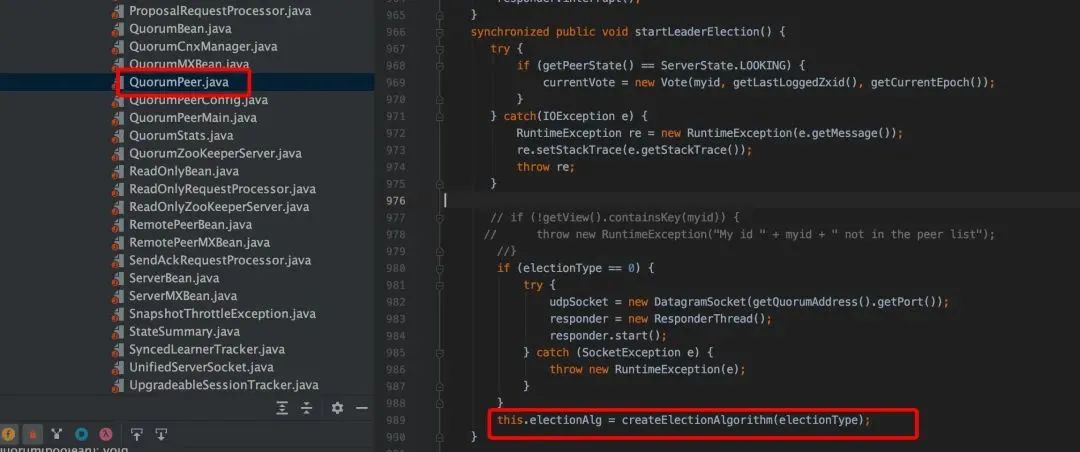
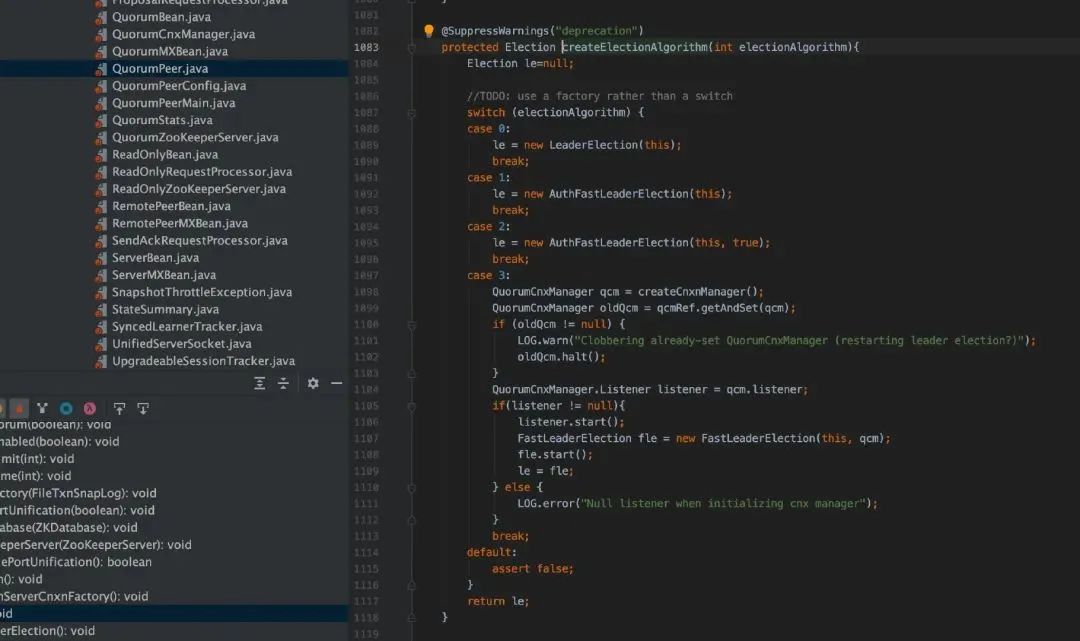
Leader 选举涉及到节点间的网络 IO,QuorumCnxManager 就是负责集群中各节点的网络 IO,QuorumCnxManager 包含一个内部类 Listener,Listener 是一个线程,这里启动 Listener 线程,主要启动选举监听端口并处理连接进来的 Socket;FastLeaderElection 就是封装了具体选举算法的实现。
 4. super.start():QuorumPeer 本身也是一个线程,其继承了 Thread 类,这里就是启动 QuorumPeer 线程,就是执行 QuorumPeer.run 方法。
4. super.start():QuorumPeer 本身也是一个线程,其继承了 Thread 类,这里就是启动 QuorumPeer 线程,就是执行 QuorumPeer.run 方法。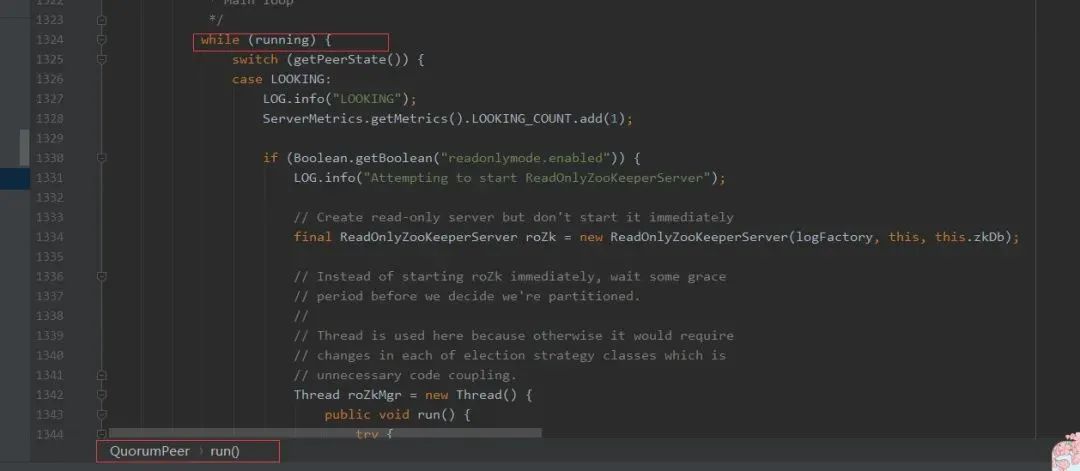
QuorumPeer 线程进入到一个无限循环模式,不停的通过 getPeerState 方法获取当前节点状态,然后执行相应的分支逻辑。大致流程可以简单描述如下:
- 首先系统刚启动时 serverState 默认是 LOOKING,表示需要进行 Leader 选举,这时进入 Leader 选举状态中,会调用 FastLeaderElection.lookForLeader 方法,lookForLeader 方法内部也包含了一个循环逻辑,直到选举出 Leader 才会跳出 lookForLeader 方法,如果选举出的 Leader 就是本节点,则将 serverState=LEADING 赋值,否则设置成 FOLLOWING 或 OBSERVING。
然后 QuorumPeer.run 进行下一轮次循环,通过 getPeerState 获取当前 serverState 状态,如果是 LEADING,则表示当前节点当选为 LEADER,则进入 Leader 角色分支流程,执行作为一个 Leader 该干的任务;如果是 FOLLOWING 或 OBSERVING,则进入 Follower 或 Observer 角色,并执行其相应的任务。注意:进入分支路程会一直阻塞在其分支中,直到角色转变才会重新进行下一轮次循环,比如 Follower 监控到无法与 Leader 保持通信了,会将 serverState 赋值为 LOOKING,跳出分支并进行下一轮次循环,这时就会进入 LOOKING 分支中重新进行 Leader 选举。
服务器各阶段
数据恢复
在服务器启动阶段需要进行数据恢复阶段。
Leader 选举
Leader 选举初始化 QuorumPeer.startLeaderElection(),Leader 选举涉及到两个核心类:QuorumCnxManager 和 FastLeaderElection。
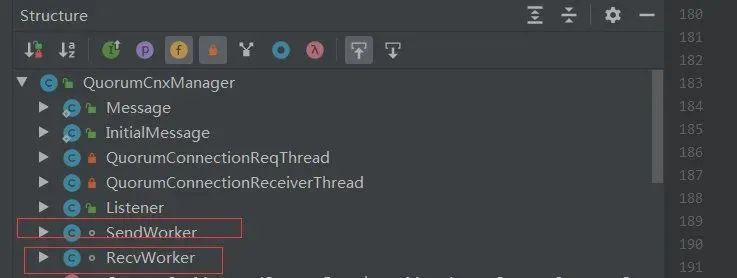
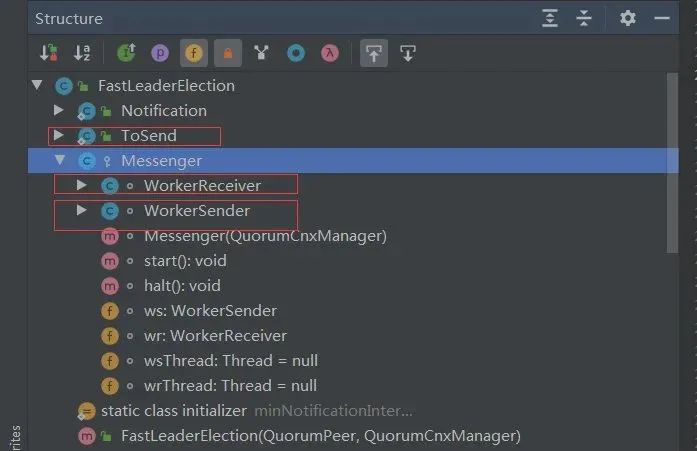
在 createElectionAlgorithm()算法中,创建一个 QuorumCnxManager 实例,启动 QuorumCnxManager.Listener 线程,构建选举算法 FastLeaderElection,然后相互交互投票信息,进入 Leader 选举过程。
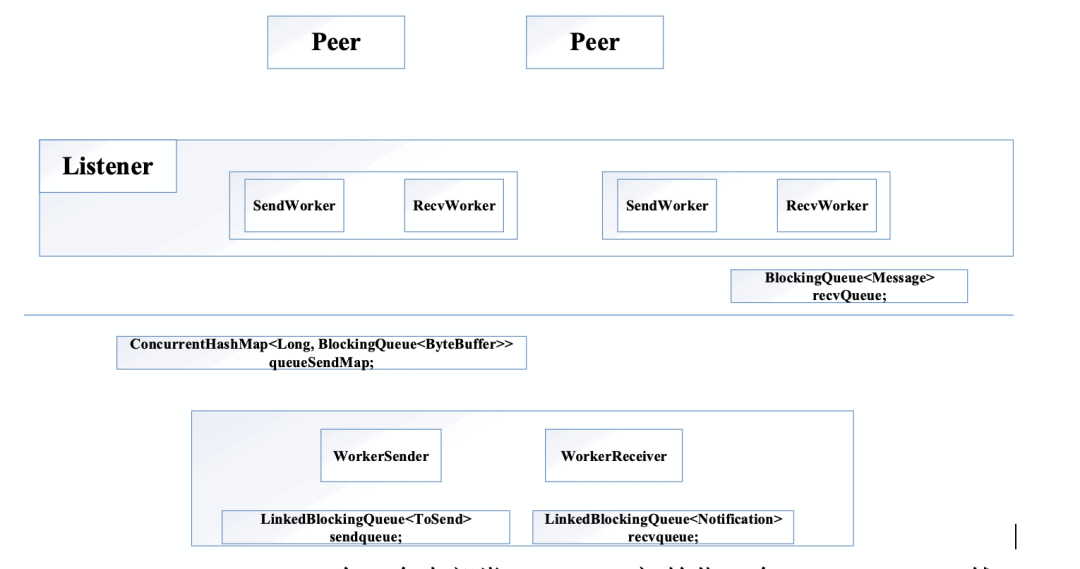
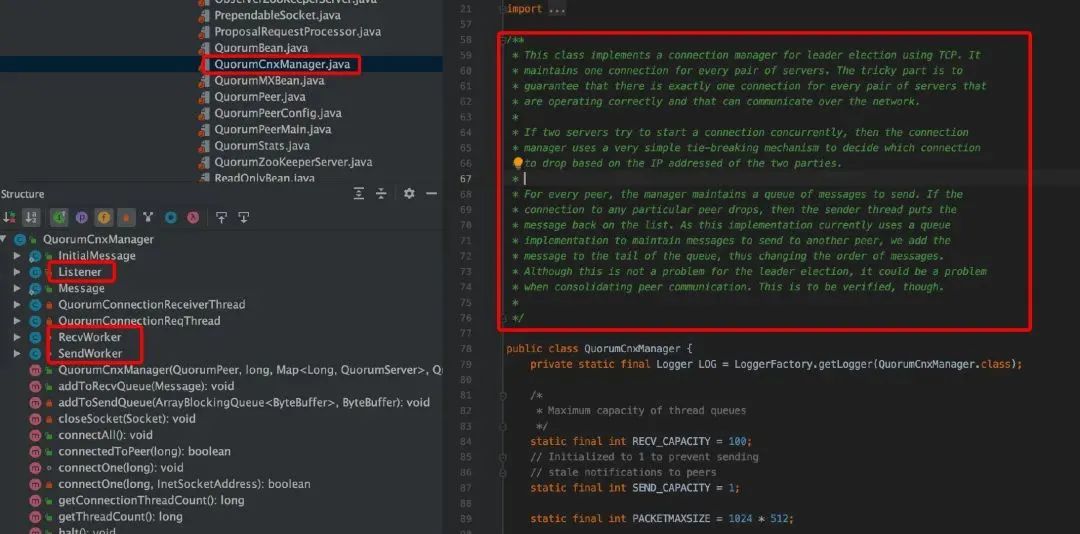
QuorumCnxManager 有一个内部类 Listener,初始化一个 ServerSocket,然后在一个 while 循环中调用 accept 接收客户端(注意:这里的客户端指的是集群中其它服务器)连接。当有客户端连接进来后,会将该客户端 Socket 封装成 RecvWorker 和 SendWorker,它们都是线程,分别负责和该 Socket 所代表的客户端进行读写。其中,RecvWorker 和 SendWorker 是成对出现的,每对负责维护和集群中的一台服务器进行网络 IO 通信。
FastLeaderElection 负责 Leader 选举核心规则算法实现,包含了两个内部类 WorkerSender 和 WorkerReceiver 线程。
- 将数据封装成 ToSend 格式放入到 sendqueue;
- WorkerSender 线程会一直轮询提取 sendqueue 中的数据,当提取到 ToSend 数据后,会获取到集群中所有参与 Leader 选举节点(除 Observer 节点外的节点)的 sid,如果 sid 即为本机节点,则转成 Notification 直接放入到 recvqueue 中,因为本机不再需要走网络 IO;否则放入到 queueSendMap 中,key 是要发送给哪个服务器节点的 sid,ByteBuffer 即为 ToSend 的内容,queueSendMap 维护的着当前节点要发送的网络数据信息,由于发送到同一个 sid 服务器可能存在多条数据,所以 queueSendMap 的 value 是一个 queue 类型;
- QuorumCnxManager 中的 SendWorkder 线程不停轮询 queueSendMap 中是否存在自己要发送的数据,每个 SendWorkder 线程都会绑定一个 sid 用于标记该 SendWorkder 线程和哪个对端服务器进行通信,因此,queueSendMap.get(sid)即可获取该线程要发送数据的 queue,然后通过 queue.poll()即可提取该线程要发送的数据内容;
然后通过调用 SendWorkder 内部维护的 socket 输出流即可将数据写入到对端服务器。
- QuorumCnxManager 中的 RecvWorker 线程会一直从 Socket 的输入流中读取数据,当读取到对端发送过来的数据时,转成 Message 格式并放入到 recvQueue 中;
- FastLeaderElection.WorkerReceiver 线程会轮询方式从 recvQueue 提取数据并转成 Notification 格式放入到 recvqueue 中;
FastLeaderElection 从 recvqueu 提取所有的投票信息进行比较 最终选出一个 Leader。
Leader 选举算法实现
上面已经介绍了 Leader 选举期间网络 IO 的大致流程,下面介绍下具体选举算法如何实现。
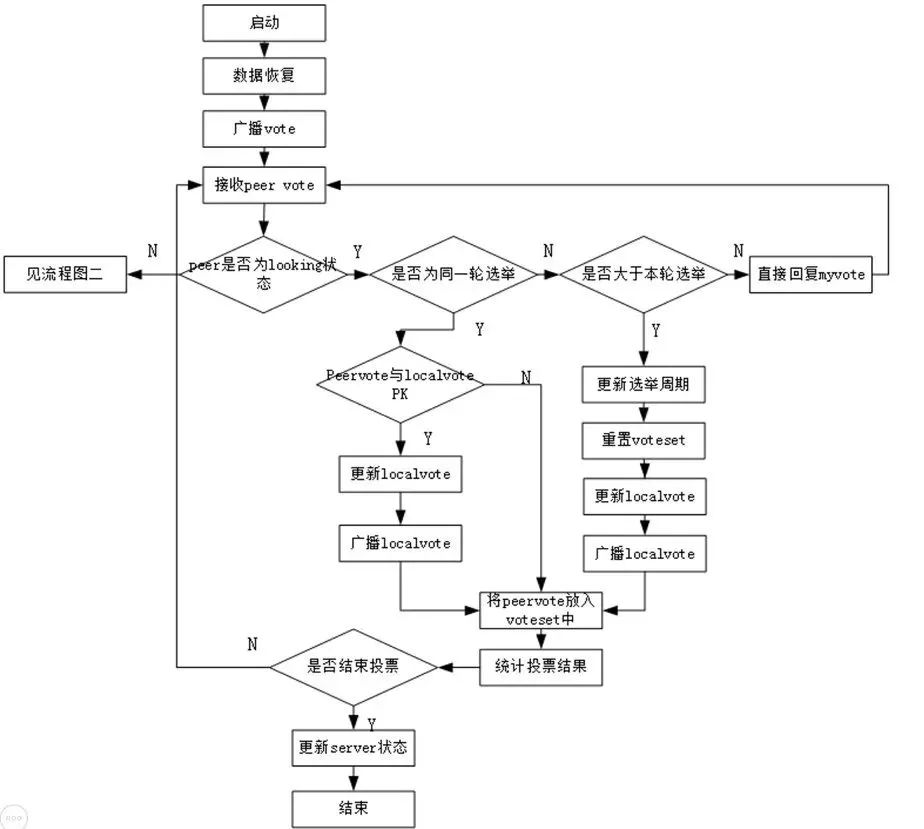
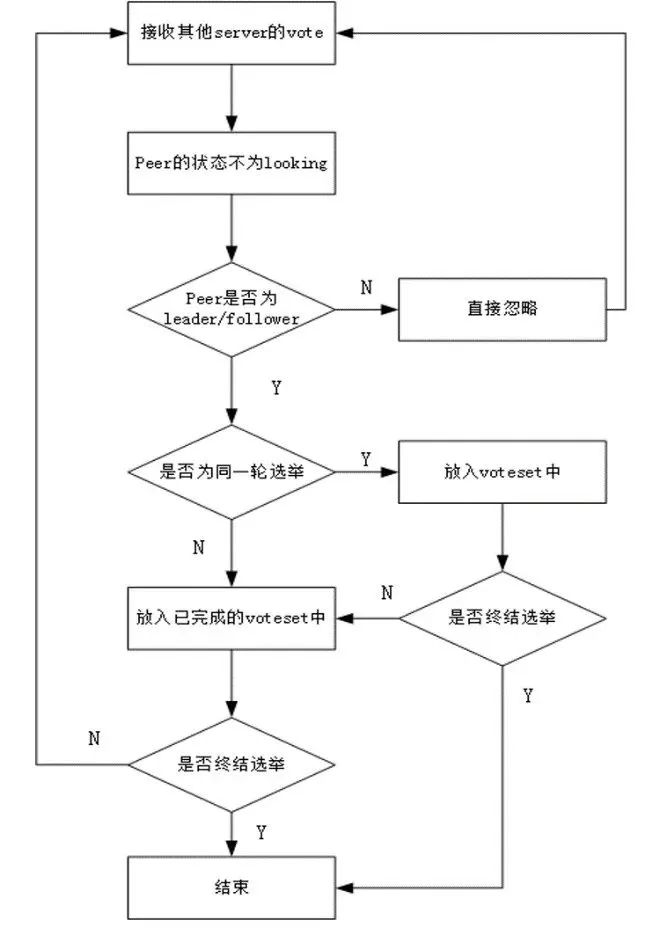
QuorumPeer 线程中会有一个 Loop 循环,获取 serverState 状态后进入不同分支,当分支退出后继续下次循环,FastLeaderElection 选举策略调用就是发生在检测到 serverState 状态为 LOOKING 时进入到 LOOKING 分支中调用的。
进入到 LOOKING 分支执行的代码逻辑:
setCurrentVote(makeLEStrategy().lookForLeader());从上面代码可以看出,Leader 选举策略入口方法为:FastLeaderElection.lookForLeader()方法。当 QuorumPeer.serverState 变成 LOOKING 时,该方法会被调用,表示执行新一轮 Leader 选举。下面来看下 lookForLeader 方法的大致实现逻辑:
更新自己期望投票信息,即自己期望选哪个服务器作为 Leader(用 sid 代替期望服务器节点)以及该服务器 zxid、epoch 等信息,第一次投票默认都是投自己当选 Leader,然后调用 sendNotifications 方法广播该投票到集群中所有可以参与投票服务器,广播涉及到网络 IO 流程前面已讲解,这里就不再细说;
其中,updateProposal()方法有三个参数:a.期望投票给哪个服务器(sid)、b.该服务器的 zxid、c.该服务器的 epoch,在后面会看到这三个参数是选举 Leader 时的核心指标,后面再介绍。
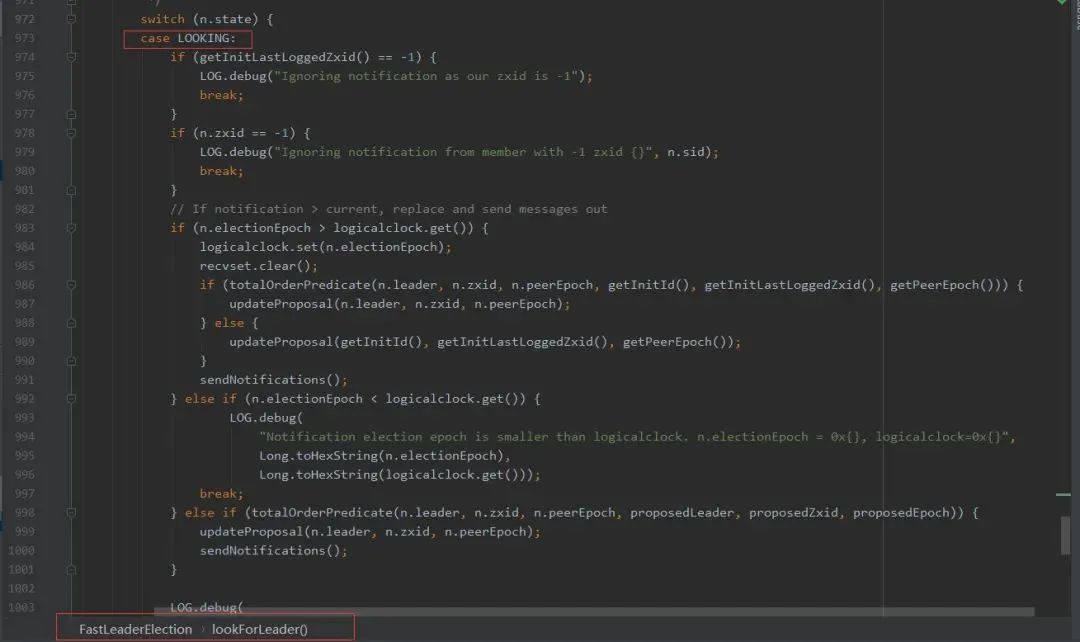
首先对之前提到的选举轮次 electionEpoch 进行判断,这里分为三种情况:
- 只有对方发过来的投票的 electionEpoch 和当前节点相等表示是同一轮投票,即投票有效,然后调用 totalOrderPredicate()对投票进行 PK,返回 true 代表对端胜出,则表示第一次投票是错误的(第一次都是投给自己),更新自己投票期望对端为 Leader,然后调用 sendNotifications()将自己最新的投票广播出去。返回 false 则代表自己胜出,第一次投票没有问题,就不用管。
- 如果对端发过来的 electionEpoch 大于自己,则表明重置自己的 electionEpoch,然后清空之前获取到的所有投票 recvset,因为之前获取的投票轮次落后于当前则代表之前的投票已经无效了,然后调用 totalOrderPredicate()将当前期望的投票和对端投票进行 PK,用胜出者更新当前期望投票,然后调用 sendNotifications()将自己期望头破广播出去。注意:这里不管哪一方胜出,都需要广播出去,而不是步骤 a 中己方胜出不需要广播,这是因为由于 electionEpoch 落后导致之前发出的所有投票都是无效的,所以这里需要重新发送
- 如果对端发过来的 electionEpoch 小于自己,则表示对方投票无效,直接忽略不进行处理
totalOrderPredicate()实现了对投票进行 PK 规则:
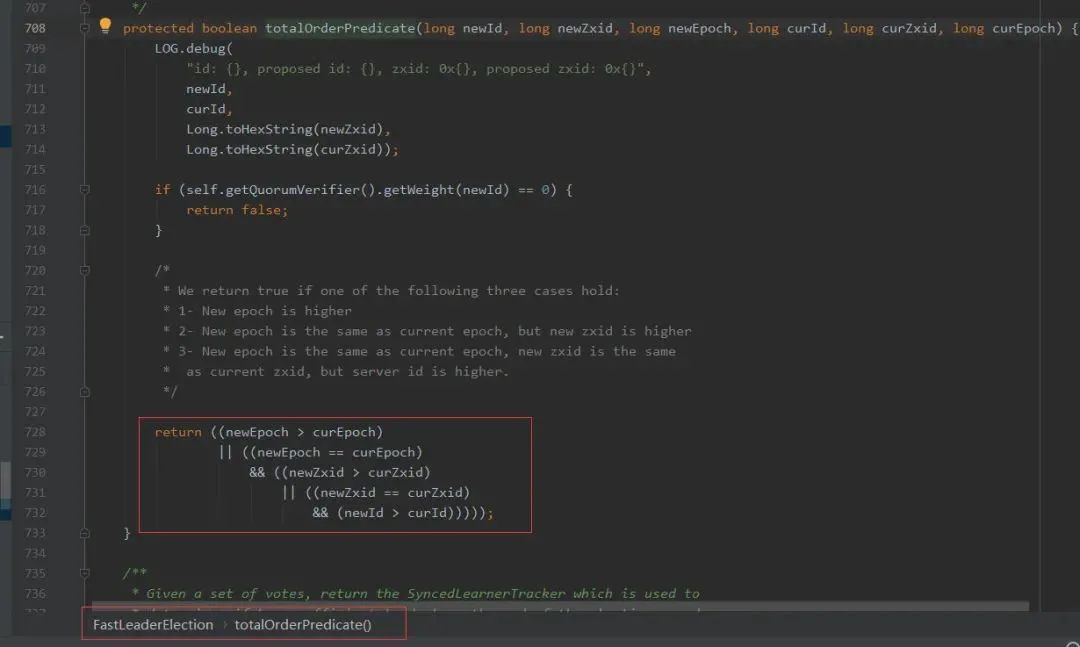
下面简单说下这个 PK 逻辑原理(胜出一方代表更有希望成为 Leader):
- 首先比较 epoch,哪个 epoch 哪个胜出,前面介绍过 epoch 代表了 Leader 的轮次,是一个递增的,epoch 越大就意味着数据越新,Leader 数据越新则可以减少后续数据同步的效率,当然应该优先选为 Leader;
- 然后才是比较 zxid,由于 zxid=epoch+counter,第一步已经把 epoch 比较过了,其实这步骤只是相当于比较 counter 大小,counter 越大则代表数据越新,优先选为 Leader。注:其实第 1 和第 2 可以合并到一起,直接比较 zxid 即可,因为 zxid=epoch+counter,第 1 比较显的有些多余;
- 如果前两个指标都没法比较出来,只能通过 sid 来确定,zxid 相等说明两个服务器的数据是一致的,选择 sid 大的当 Leader。
集群数据同步
Leader 选举的流程,ZooKeeper 集群在 Leader 选举完成后,集群中的各个节点就确定了自己的角色信息:Leader、Follower 或 Observer。
如上述代码所述,节点确定了自己的角色后,就会进入自己的角色分支:对于 Leader 而言创建 Leader 实例并调用其 lead()函数,对于 Follower 而言创建 Follower 实例并调用其 followLeader()函数,对于 Observer 而言创建 Observer 实例并调用其 observeLeader()函数。在这三个函数中,服务器会进行相关的初始化并完成最终的启动。
对于 Follower 和 Observer 而言,主要的初始化工作是要建立与 Leader 的连接并同步 epoch 信息,最后完成与 Leader 的数据同步。而 Leader 会启动 LearnerCnxAcceptor 线程,该线程会接受来自 Follower 和 Observer(统称为 Learner)的连接请求并为每个连接创建一个 LearnerHandler 线程,该线程会负责包括数据同步在内的与 learner 的一切通信。
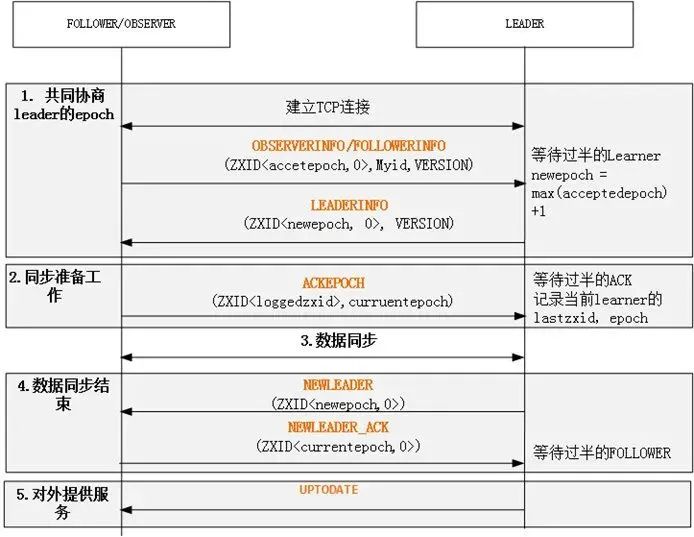
Learn(Follower 或 Observer)节点会主动向 Leader 发起连接,ZooKeeper 就会进入集群同步阶段,集群同步主要完成集群中各节点状态信息和数据信息的一致。选出新的 Leader 后的流程大致分为:计算 epoch、统一 epoch、同步数据、广播模式等四个阶段。其中其前三个阶段:计算 epoch、统一 epoch、同步数据就是这一节主要介绍的集群同步阶段的主要内容,这三个阶段主要完成新 Leader 与集群中的节点完成同步工作,处于这个阶段的 zk 集群还没有真正做好对外提供服务的能力,可以看着是新 leader 上任后进行的内部沟通、前期准备工作等,只有等这三个阶段全部完成,新 leader 才会真正的成为 leader,这时 zk 集群会恢复正常可运行状态并对外提供服务。
被选举为 Leader 角色的节点,会创建一个 Leader 实例,然后执行 Leader.lead()进入到 Leader 角色的任务分支中,其流程大致如下所示:
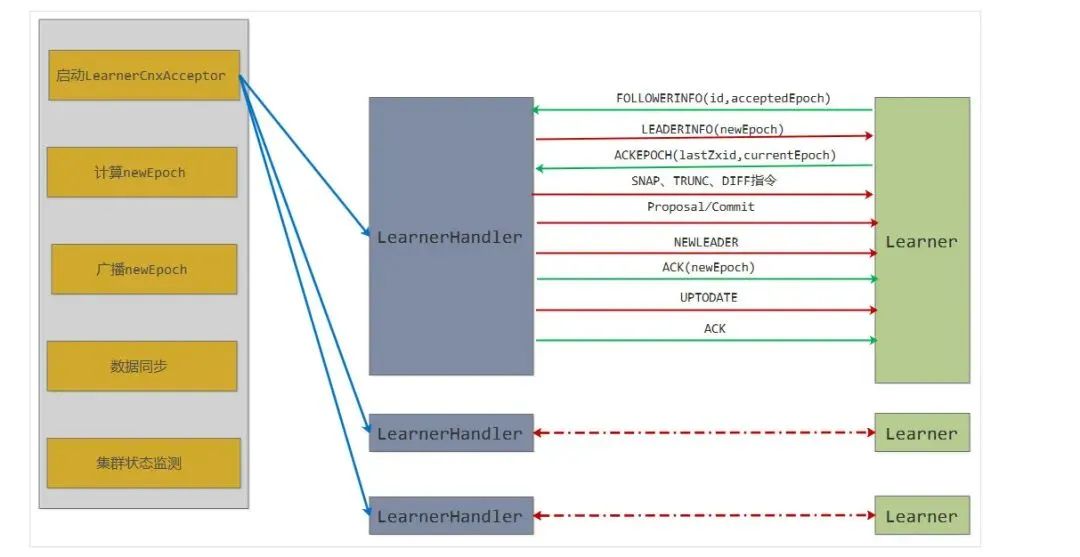
Leader 分支大致可以分为 5 个阶段:启动 LearnerCnxAcceptor 线程、计算 newEpoch、广播 newEpoch、数据同步和集群状态监测。
Leader.lead()方法控制着 Leader 角色节点的主体流程,其实现较为简单,大致模式都是通过阻塞方法阻塞当前线程,直到该阶段完成 Leader 线程才会被唤醒继续执行下一个阶段;而每个阶段实现的具体细节及大量的网络 IO 操作等都在 LearnerHandler 中实现。比如计算 newEpoch,Leader 中只会判断 newEpoch 计算完成没,没有计算完成就会进入阻塞状态挂起当前 Leader 线程,直到集群中一半以上的节点同步了 epoch 信息后 newEpoch 正式产生才会唤醒 Leader 线程继续向下执行;而计算 newEpoch 会涉及到 Leader 去收集集群中大部分 Learner 服务器的 epoch 信息,会涉及到大量的网络 IO 通信等内容,这些细节部分都在 LearnerHandler 中实现。
涉及到网络 IO 就会存在 Server 和 Client,这里的 Server 就是 Leader,Client 就是 Learner(Follower 和 Observer 统称 Learner),对于 Server 端,主要关注 Leader 和 LearnerHandler 这两个类,而对于 Client 端,根据角色分类主要关注 Follower 或 Observer 这两个类。
ZooKeeper 中主要存在三个端口:
- 客户端请求端口:对应于配置中的 clientPort,默认是 2181,就是客户端连接 ZK 对其进行增删改操作的端口;
- 集群选举端口:之前分析过的集群中 Leader 选举涉及到网络 IO 使用的端口,对应于配置中“server.0=10.80.8.3:2888:2999”这里的 2999 就是集群选举端口;
- 集群同步端口:Leader 选举出后就会涉及到 Leader 和 Learner 之间的数据同步问题,集群同步端口的作用就是做这个使用的,对应于配置中”server.0=10.80.8.3:2888:2999“这里的 2888;
启动 LearnerCnxAcceptor 线程
Leader 首先会启动一个 LearnerCnxAcceptor 线程,这个线程做的工作就非常简单了,就是不停的循环 accept 接收 Learner 端的网络请求(这里的监听端口就是上面说的同步监听端口,而不是选举端口),Leader 选举结束后被分配为 Follower 或 Observer 角色的节点会主动向 Leader 发起连接,Leader 端接收到一个网络连接就会封装成一个 LearnerHandler 线程。
Leader 类可以看成一个总管,和每个 Learner 服务器的交互任务都会被分派给 LearnerHandler 这个助手完成,当 Leader 检测到一个任务被一半以上的 LearnerHandler 处理完成,即认为该阶段结束,进入下一个阶段。
计算 epoch
epoch 在 ZooKeeper 中是一个很重要的概念,前面也介绍过了:epoch 就相当于 Leader 的身份编号,就如同身份证编号一样,每次选举产生一个新 Leader 时,都会为该 Leader 重新计算出一个新 epoch。epoch 被设计成一个递增值,比如上一个 Leader 的 epoch 是 1,假如重新选举新的 Leader 就会被分配 epoch=1。
epoch 作用:可以防止旧 Leader 活过来后继续广播之前旧提议造成状态不一致问题,只有当前 Leader 的提议才会被 Follower 处理。ZooKeeper 集群所有的事务请求操作都要提交由 Leader 服务器完成,Leader 服务器将事务请求转成一个提议(Proposal)并分配一个事务 ID(zxid)后广播给 Learner,zxid 就是由 epoch 和 counter(递增)组成,当存在旧 leader 向 follower 发送命令的时候,follower 发现 zxid 所在的 epoch 比当前的小,则直接拒绝,防止出现不一致性。
统一 epoch
newEpoch 计算完成后,该值只有 Leader 知道,现在需要将 newEpoch 广播到集群中所有的服务器节点上,让他们都更新下新 Leader 的 epoch 信息,这样他们在处理请求时会根据 epoch 判断该请求是不是当前新 Leader 发出的,可以防止旧 Leader 活过来后继续广播之前旧提议造成状态不一致问题,只有当前 Leader 的提议才会被 Follower 处理。
总结:广播 newEpoch 流程也比较简单,就是将之前计算出来的 newEpoch 封装到 LEADERINFO 数据包中,然后广播到集群中的所有节点,同时会收到 ACKEPOCH 回复数据包,当集群中一半以上的节点进行了回复则可以认为 newEpoch 广播完成,则进入下一阶段。同样,为避免线程一直阻塞,休眠线程依然会被添加超时时间,超时后仍未完成则抛出 InterruptedException 异常重新进入 Leader 选举状态。
数据同步
之前分析过 Leader 的选举策略:lastZxid 越大越会被优先选为 Leader。lastZxid 是节点上最大的事务 ID,由于 zxid 是递增的,lastZxid 越大,则表示该节点处理的数据越新,即数据越完整。所以,被选为 Leader 的节点数据完整性越高,为了数据一致性,这时就需要其它节点和 Leader 进行数据同步保持数据一致性。
- DIFF,learner 比 leader 少一些数据;
- TRUNC,learner 数据比 leader 多;
- DIFF+TRUNC,learner 对 leader 多数据又少数据;
SNAP,learner 比 leader 少很多数据。
服务角色
群首,追随者,观察者根本上都是服务器,在实现服务器主要抽象概念是请求处理器。请求处理器是对处理流水线上不同阶段的抽象,每个服务器在初始化时实现一个请求处理器的序列。对于请求处理器,ZooKeeper 代码里有一个叫 RequestProcessor 的接口,这个接口的主要方法是processRequest,它接受一个 Request 参数,在一个请求处理器的流水线中,对于相邻处理器的请求的处理是通过队列实现解耦合。当一个处理器有一条请求需要下一个处理器进行处理时,它将这条请求加入队列中。然后,它将处于等待状态直到下一个处理器处理完此消息。本节主要看看各个服务器的请求处理器序列初始化和对队列的使用与处理,处理器的细节可以参考源码。
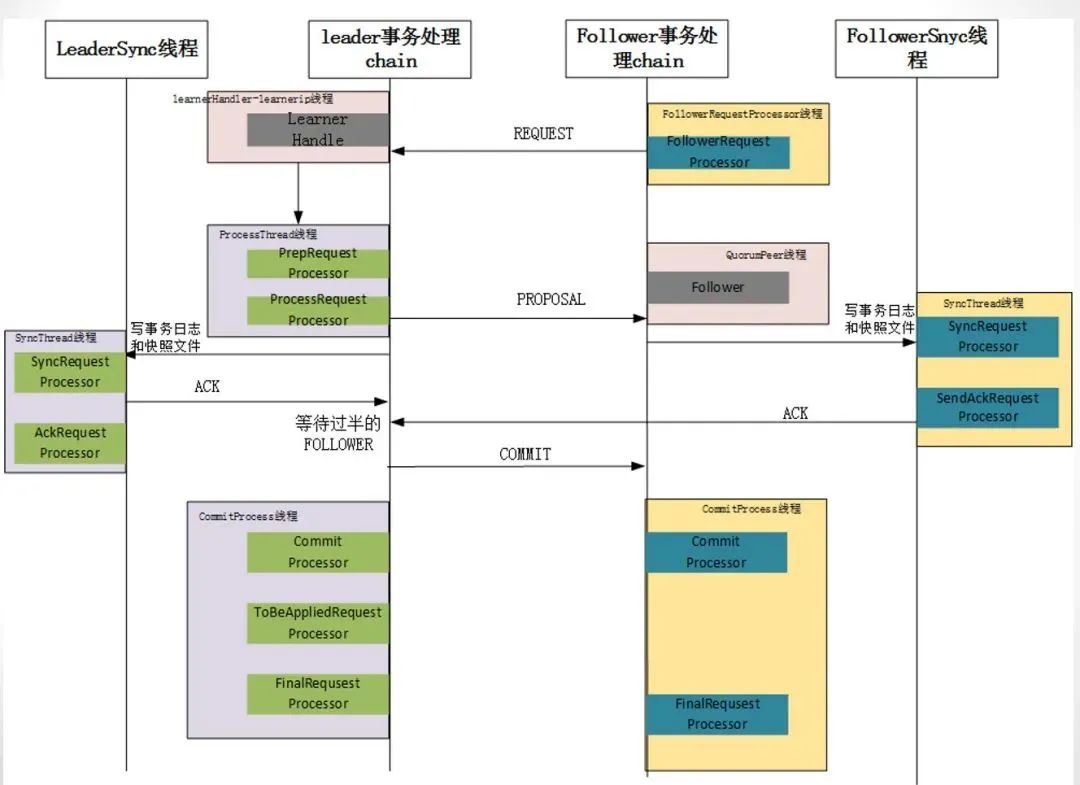
独立服务器
独立服务器请求链

独立服务器是从 ZooKeeperServerMain.java 开始,
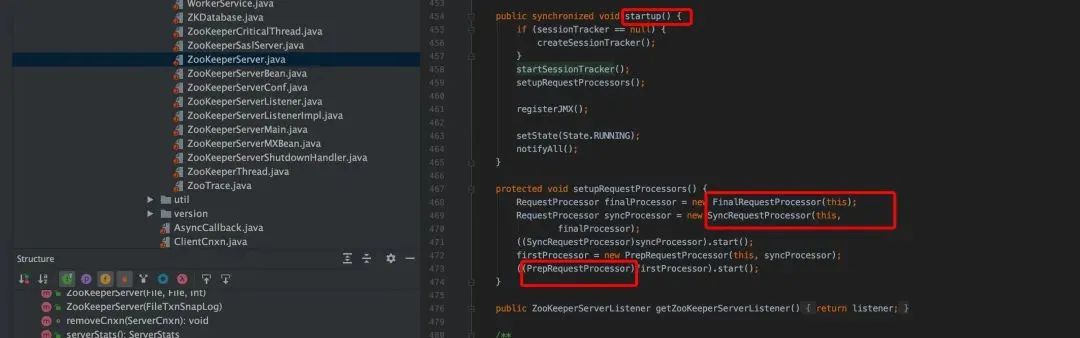
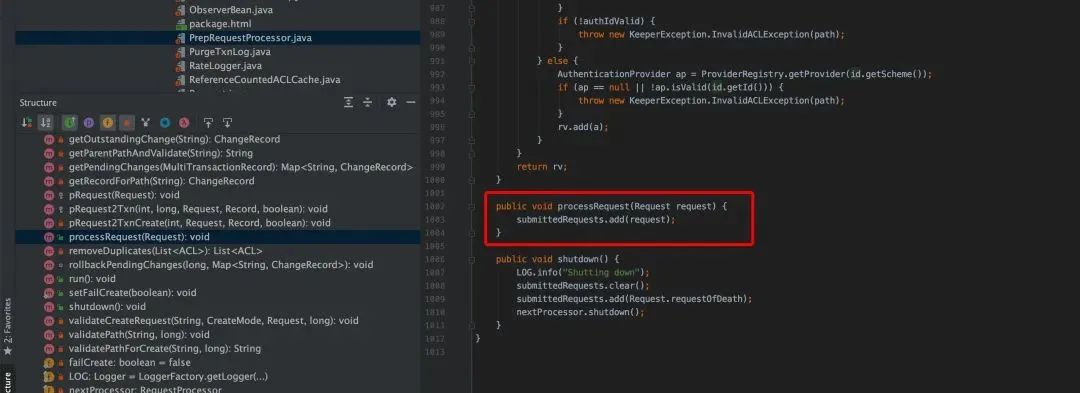
在 PrepRequestProcessor 中,消费请求队列 submittedRequests,数据结构如下
LinkedBlockingQueuesubmittedRequests = new LinkedBlockingQueue();
PrepRequestProcessor 接受客户端的请求并执行这个请求,处理结果则是生成一个事务。不过只有改变 ZooKeeper 状态的操作才会产生事务,对于读操作并不会产生任何事务。
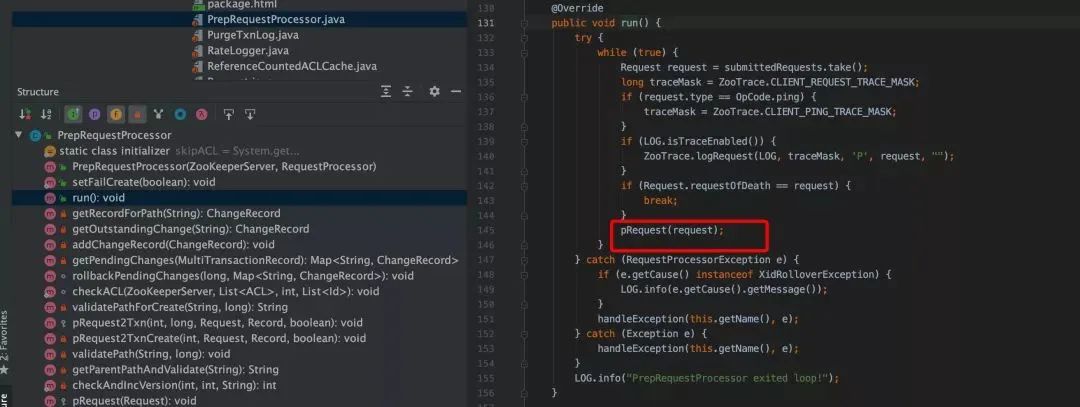
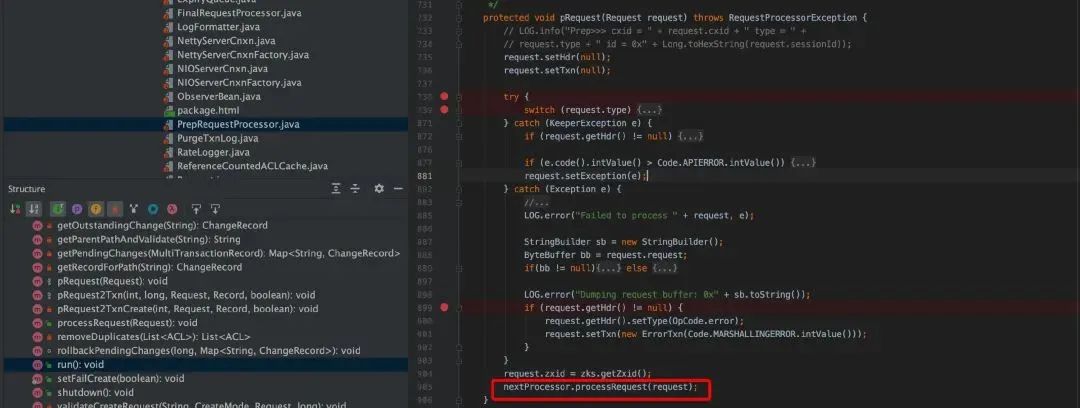
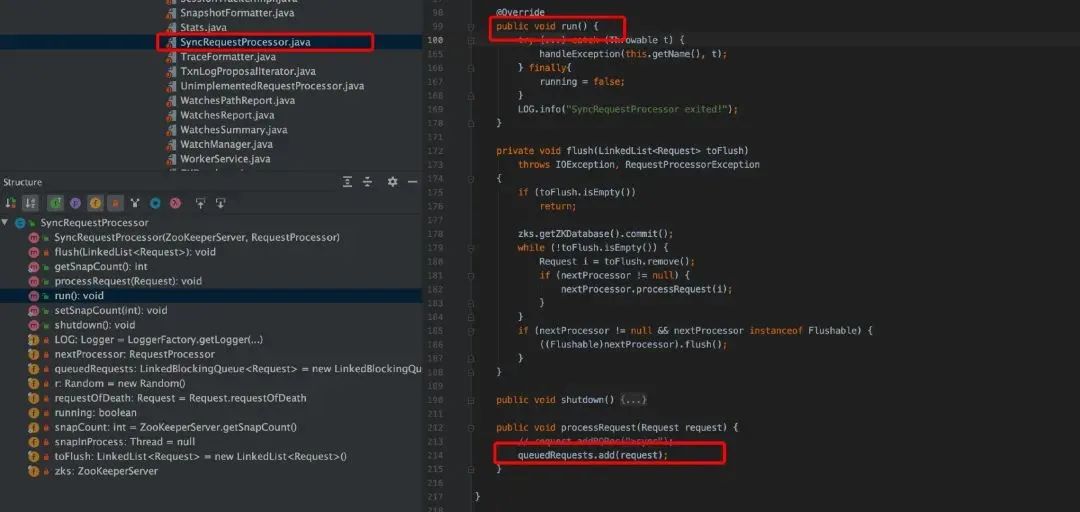
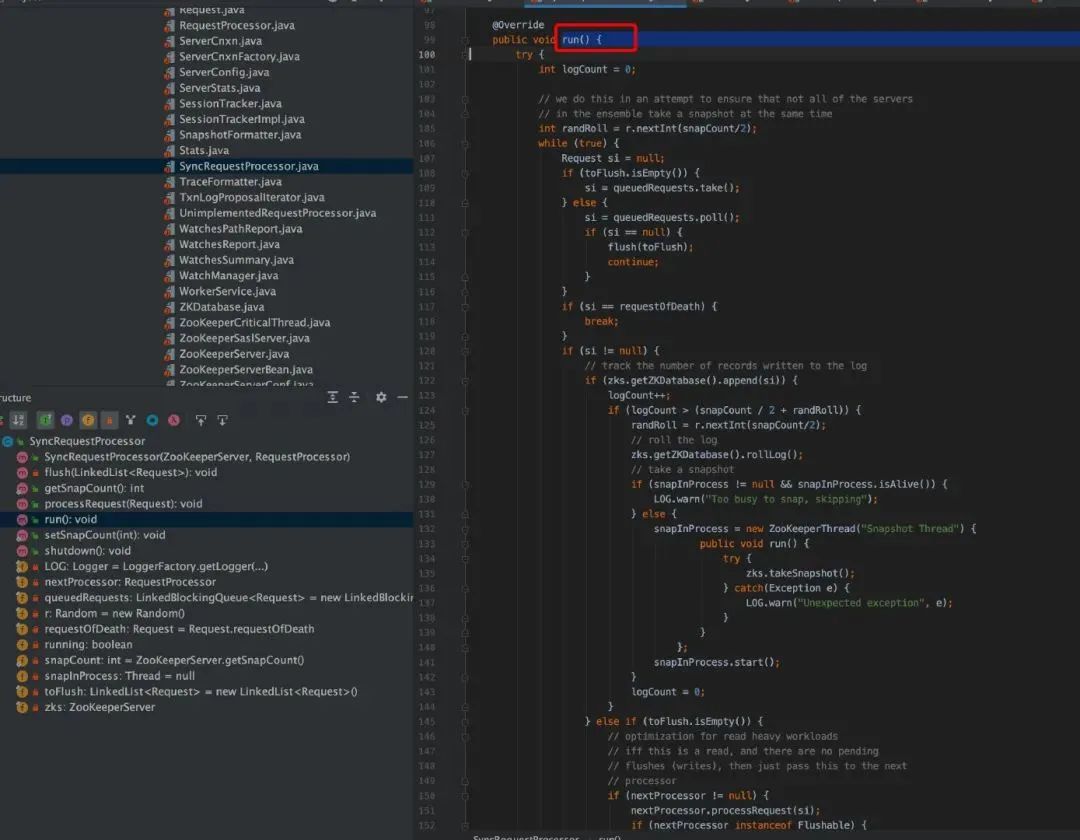
SyncRequestProcessor.java,SyncRequestProcessor 负责将事务持久化到磁盘上。实际上就是将事务数据按照顺序追加到事务日志中,并形成快照数据。
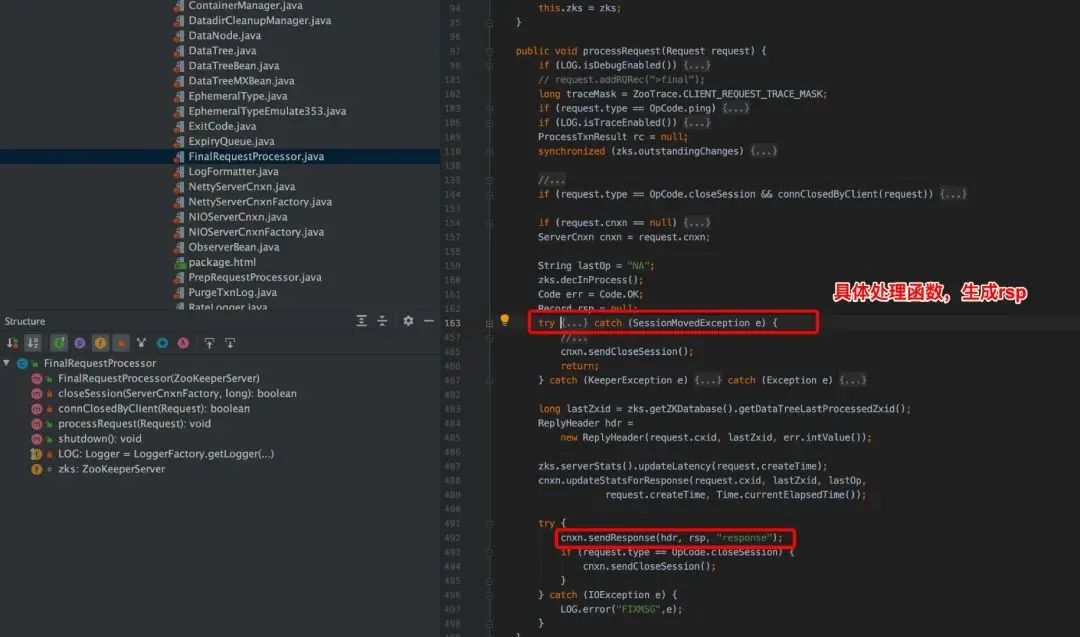
FinalRequestProcessor.java,FinalRequestProcessor,如果 Request 对象包含事务数据,该处理器就会接受对 ZooKeeper 数据树的修改,否则,该处理器会从数据树中读取数据并返回客户端。
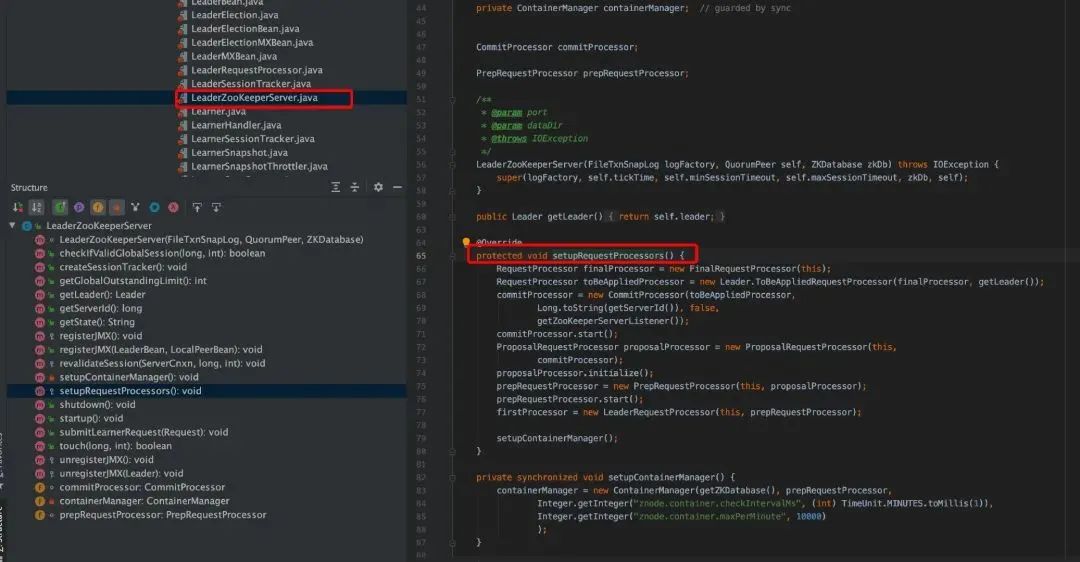
群首服务器(Leader)
请求链

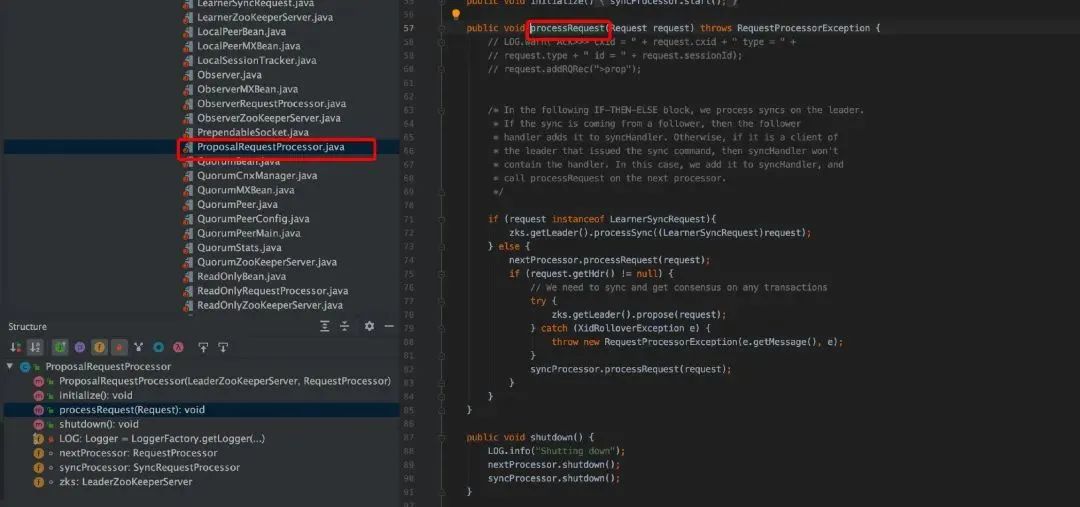
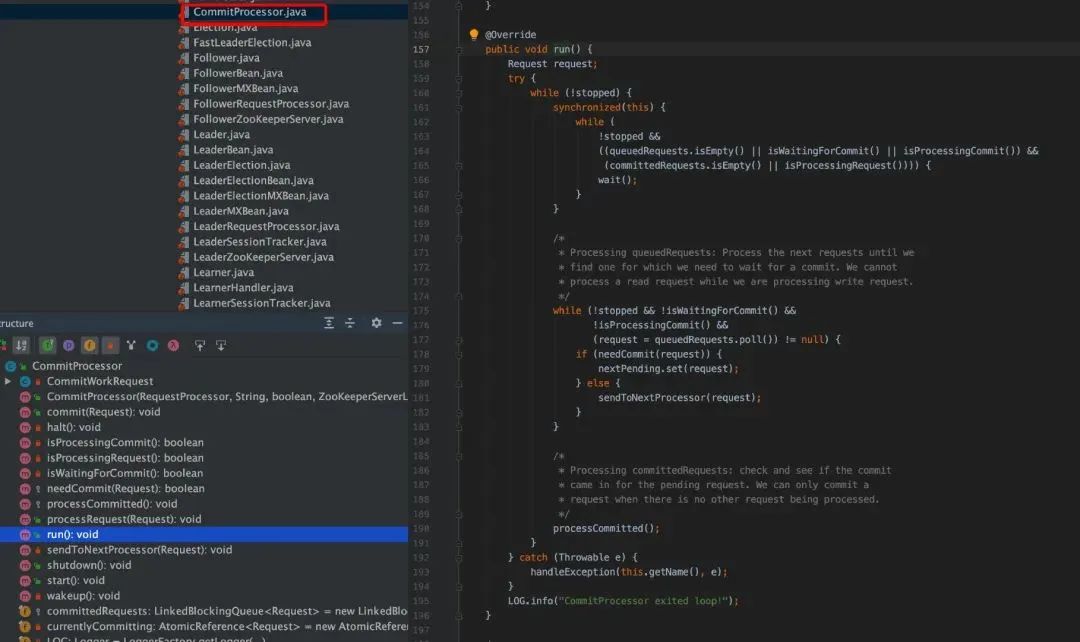
Follower
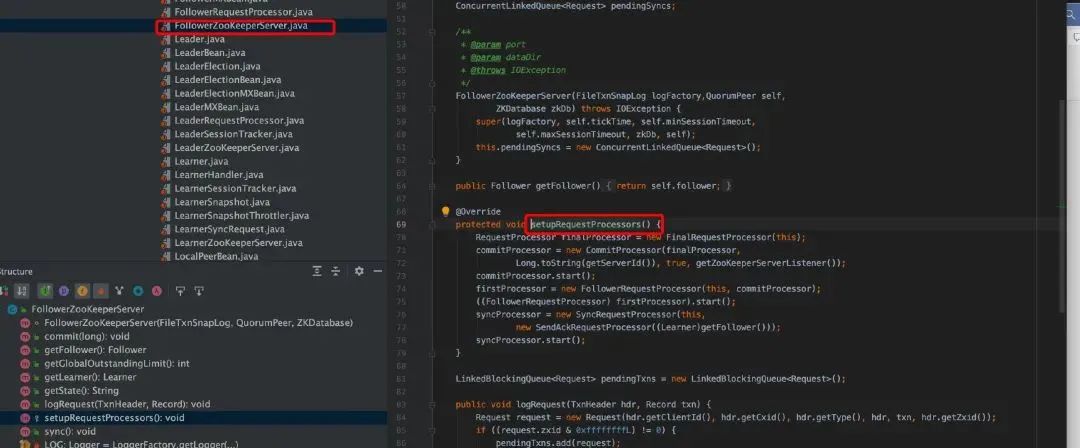
Observer
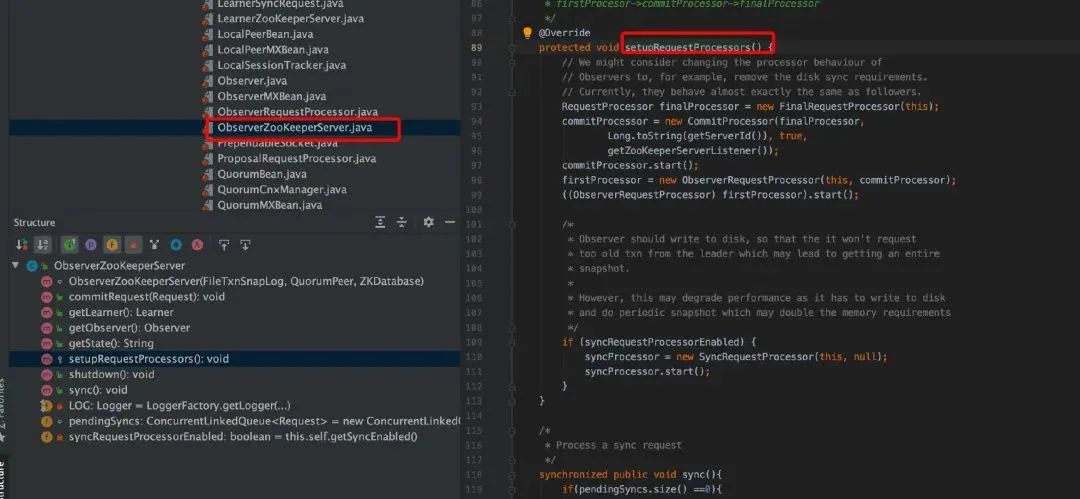
参考资料:https://www.jianshu.com/p/45f8a966fb47

One more thing
目前,腾讯云微服务引擎(Tencent Cloud Service Engine,简称TSE)已上线,并发布子产品服务注册、配置中心(ZooKeeper/Nacos/Eureka/Apollo)、治理中心(PolarisMesh)。支持一键创建、免运维、高可用、开源增强的组件托管服务,欢迎点击文末的「阅读原文」了解详情并使用!
TSE官网地址:
https://cloud.tencent.com/product/tse
参考文献
- ZooKeeper-选举实现分析:https://juejin.im/post/5cc2af405188252da4250047
- Apache ZooKeeper 官网:https://zookeeper.apache.org/
- ZooKeeper github:https://github.com/apache/zookeeper
- 《zookeeper-分布式过程协同技术详解》【美】里德,【美】Flavio Junqueira 著
- ZooKeeper 源码分析:https://blog.reactor.top/tags/Zookeeper/
- ZooKeeper-选举实现分析:https://juejin.im/post/5cc2af405188252da4250047
- ZooKeeper 源码分析:https://www.cnblogs.com/sunshine-2015/tag/zookeeper/
往期
推荐
《Kratos技术系列|从Kratos设计看Go微服务工程实践》
《Pulsar技术系列 - 深度解读Pulsar Schema》
《Apache Pulsar事务机制原理解析|Apache Pulsar 技术系列》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
 戳原文,查看更多微服务引擎TSE信息!
戳原文,查看更多微服务引擎TSE信息!
点个在看你最好看