
当feapder爬虫框架遇上feapder爬虫管理系统是怎么样的体验
共 5099字,需浏览 11分钟
·
2021-07-29 09:10
不废话,直接进入主题,今天我们采集下百度搜索结果页,以此来了解下feapder以及feapder爬虫管理平台
安装feapder
pip3 install feapder==1.6.0 -i https://pypi.org/simple/
创建项目
> feapder create -p baidu-spider
baidu-spider 项目生成成功
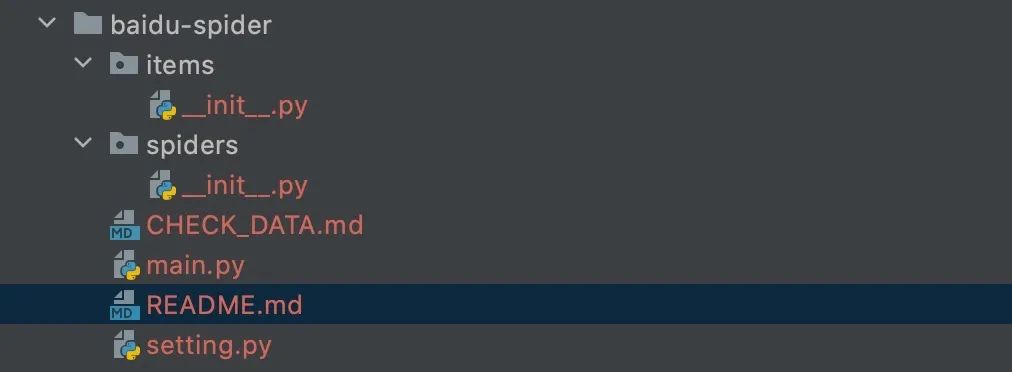
items 存放与数据库表映射的item spiders 存放爬虫脚本 main.py 启动入口 CHECK_DATA.md 数据审核模板 README.md 爬虫开发模板
创建爬虫
> feapder create -s baidu_spider
BaiduSpider 生成成功
生成baidu_spider.py文件
文件内容
import feapder
class BaiduSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
BaiduSpider().start()
这个baidu_spider.py是可以脱离项目直接运行的,因此创建项目那一步可以省略。有项目结构,是为了规范爬虫代码,大型的爬虫项目往往会有好多脚本。
编写爬虫
介于大家不喜欢废话,时间宝贵,直接贴编辑好的代码
baidu_spider.py
import feapder
from items import *
class BaiduSpider(feapder.AirSpider):
def start_requests(self):
# 采集10页
for i in range(0, 100, 10):
yield feapder.Request(f"https://www.baidu.com/s?wd=feapder&pn={i}")
def download_midware(self, request):
"""
下载中间件 可修改请求的一些参数
"""
# request.header = {}
return request
def validate(self, request, response):
"""
@summary: 校验函数, 可用于校验response是否正确
若函数内抛出异常,则重试请求
若返回True 或 None,则进入解析函数
若返回False,则抛弃当前请求
可通过request.callback_name 区分不同的回调函数,编写不同的校验逻辑
---------
@param request:
@param response:
---------
@result: True / None / False
"""
if response.status_code == 404:
return False # 则抛弃当前请求, 不会进入解析函数
if response.status_code != 200:
raise Exception("状态码错误") # 抛出异常,框架自动重试
def parse(self, request, response):
"""
解析列表
"""
results = response.xpath("//h3[@class='t']/a")
for result in results:
title = result.xpath("string(.)").extract_first()
url = result.xpath("./@href").extract_first()
# 数据自动入库
item = baidu_list_item.BaiduListItem()
item.title = title
item.url = url
yield item
# 采集详情页 并传值title
yield feapder.Request(url, callback=self.parse_detail, title=title)
def parse_detail(self, request, response):
"""
解析详情
"""
# 取值
title = request.title
html = response.text
# 数据自动入库
item = baidu_detail_item.BaiduDetailItem()
item.title = title
item.html = html
yield item
if __name__ == "__main__":
BaiduSpider(thread_count=100).start()
baidu_list_item.py
from feapder import Item
class BaiduListItem(Item):
"""
This class was generated by feapder.
command: feapder create -i baidu_list.
"""
def __init__(self, *args, **kwargs):
# self.id = None
self.title = None
self.url = None
baidu_detail_item.py
from feapder import Item
class BaiduDetailItem(Item):
"""
This class was generated by feapder.
command: feapder create -i baidu_detail.
"""
def __init__(self, *args, **kwargs):
# self.id = None
self.title = None
self.html = None
setting.py :配置了数据库连接信息
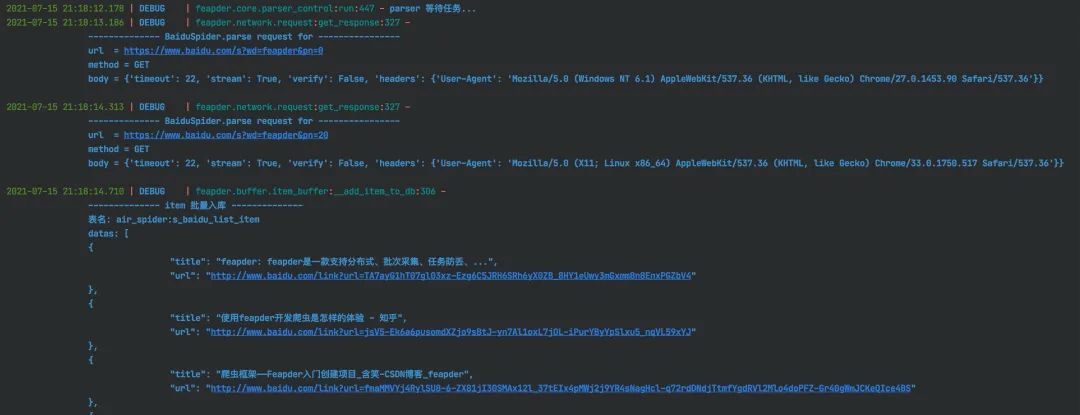
运行日志

落库数据
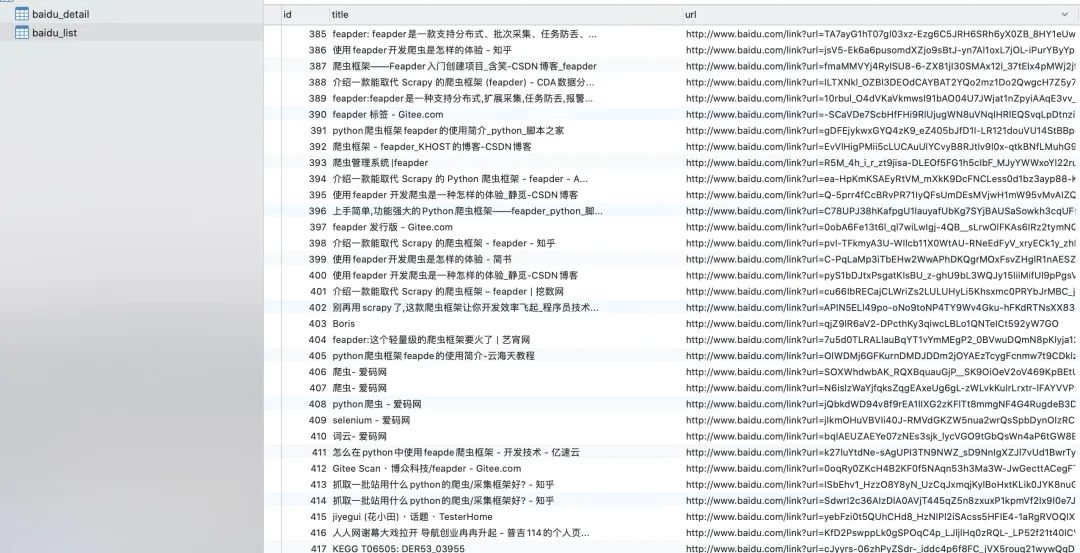
解释说明
item为表的映射,用feapder create -i [table_name] 自动生成。yield item 即完成了数据自动批量入库
同时,feapder提供了pipeline,可对接其他任何数据存储
分布式改造
feapder 提供了分布式爬虫,改造如下:
修改继承类
class BaiduSpider(feapder.Spider):
"""
分布式爬虫
"""修改启动参数
if __name__ == "__main__":
BaiduSpider(thread_count=100, redis_key="baidu_spider").start()启动参数多了个redis_key,用于指定redis里任务队列存储的key
分布式爬虫做了任务防丢策略,可随时重启,不用担心任务丢失,数据不完整 可开多个进程,同时抓取。
编辑main
现在,项目里存在两份爬虫,baidu_spider2.py是支持分布式的,我们编辑下main.py,指定统一的启动入口,方便管理
main.py
# -*- coding: utf-8 -*-
"""
Created on 2021-07-15 20:42:39
---------
@summary: 爬虫入口
---------
@author: Boris
"""
from spiders import *
from feapder.utils.custom_argparse import ArgumentParser
def _baidu_spider1():
baidu_spider.BaiduSpider(thread_count=100).start()
def _baidu_spider2():
baidu_spider2.BaiduSpider(thread_count=100, redis_key="baidu_spider").start()
if __name__ == "__main__":
parser = ArgumentParser(description="测试")
parser.add_argument(
"--baidu_spider", action="store_true", help="", function=_baidu_spider1
)
parser.add_argument(
"--baidu_spider2", action="store_true", help="", function=_baidu_spider2
)
parser.start()
部署
使用feapder爬虫管理平台部署,注意不仅支持feapder,也支持scrapy等任何脚本
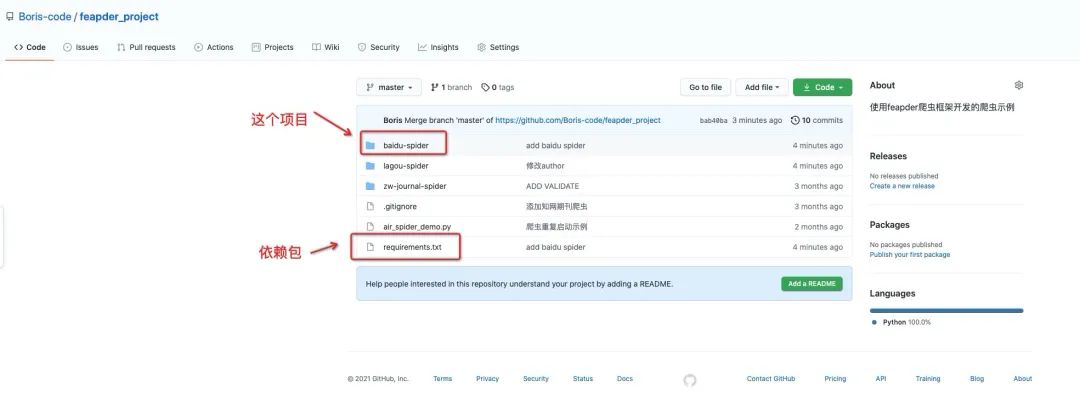
添加项目
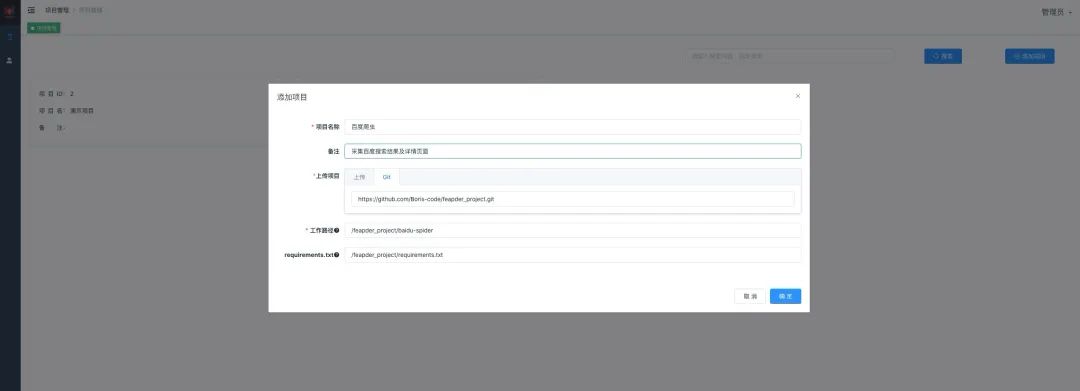
支持zip和git两种上传方式,使用git方式时,每次启动前都会自动拉取最新的代码来运行。
添加任务


添加了两个爬虫,支持定时调度,指定爬虫数。因为分布式爬虫支持启动多个实例,这里爬虫数启动了2个
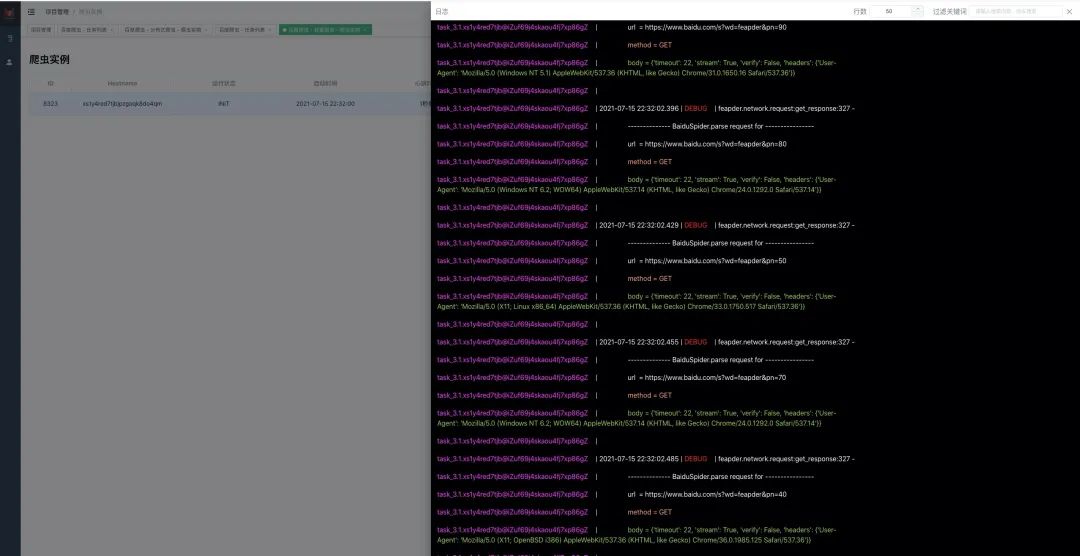
查看任务实例
查看下分布式爬虫的实例,已经起两个实例,正在初始化运行了

但由于从github拉取项目,网速的原因,导致拉取超时,打印日志如下:
将项目上传到码云,修改项目的Git地址为码云上的地址时,再次运行,成功啦
为什么用feapder爬虫管理系统
feapder爬虫管理系统与市面上已有的爬虫管理系统比较,优势在哪里?我们从架构说起
市面上已有的爬虫管理系统大多数都是 master、worker工作模式,worker节点常驻,等待master的指令执行任务。虽然都打包成了docker,但没有利用到docker swarm或k8s的弹性伸缩,都需要事先部署好worker
feapder爬虫管理系统的worker生命周期与爬虫生命周期一致,一个任务实例可以看为一个worker,爬虫启动时才创建,爬虫结束时销毁。系统架设在docker swarm集群上,正是因为worker的弹性伸缩,使系统的稳定性大大提升,一台服务器宕机,worker会自动迁移到其他服务器节点。若后续部署到阿里云的k8s上,在爬虫高峰期时,利用阿里云k8s自动伸缩机制,即可实现自动扩充服务器节点,爬虫高峰期过了自动释放服务器,降低成本
地址:
feapder文档:https://boris-code.gitee.io/feapder/#/
feapder爬虫管理系统 在上面的文档里有详细的介绍及部署步骤
本文的项目地址可关注公众号,回复【项目】获取
点击原文可看爬虫管理系统视频