
12 种经典亿级流量架构之资源隔离思想与方法论

- 为什么要资源隔离 -
线程隔离 进程隔离 集群隔离 机房隔离 读写隔离 动静隔离 爬虫隔离 等等
- 线程隔离 -
- Netty 主从程模型 -
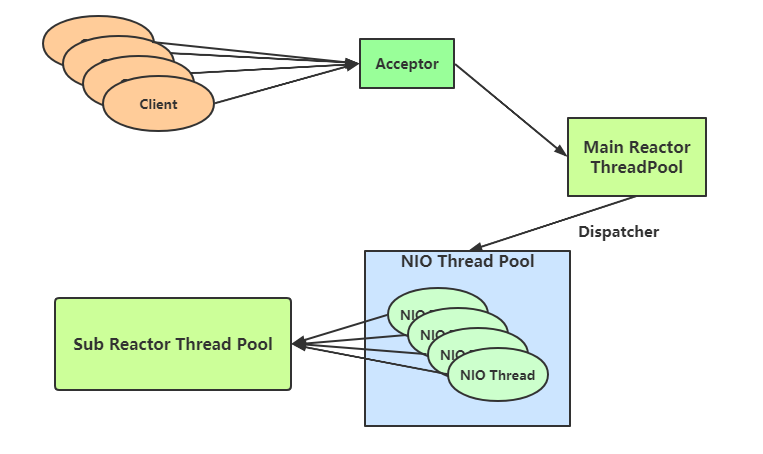
- Dubbo 线程隔离模型 -
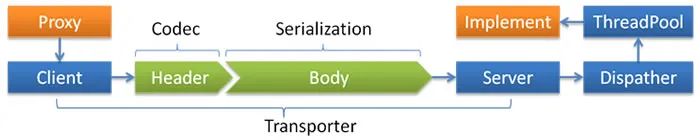
all 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。 direct 所有消息都不派发到线程池,全部在 IO 线程上直接执行。 message 只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。 execution 只有请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。 connection 在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
- Tomcat 请求线程隔离 -
同步非阻塞I/O操作,是一个基于缓冲区、并能提供非阻塞I/O操作的API,它拥有比传统I/O操作具有更好的并发性能。关于NIO,可以参考我这篇博客:NIO非阻塞网络编程原理。
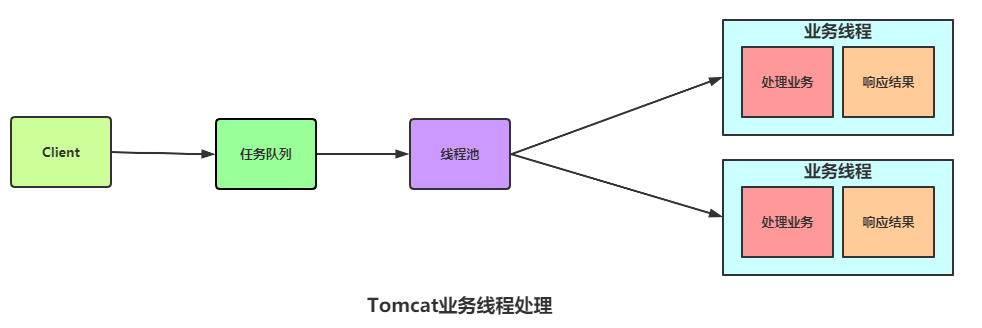
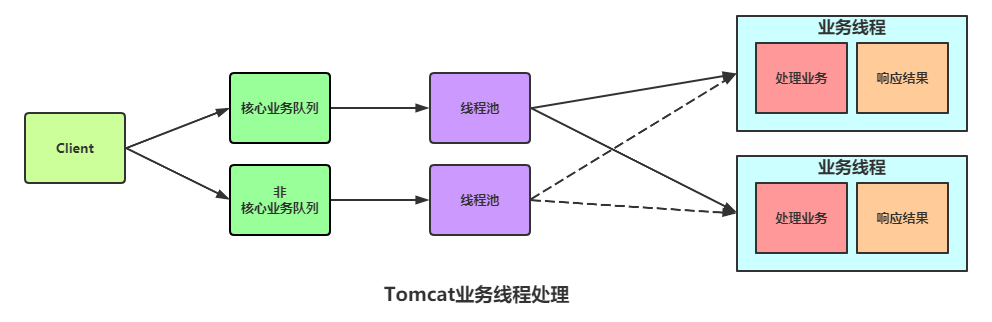
- 线程隔离小总结 -
资源一旦出现问题,虽然是隔离状态,想要让资源重新可用,很难做到不重启jvm。 线程池内部线程如果出现OOM、FullGC、cpu耗尽等问题也是无法控制的 线程隔离,只能保证在分配线程这个资源上进行隔离,并不能保证整体稳定性
- 进程隔离 -
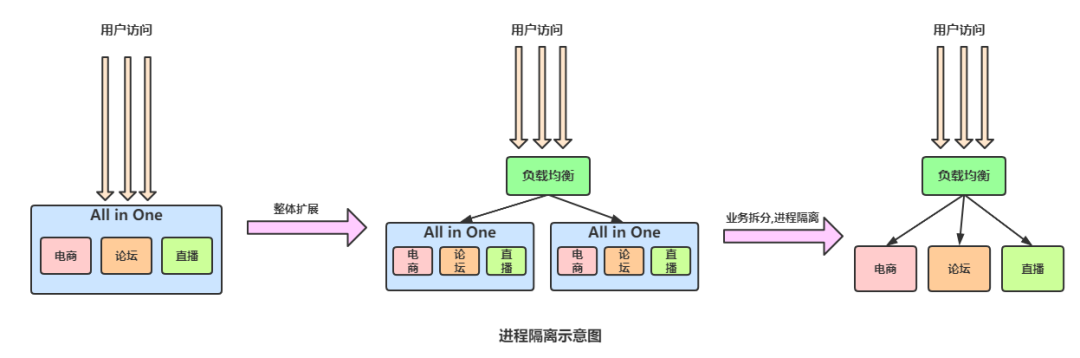
- 集群隔离 -
解决方案
独立拆分模块 微服务化
- 线程池隔离与信号量隔离对比 -
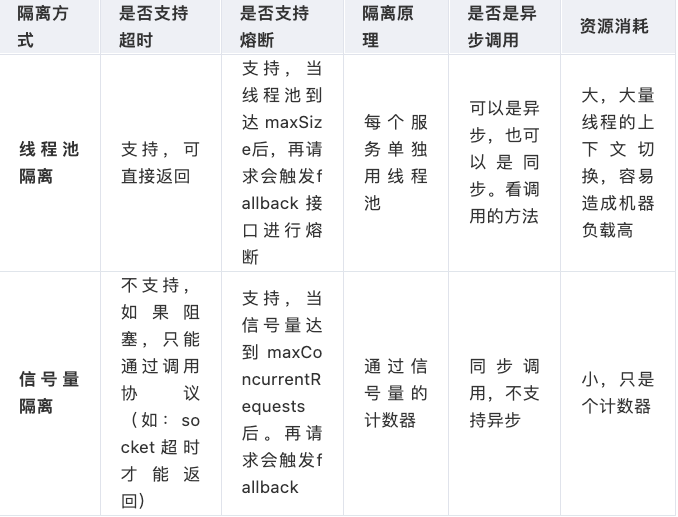
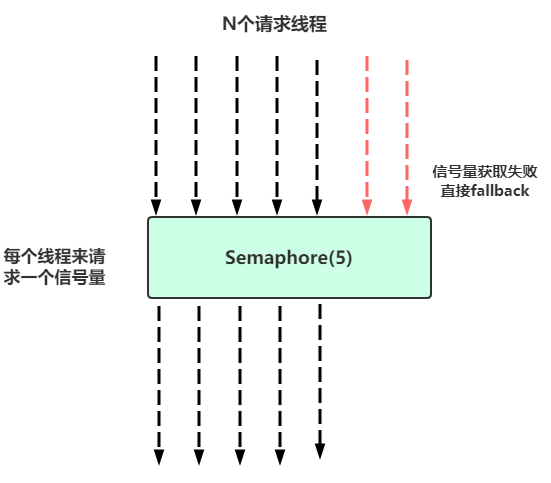
Generally the only time you should use semaphore isolation for HystrixCommands is when the call is so high volume (hundreds per second, per instance) that the overhead of separate threads is too high; this typically only applies to non-network calls.
隔离的细粒度太高,数百个实例需要隔离,此时用线程池做隔离开销过大 通常这种都是非网络调用的情况下
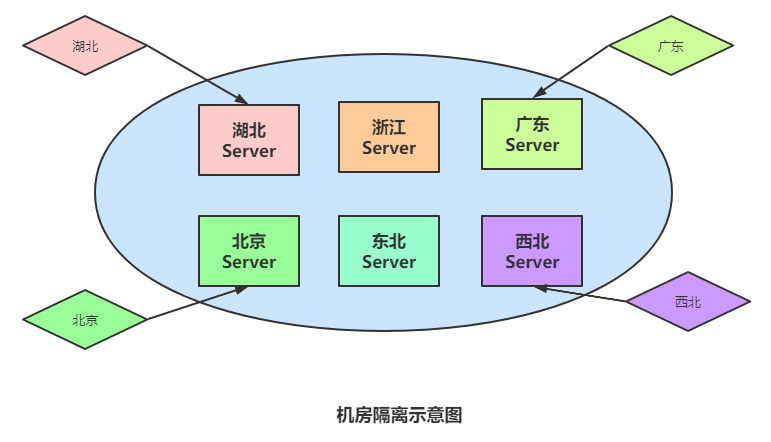
- 机房隔离 -
- 数据读写隔离 -
- 静态隔离 -
- 爬虫隔离 -
爬虫限流
登录/会话限制 下载限流 访问频率 ip限制,黑白名单
- UA 介绍 -
一种是:它用爬虫抓取公司主站B的内容并放到自己服务器上显示;
另一种是:通过将访问代理至公司主站B,而域名A是盗用者的,骗取流量。
作者:等不到的口琴
来源:
www.cnblogs.com/Courage129/p/14421585.html

评论