
手把手教你搞定4类数据清洗操作
导读:本文介绍数据清洗的相关内容,主要涉及缺失值清洗、格式内容清洗、逻辑错误清洗和维度相关性检查四个方面。

# 检查数据缺失情况
def check_missing_data(df):
return df.isnull().sum().sort_values(ascending = False)
check_missing_data(rawdata)
Income 1
Age 1
Online Shopper 0
Region 0
dtype: int64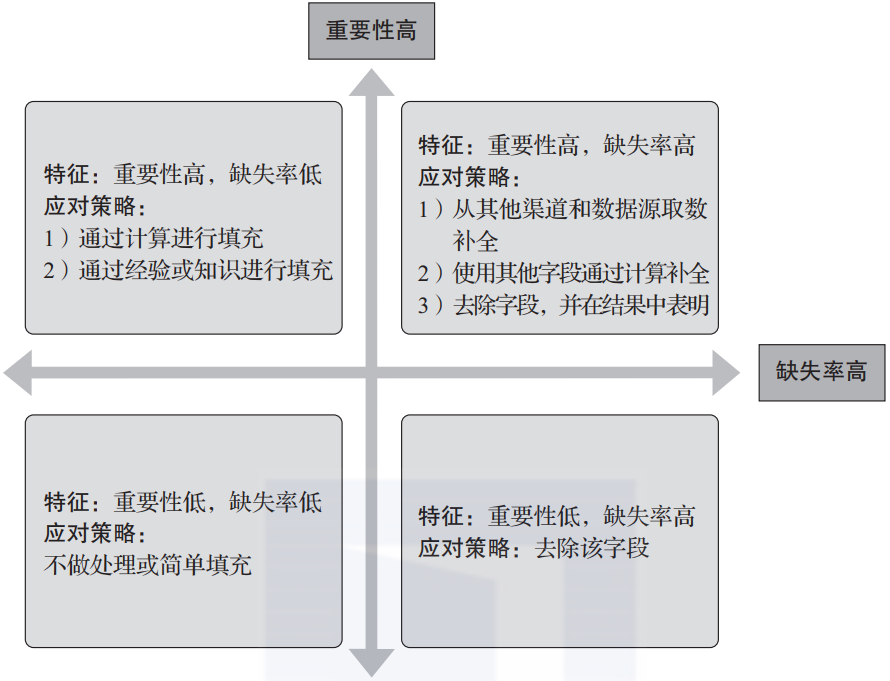
test1 = rawdata.copy()# 将更改前的数据进行备份
test1 = test1.head(3)# 提取前三行进行测试
test1 = test1.dropna()# 去除数据中有缺失值的行
print(test1)
test1
name toy born
0 Andy NaN NaN
1 Cindy Gun 1998-12-25
2 Wendy Gum NaN
test1 = test1.dropna(axis=0)# 去除数据中有缺失值的行
name toy born
1 Cindy Gun 1998-12-25
test1 = test1.dropna(axis='columns')# 去除数据中有缺失值的列
name
0 Andy
1 Cindy
2 Wendy
test1 = test1.dropna(how='all')# 去除数据完全缺失的行
test1 = test1.dropna(thresh=2)# 保留行中至少有两个值的行
test1 = test1.dropna(how='any')# 去除数据中含有缺失值的行
test1 = test1.dropna(how='any',subset=['toy'])# 去除toy列中含有缺失值的行
test1.dropna(inplace=True)# 在这个变量名中直接保存结果test1 = test1.fillna(test1.mean())# 用均值填充缺失值
test1 = test1.fillna(test1.median())# 用中位数填充缺失值
test1 = test1.fillna(test1.mode())# 用众数填充缺失值
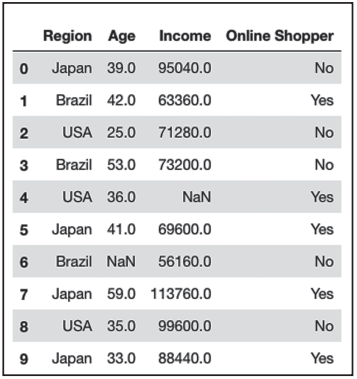
dataset.isna().sum() # 统计各列缺失值情况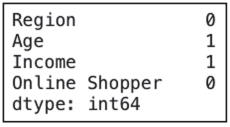
# 设定填充方式为平均值填充
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 选取目标列
imputer = imputer.fit(rawdata.iloc[:,1:3])
# 对计算结果进行填充
rawdata.iloc[:,1:3] = imputer.transform(rawdata.iloc[:,1:3])
# 调整数据
rawdata.iloc[:,1:3] = rawdata.iloc[:,1:3].round(0).astype(int) 身份证号必须是数字+字母。 中国人姓名只能为汉字(李A、张C这种情况是少数)。 出现在头、尾、中间的空格。
每日食品中卡路里摄入量跟体重很有可能有较大的相关性; 子女和父母血型之间具有高关联性; 学习的时间长度和考试成绩通常也有高关联性。
rawdata.corr() # 相关性矩阵 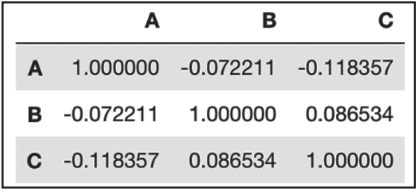
rawdata.cov() # 协方差矩阵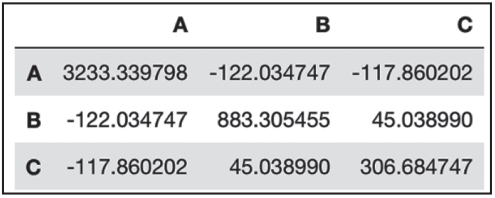
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
评论