
使用uuid做MySQL主键,被老板,爆怼一顿!
一:mysql和程序实例
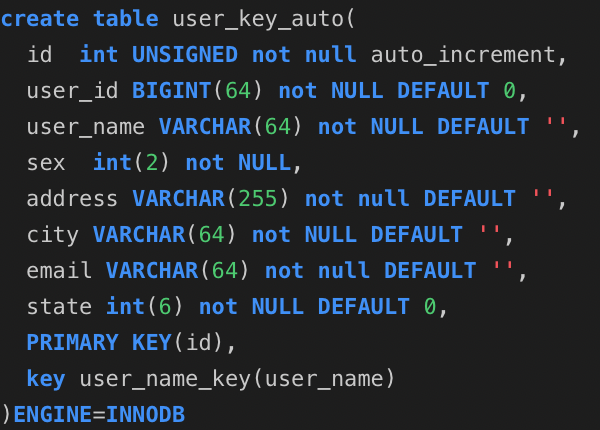
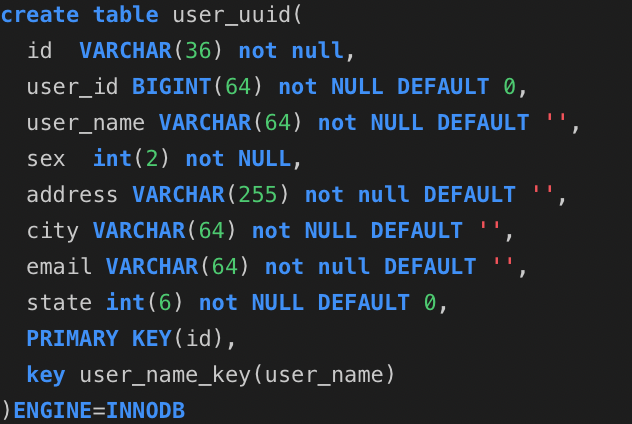
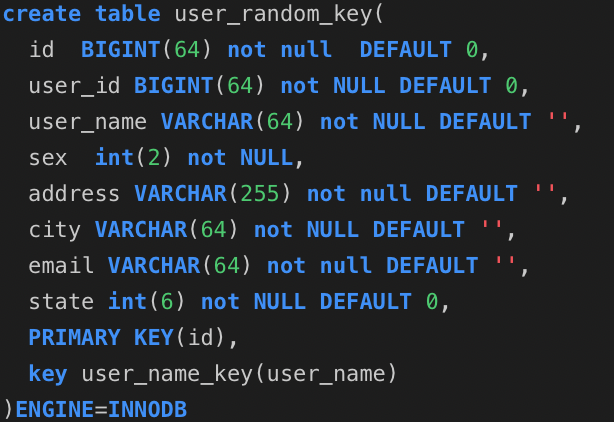
1.2:光有理论不行,直接上程序,使用spring的jdbcTemplate来实现增查测试:
package com.wyq.mysqldemo;
import cn.hutool.core.collection.CollectionUtil;
import com.wyq.mysqldemo.databaseobject.UserKeyAuto;
import com.wyq.mysqldemo.databaseobject.UserKeyRandom;
import com.wyq.mysqldemo.databaseobject.UserKeyUUID;
import com.wyq.mysqldemo.diffkeytest.AutoKeyTableService;
import com.wyq.mysqldemo.diffkeytest.RandomKeyTableService;
import com.wyq.mysqldemo.diffkeytest.UUIDKeyTableService;
import com.wyq.mysqldemo.util.JdbcTemplateService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.StopWatch;
import java.util.List;
@SpringBootTest
class MysqlDemoApplicationTests {
@Autowired
private JdbcTemplateService jdbcTemplateService;
@Autowired
private AutoKeyTableService autoKeyTableService;
@Autowired
private UUIDKeyTableService uuidKeyTableService;
@Autowired
private RandomKeyTableService randomKeyTableService;
@Test
void testDBTime() {
StopWatch stopwatch = new StopWatch("执行sql时间消耗");
/**
* auto_increment key任务
*/
final String insertSql = "INSERT INTO user_key_auto(user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?)";
List<UserKeyAuto> insertData = autoKeyTableService.getInsertData();
stopwatch.start("自动生成key表任务开始");
long start1 = System.currentTimeMillis();
if (CollectionUtil.isNotEmpty(insertData)) {
boolean insertResult = jdbcTemplateService.insert(insertSql, insertData, false);
System.out.println(insertResult);
}
long end1 = System.currentTimeMillis();
System.out.println("auto key消耗的时间:" + (end1 - start1));
stopwatch.stop();
/**
* uudID的key
*/
final String insertSql2 = "INSERT INTO user_uuid(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";
List<UserKeyUUID> insertData2 = uuidKeyTableService.getInsertData();
stopwatch.start("UUID的key表任务开始");
long begin = System.currentTimeMillis();
if (CollectionUtil.isNotEmpty(insertData)) {
boolean insertResult = jdbcTemplateService.insert(insertSql2, insertData2, true);
System.out.println(insertResult);
}
long over = System.currentTimeMillis();
System.out.println("UUID key消耗的时间:" + (over - begin));
stopwatch.stop();
/**
* 随机的long值key
*/
final String insertSql3 = "INSERT INTO user_random_key(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";
List<UserKeyRandom> insertData3 = randomKeyTableService.getInsertData();
stopwatch.start("随机的long值key表任务开始");
Long start = System.currentTimeMillis();
if (CollectionUtil.isNotEmpty(insertData)) {
boolean insertResult = jdbcTemplateService.insert(insertSql3, insertData3, true);
System.out.println(insertResult);
}
Long end = System.currentTimeMillis();
System.out.println("随机key任务消耗时间:" + (end - start));
stopwatch.stop();
String result = stopwatch.prettyPrint();
System.out.println(result);
}
1.3:程序写入结果
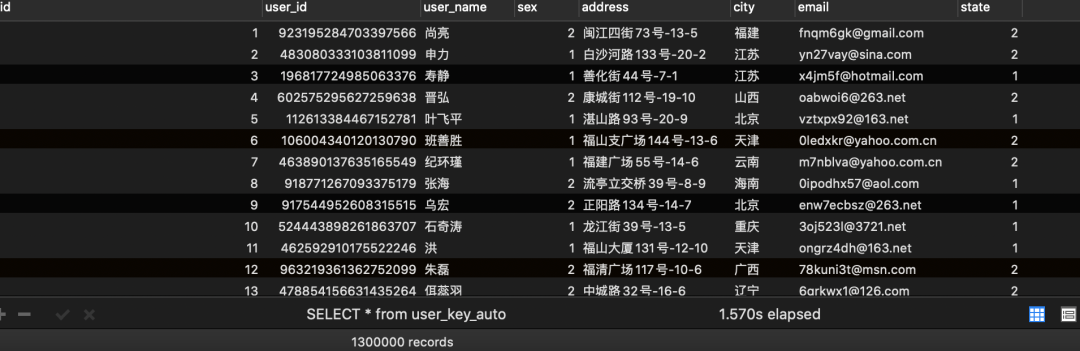
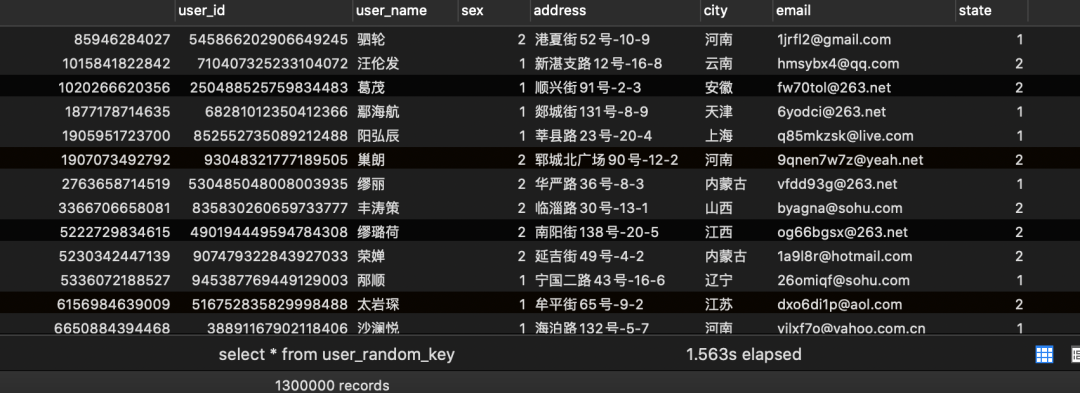
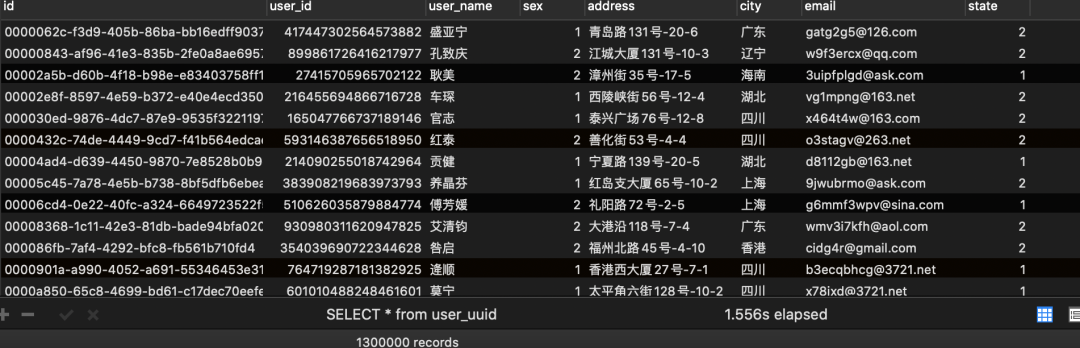
1.4:效率测试结果
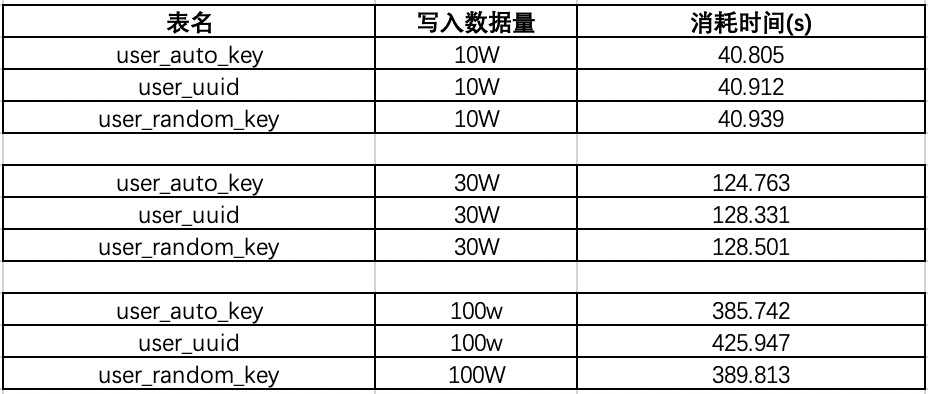

二:使用uuid和自增id的索引结构对比
2.1:使用自增id的内部结构
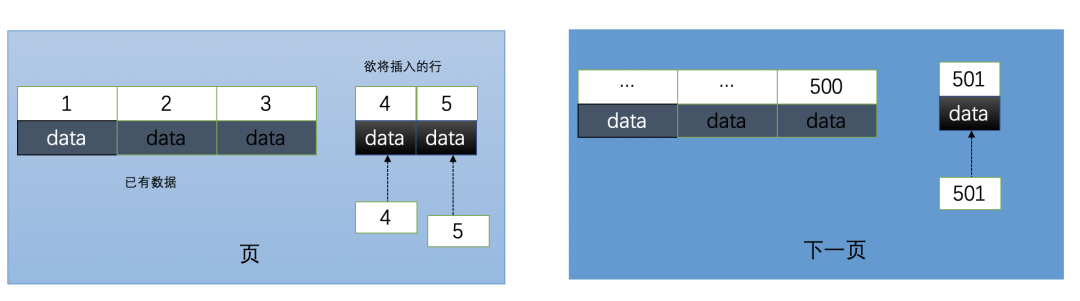
2.2:使用uuid的索引内部结构
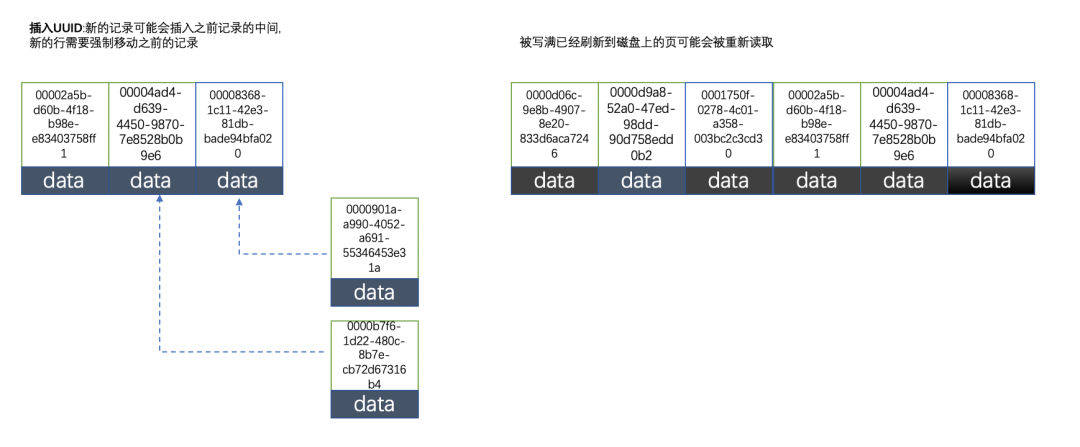
2.3:使用自增id的缺点
三:总结
评论