
TensorRT部署系列 | 如何将模型从 PyTorch 转换为 TensorRT 并加速推理?
点击下方卡片,关注「集智书童」公众号
作者丨Julie Bareeva (Xperience.AI)来源丨https://learnopencv.com/how-to-convert-a-model-from-pytorch-to-tensorrt-and-speed-up-inference/编辑丨小书童
机器学习工程师的生活包括长时间的挫折和片刻的欢乐!
首先,努力让你的模型在你的训练数据上产生好的结果。您可视化您的训练数据,清理它,然后再次训练。您阅读了机器学习中的偏差方差权衡(bias variance tradeoff)以系统地处理训练过程。
有一天,你的 PyTorch 模型经过完美训练,可以投入生产了。
那是纯粹的快乐!
您对准确性感到自豪,您在项目跟踪器中将您的任务标记为已完成,并通知您的 CTO 模型已准备就绪。
她不赞成地摇摇头,告诉你这个模型还没有在生产环境上准备好!训练模型是不够的。您需要修改模型,使其在运行(也称为推理)时高效。
你不知道如何进行。您好心的 CTO 告诉您在 http://LearnOpenCV.com 上阅读这篇关于 TensorRT 的帖子。因此,在这里您将对另一种学习体验感到高兴。
在本文中,如果您已经在PyTorch中训练了网络,您将学习如何快速轻松地使用「TensorRT」进行部署。
我们将使用以下步骤。
-
使用 PyTorch 训练模型 -
将模型转换为 ONNX 格式 -
使用 NVIDIA TensorRT 进行推理
在本教程中,我们仅使用预训练模型并跳过步骤 1。现在,让我们了解什么是 ONNX 和 TensorRT。
1、什么是 ONNX?
有许多用于训练深度学习模型的框架。最受欢迎的是 Tensorflow 和 PyTorch。但是,由 Tensorflow 训练的模型不能与 PyTorch 一起使用,反之亦然。
ONNX 代表开放神经网络交换。它是一种用于表示机器学习模型的开放格式。
您可以在您选择的任何框架中训练您的模型,然后将其转换为 ONNX 格式。
拥有通用格式的巨大好处是,在运行时加载模型的软件或硬件只需要与 ONNX 兼容。
ONNX 之于机器学习模型就像 JPEG 之于图像或 MPEG 之于视频。
2、什么是 TensorRT?
NVIDIA 的 TensorRT 是一个用于高性能深度学习推理的 SDK。
它提供 API 来对预训练模型进行推理,并为您的平台生成优化的运行时引擎。
有多种方法可以实现这种优化。例如,TensorRT 使我们能够使用 INT8(8 位整数)或 FP16(16 位浮点数)运算,而不是通常的 FP32。这种精度的降低可以显着加快推理速度,但精度会略有下降。
其他类型的优化包括通过重用内存、融合层和张量、根据硬件选择合适的数据层等来最大限度地减少 GPU 内存占用。
3、TensorRT 的环境设置
要重现本文中提到的实验,您需要NVIDIA显卡。任何比 Maxwell(算力5.0)更新的架构都可以。您可以在此处的表格中找到您的 GPU 计算能力:https://developer.nvidia.com/cuda-gpus#compute。不要忘记安装合适的驱动程序。
3.1 安装 PyTorch、ONNX 和 OpenCV
安装「Python 3.6」或更高版本并运行
python3 -m pip install -r requirements.txt
requirements.txt内容:
torch==1.2.0
torchvision==0.4.0
albumentations==0.4.5
onnx==1.4.1
opencv-python==4.2.0.34
代码在指定版本上进行了测试。但如果您已经安装了其中一些组件,则可以尝试在其他版本上启动它。
3.2 安装 TensorRT
-
按照官方说明下载并安装 NVIDIA CUDA 10.0或更高版本:https://developer.nvidia.com/cuda-10.0-download-archive -
下载并提取适用于您的 CUDA 版本的 CuDNN库(需要登录):https://developer.nvidia.com/rdp/cudnn-download -
下载并提取适用于您的 CUDA 版本的 NVIDIA TensorRT库(需要登录): https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html。所需的最低版本为 6.0.1.5。请按照您系统的安装指南(https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html)进行操作,不要忘记安装Python 的部分 -
将 CUDA、TensorRT、CuDNN 库的绝对路径添加到环境变量PATH或LD_LIBRARY_PATH -
安装PyCUDA( https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-pycuda)
我们现在准备好进行我们的实验。
4、如何将 PyTorch 模型转换为 TensorRT
让我们回顾一下将 PyTorch 模型转换为 TensorRT 所需的步骤。
1. 使用 PyTorch 加载并启动预训练模型
首先,让我们在 PyTorch 上使用预训练网络实现一个简单的分类。例如,我们将采用Resnet50,但您可以选择任何您想要的。您可以在此处找到有关如何使用 PyTorch 的更多信息和解释:# PyTorch for Beginners: Image Classification using Pre-trained models
from torchvision import models
model = models.resnet50(pretrained=True)
下一个重要步骤:「预处理」输入图像。我们需要知道在训练期间进行了哪些转换以在推理的时候复制它们。我们推荐以下模块用于预处理步骤:「albumentations」和「cv2」 (OpenCV)。
该模型在大小为 224×224 的图像上进行训练。然后将输入数据归一化(将像素值除以 255,减去平均值并除以标准差)。
import cv2
import torch
from albumentations import Resize, Compose
from albumentations.pytorch.transforms import ToTensor
from albumentations.augmentations.transforms import Normalize
def preprocess_image(img_path):
# transformations for the input data
transforms = Compose([
Resize(224, 224, interpolation=cv2.INTER_NEAREST),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensor(),
])
# read input image
input_img = cv2.imread(img_path)
# do transformations
input_data = transforms(image=input_img)["image"]
准备批次以传递到网络。在我们的案例中,批处理中只有一张图像。请注意,我们将输入数据上传到 GPU 以更快地执行程序,使我们与 TensorRT 的比较更加公平。
batch_data = torch.unsqueeze(input_data, 0)
return batch_data
input = preprocess_image("turkish_coffee.jpg").cuda()
现在我们可以进行推理了。不要忘记将模型切换到评估模式并将其也复制到 GPU。结果,我们将得到对象属于哪个类的概率 tensor[1, 1000]。
model.eval()
model.cuda()
output = model(input)
为了获得人类可读的结果,我们需要后处理步骤。分类标签可以在imagenet_classes.txt中找到。计算Softmax以获得每个类别的百分比并打印网络预测的最高类别。
def postprocess(output_data):
# get class names
with open("imagenet_classes.txt") as f:
classes = [line.strip() for line in f.readlines()]
# calculate human-readable value by softmax
confidences = torch.nn.functional.softmax(output_data, dim=1)[0] * 100
# find top predicted classes
_, indices = torch.sort(output_data, descending=True)
i = 0
# print the top classes predicted by the model
while confidences[indices[0][i]] > 0.5:
class_idx = indices[0][i]
print(
"class:",
classes[class_idx],
", confidence:",
confidences[class_idx].item(),
"%, index:",
class_idx.item(),
)
i += 1
postprocess(output)
是时候测试我们的脚本了!我们的输入图像:

结果:
class: cup, confidence: 92.430747%, index: 968
class: espresso, confidence: 6.138075%, index: 967
class: coffee mug, confidence: 0.728557%, index: 504
2.将PyTorch模型转换为ONNX格式
要转换生成的模型,您只需要一行代码torch.onnx.export,它需要以下参数:「预训练模型本身、与输入数据大小相同的张量、ONNX 文件的名称、输入和输出名称」。
ONNX_FILE_PATH = 'resnet50.onnx'
torch.onnx.export(model, input, ONNX_FILE_PATH, input_names=['input'],
output_names=['output'], export_params=True)
要检查模型转换是否正常,请调用onnx.checker.check_model:
onnx_model = onnx.load(ONNX_FILE_PATH)
onnx.checker.check_model(onnx_model)
3. 可视化ONNX模型
现在,让我们使用Netron可视化我们的 ONNX 图。要启动它,请安装:
python3 -m pip install netron
在命令行输入netron并在浏览器中打开http://localhost:8080/。您将看到完整的网络图。检查输入和输出是否具有预期的大小。
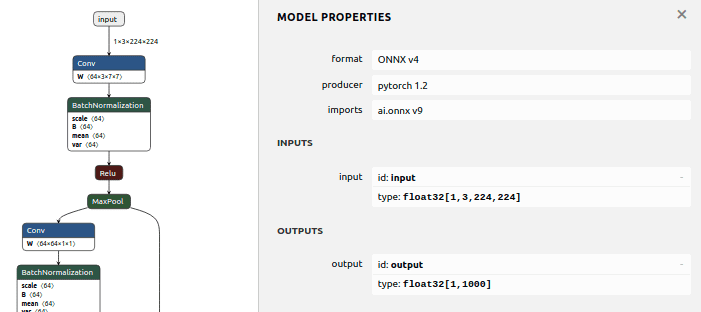
4. 在TensorRT中初始化模型
现在是解析 ONNX 模型并初始化 TensorRT 「Context」和「Engine」的时候了。为此,我们需要创建一个Builder实例。Builder可以创建network并从该网络生成engine(将针对您的平台\硬件进行优化)。当我们创建network时,我们可以通过标志定义网络的结构,但在我们的例子中,使用默认标志就足够了,这意味着所有张量都将具有隐式批次维度。通过network定义,我们可以创建一个Parser实例,最后解析我们的 ONNX 文件。
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import tensorrt as trt
# logger to capture errors, warnings, and other information during the build and inference phases
TRT_LOGGER = trt.Logger()
def build_engine(onnx_file_path):
# initialize TensorRT engine and parse ONNX model
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
parser = trt.OnnxParser(network, TRT_LOGGER)
# parse ONNX
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
可以配置一些engine参数,例如 TensorRT engine允许的最大内存或设置 FP16 模式。我们还应该指定批次的大小。
# allow TensorRT to use up to 1GB of GPU memory for tactic selection
builder.max_workspace_size = 1 << 30
# we have only one image in batch
builder.max_batch_size = 1
# use FP16 mode if possible
if builder.platform_has_fast_fp16:
builder.fp16_mode = True
之后,我们可以生成「Engine」并创建可执行文件「Context」。engine获取输入数据、执行推理并发出推理输出。
# generate TensorRT engine optimized for the target platform
print('Building an engine...')
engine = builder.build_cuda_engine(network)
context = engine.create_execution_context()
print("Completed creating Engine")
return engine, context
提示:初始化可能会花费很多时间,因为 TensorRT 会尝试找出在您的平台上执行网络的最佳和更快的方式。要只执行一次然后使用已经创建的引擎,您可以序列化您的引擎。「序列化」引擎不能跨不同的 GPU 模型、平台或 TensorRT 版本移植。引擎特定于它们所基于的确切硬件和软件。可以在此处找到更多信息:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#serial_model_c。
5. 主函数
那么在 TensorRT 中进行推理的完整流程会是什么样子呢?让我们看一下「主函数」。首先,让我们解析模型并初始化engine和context:
def main():
# initialize TensorRT engine and parse ONNX model
engine, context = build_engine(ONNX_FILE_PATH)
当我们拥有初始化引擎时,我们可以找出程序中输入和输出的维度。要知道我们可以分配输入数据和输出数据所需的内存。在常见情况下,一个模型可以有一堆输入和输出,但在我们的例子中,我们知道我们只有一个输入和一个输出。
# get sizes of input and output and allocate memory required for input data and for output data
for binding in engine:
if engine.binding_is_input(binding): # we expect only one input
input_shape = engine.get_binding_shape(binding)
input_size = trt.volume(input_shape) * engine.max_batch_size * np.dtype(np.float32).itemsize # in bytes
device_input = cuda.mem_alloc(input_size)
else: # and one output
output_shape = engine.get_binding_shape(binding)
# create page-locked memory buffers (i.e. won't be swapped to disk)
host_output = cuda.pagelocked_empty(trt.volume(output_shape) * engine.max_batch_size, dtype=np.float32)
device_output = cuda.mem_alloc(host_output.nbytes)
CUDA 函数可以在流中异步调用。一个流中的所有命令将按顺序执行,但不同的流可以同时或乱序执行它们的命令。当您在未指定流的情况下执行异步 CUDA 命令时,运行时将使用默认的空流。在我们的简单脚本中,我们将只创建一个流就足够了。例如,在更复杂的情况下,您可以使用不同的流同时处理不同的图像。
# Create a stream in which to copy inputs/outputs and run inference.
stream = cuda.Stream()
为了在 TensorRT 中获得与在 PyTorch 中相同的结果,我们将为推理准备数据并重复我们之前采取的所有预处理步骤。TensorRT 的 Python API 的主要好处是可以从 PyTorch 部分重用数据预处理和后处理。我们应该做的唯一额外的事情是连续放置数据并尽可能使用page-locked memory。然后我们可以将该数据复制到 GPU 并将其用于推理。
# preprocess input data
host_input = np.array(preprocess_image("turkish_coffee.jpg").numpy(), dtype=np.float32, order='C')
cuda.memcpy_htod_async(device_input, host_input, stream)
进行推理并将结果从设备复制到主机:
# run inference
context.execute_async(bindings=[int(device_input), int(device_output)], stream_handle=stream.handle)
cuda.memcpy_dtoh_async(host_output, device_output, stream)
stream.synchronize()
结果将存储为host_output的一维数组。因此,在使用 PyTorch 部分的后处理来获取人类可读的值之前,我们应该对其进行reshape。
# postprocess results
output_data = torch.Tensor(host_output).reshape(engine.max_batch_size, output_shape[0])
postprocess(output_data)
就这样!现在您可以启动脚本并对其进行测试。
6. 精度测试
我们做了一些临时测试,总结在下表中。
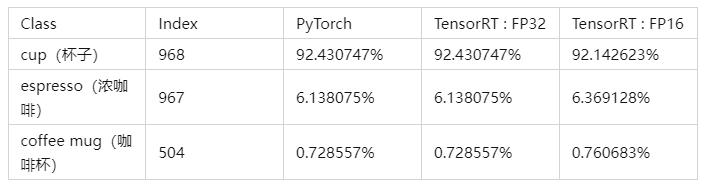
正如我们所见,预测的类别匹配。置信度和 FP32 模式下几乎相同(误差小于 1e-05)。在 FP16 模式下错误更大(~0.003),但它仍然足以获得正确的预测。
请记住,不能保证您在使用不同的硬件、软件甚至输入图片进行测试时会遇到相同的精度。该精度可能取决于初始基准决策,并且可能因不同的卡而不同。我们通过以下配置获得这些结果:
Ubuntu 18.04.4, AMD® Ryzen 7 2700x eight-core processor × 16, GeForce RTX 2070 SUPER, TensorRT 6.0.1.5, CUDA 10.0
7. 使用 TensorRT 加速
为了比较 PyTorch 和 TensorRT 中的时间,我们不会测量模型的初始化时间,因为我们只初始化了一次。所以我们将比较推理时间。在首次启动时,CUDA 会初始化并缓存一些数据,因此任何 CUDA 函数的首次调用都比平时慢。为了解决这个问题,我们运行推理几次并获得平均时间。我们拥有:
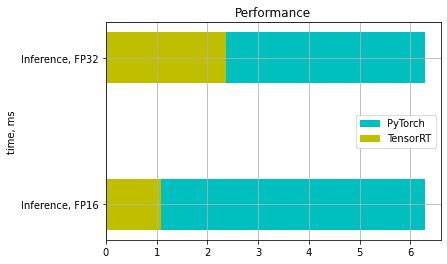
在我们的示例中,我们在 FP16 模式下实现了 4-6 倍的加速,在 FP32 模式下实现了 2-3 倍的加速。
5、推荐阅读
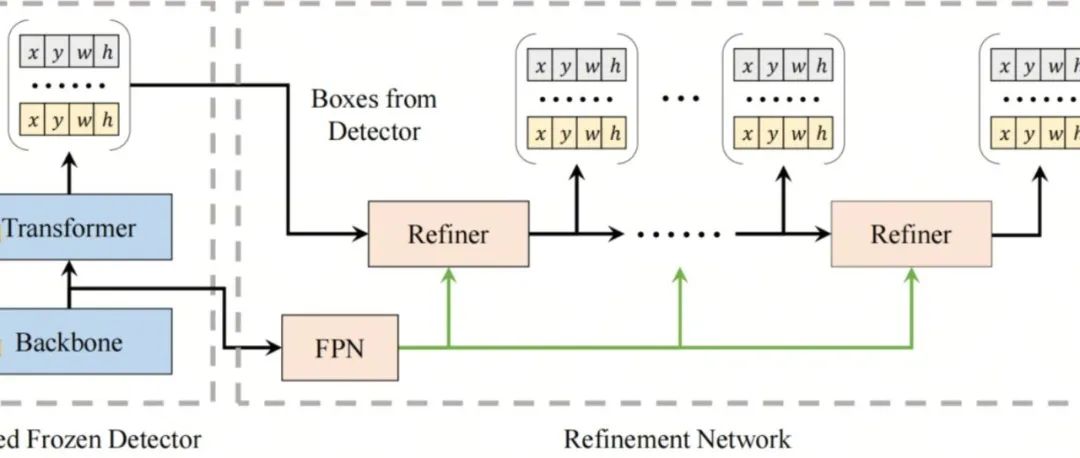
DETR即插即用 | RefineBox进一步细化DETR家族的检测框,无痛涨点
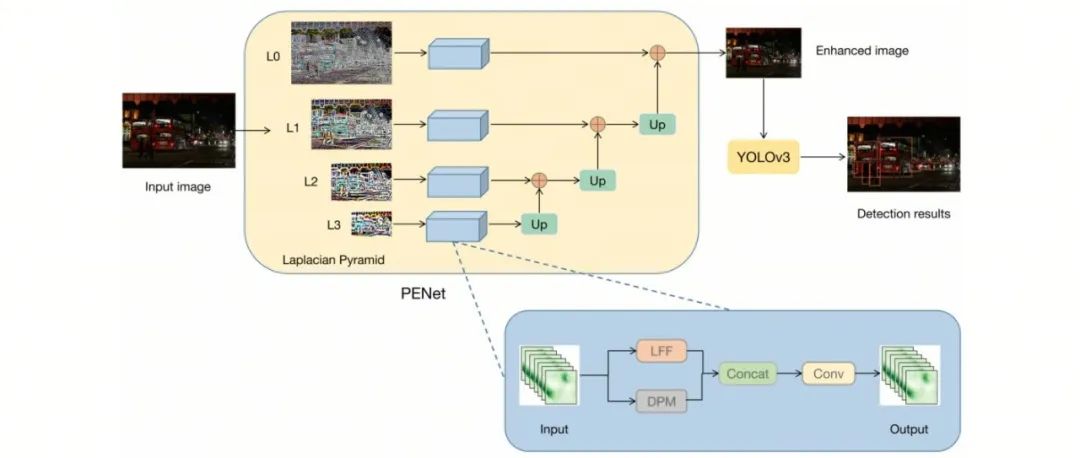
中科大提出PE-YOLO | 让YOLO家族算法直击黑夜目标检测

超越GIoU/DIoU/CIoU/EIoU | MPDIoU让YOLOv7/YOLACT双双涨点,速度不减!

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!