
Flink 优化 | Flink_state 的优化与 remote_state 的探索
相关背景
1.1 业务概况

业务规模,B 站目前大约是 4000+的 Flink 任务,其中 95%是 SQL 类型。
部署模式,B 站有 80%的部署是 on yarn application 部署,我们的 yarn 集群和离线的 yarn 是分开的,是实时专用的 yarn 集群。剩下的 20%作业,为了响应公司降本增效的号召,目前是在线集群混部。这个方案的采用主要是从成本考虑,目前在使用 yarn on docker。
-
state 使用情况,平台默认开启的全部是 rocksdb statebackend,大概有 50%的任务都是带状态的,其中有上百个任务的状态超过了 500GB,这种任务我们称之为超大状态的 state 任务。
1.2 statebackend 痛点

主要痛点有 3 个:
cpu 抖动大。rocksdb 的原理决定了它一定会有一个 compaction 的操作。目前,在小状态下这种操作对任务本身没什么影响,但是在大状态下,尤其是超过 500GB 左右,compaction 会造成 cpu 抖动大,峰值资源要求高。尤其是在 5、10、15 分钟这种 checkpoint 的整数被间隔的情况下,整个 cpu 的起伏会比较高。对于一个任务来说,它的峰值资源要求会比较高。如果我们的资源满足不了峰值资源的需求,任务就会触发一阵阵的堆积和消积的情况。
恢复时间长。因为 rocksdb 是一个嵌入式的 DB 存储,每次重启或者任务的 rescale 状态恢复时间长。因为它要把很大的文件下载下来,然后再在本地进行一些重新的 reload,这就需要一些大量的扫描工作,所以会导致整个任务的状态恢复时间比较长。观察下来,正常来说大任务基本需要 5 分钟左右才能恢复平稳的状态。
-
rocksdb 非常依赖本地磁盘。rocksdb 是嵌入式的 DB,所以会非常依赖本地 io 的能力。由于今年公司有降本增效的策略,我们也会在线推荐一些混部,因为 Flink 的带状态任务有对本地 io 依赖的特点,对于混部来讲是没法用的,这就导致我们使用混部的资源是非常有限的。

主要通过两个方面解决这些痛点:
第一个是 state 压缩。出于对如何降低 compaction 开销的思考,对任务进行了一些 cpu 火焰图的分析。通过分析发现,整个 cpu 的消耗主要在 2 个方面,一个是 compaction,一个是压缩数据的换进换出,这就会带来大量的压缩和解压缩的工作。所以我们在压缩层做了一些工作。
-
第二个是基于云原生的部署。由于本地没有 io 能力,我们参考了一些云原生的方案,把整个本地的 rocksdb backend 进行了 Remote state 的升级。这相当于上面的一个存算分离,然后远程进行了服务化的操作。这样就可以实现即连即用,不需要进行 reload 的操作,整个 state 是基于远程化进行的。
state 压缩优化
2.1 业务场景
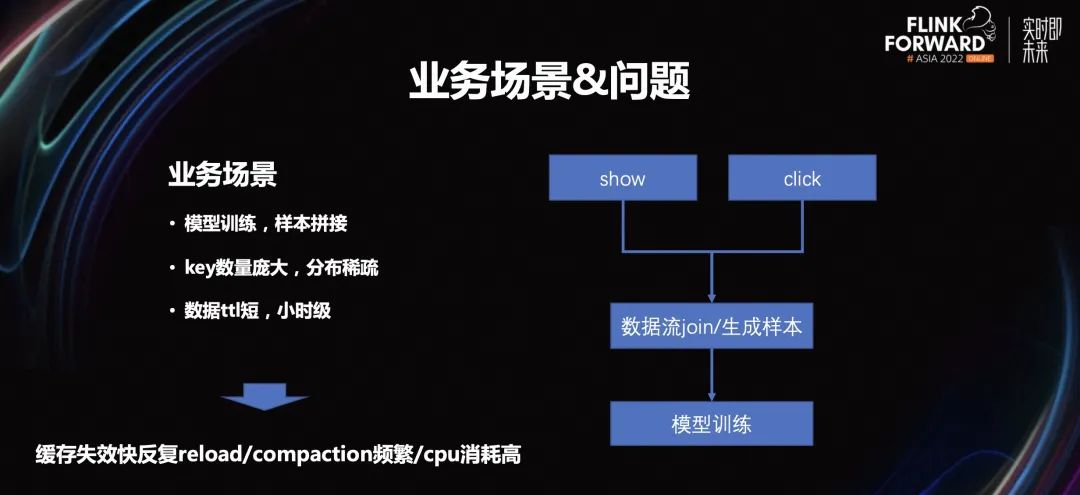
2.2 优化思路

第一个是开启 partitoned index filter,减少缓存竞争。从火焰图中可以看到,data block 会不断地从 block cache 中被换进换出,同时产生大量的压缩和解压缩工作,大量的 cpu 其实消耗在这里。
第二个是关闭 rocksdb 压缩,减少缓存加载 /compaction 时候的 cpu 消耗。从火焰图中可以看到,整个 SSD 数据进行底层生成的时候,它会不断地进行整个文件的压缩和解压缩。所以我们的思路就是如何去关闭一些 rocksdb 压缩,减少整个缓存加载或者 cpu 的消耗。
-
第三个是支持接口层压缩,在数据 state 读写前后进行解压缩操作,减少 state 大小。如果关闭 rocksdb 底层的压缩,我们观察到整个磁盘的使用量非常高。这样的话,压力就是从压缩和解压缩的 cpu 消耗变成磁盘的 io 消耗,磁盘的 io 很容易就被消耗尽了。所以我们就把整个底层的压缩往上层进行了一个牵引,支持接口层的压缩。
2.3 整体架构
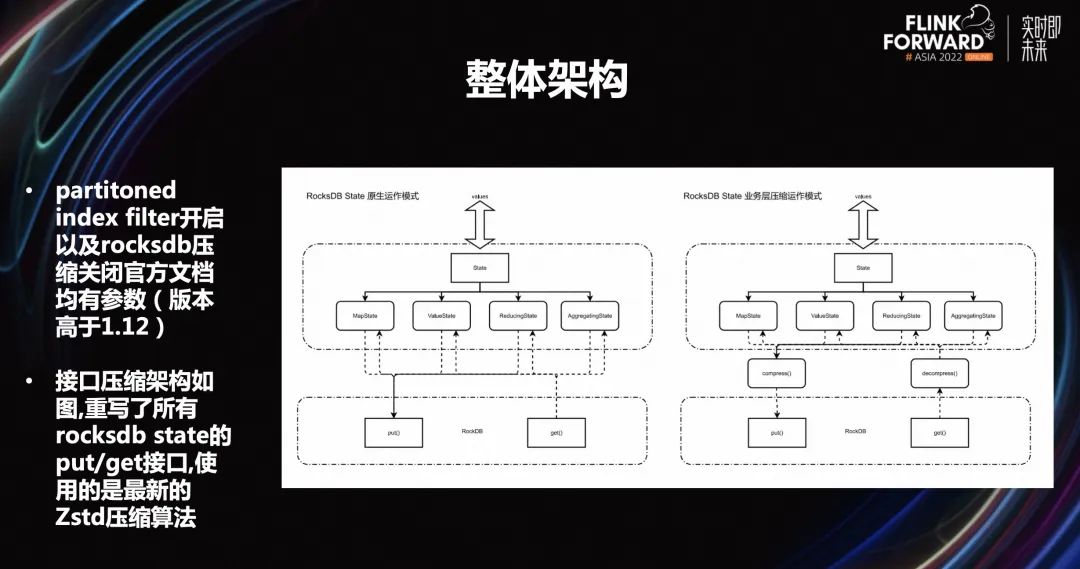
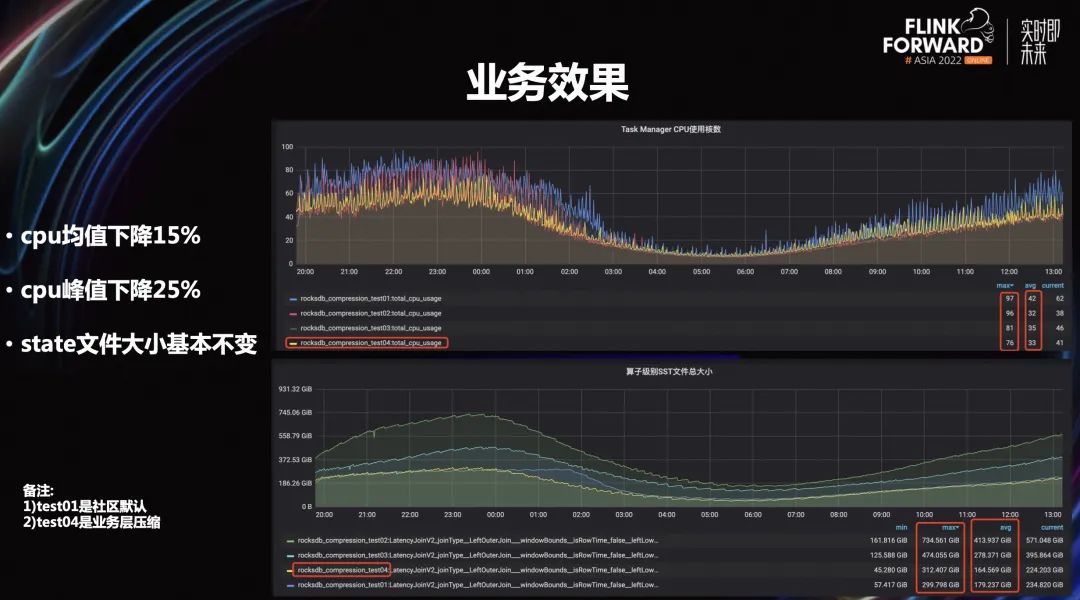
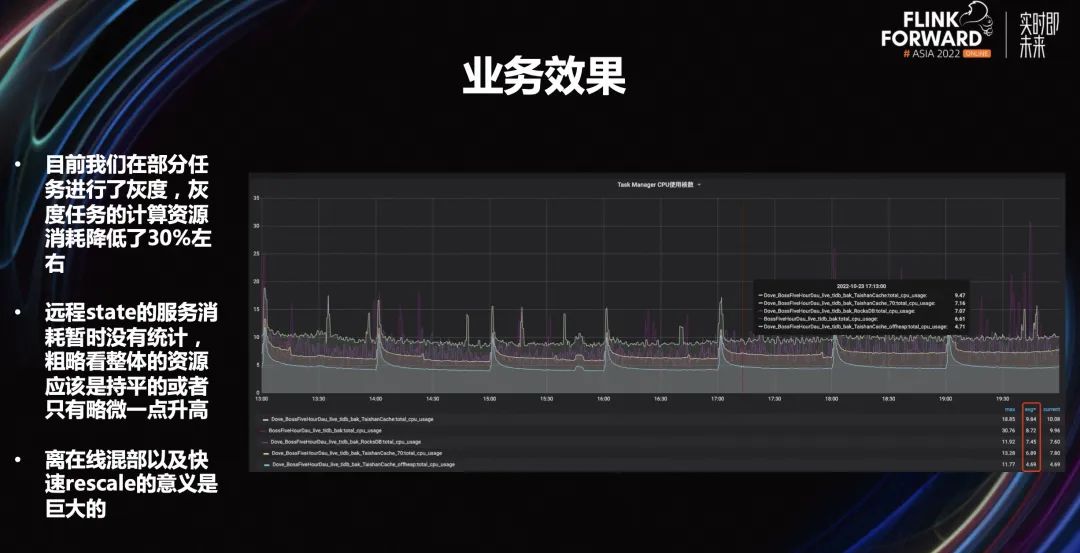
2.4 业务效果

Remote state 探索
3.1 业务场景和问题
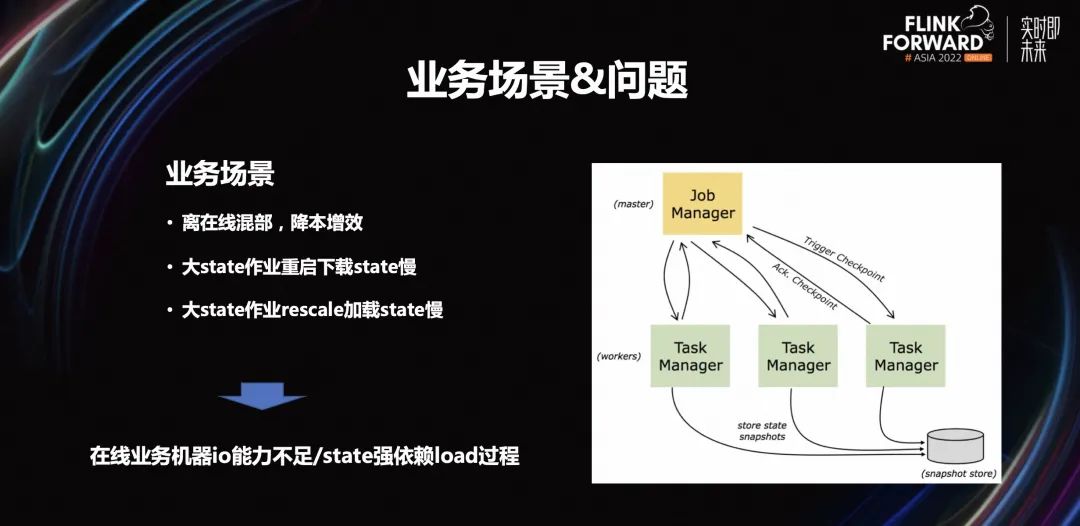
3.2 优化思路

3.3 整体架构
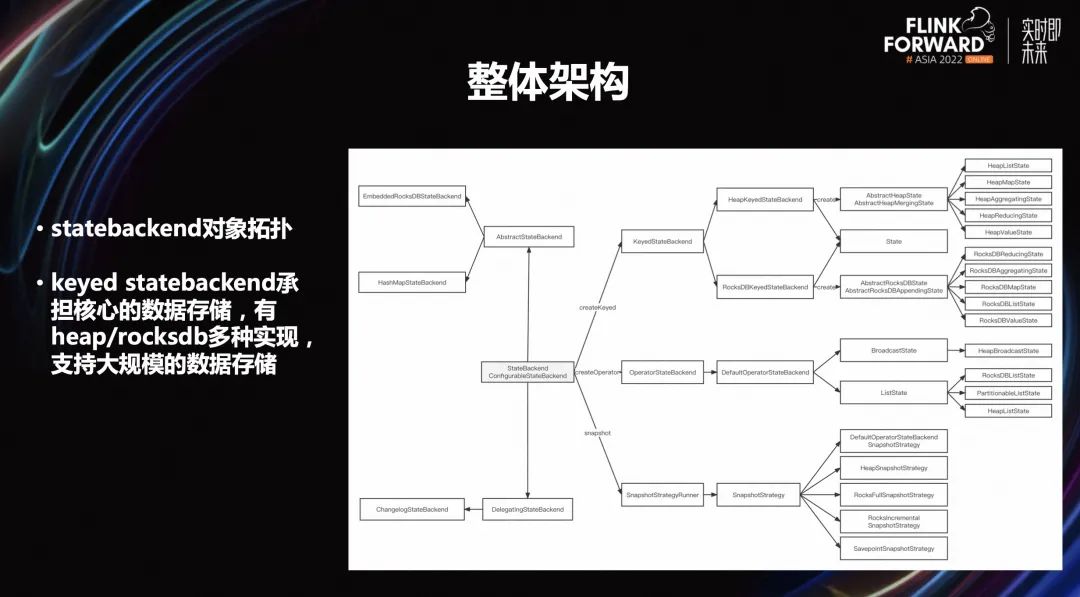

上图是社区 keyed statebackend 的分配逻辑架构。如果想要把 keyed statebackend 做存算分离,需要了解:
Flink 的分片逻辑,它的底层有一个 keyed group 的概念。在所有状态在任务第一次启动的时候,底层分片就已经确定好了。这个分片大小就是 Flink 的最大并发度的值。这个最大并发度实际上是在任务第一次不从 checkpoint 启动时候算出来的。这中间如果一直从 checkpoint 启动,那么最大并发度永远不会变。
Flink checkpoint rescale 能力是有限的,本质是分片 key-group 在 subtask 之间的移动,分片无法分裂。一旦启动生成切换之后,这个分片的数量因为已经固定好了,后面不管怎么 rescale,本质是分片的移动,其实最大的变动是后面 rescale 不能超过整个分片的数量,这个数量对应的是分片最大的并发度。
-
多个 key-group 存储在相同 rocksdb 的 cf 里面,以 key-group 的 ID 作为 key 的 prefix,依赖 rocksdb 的排序特性,rescale 过程通过 prefix 进行定位遍历提取。
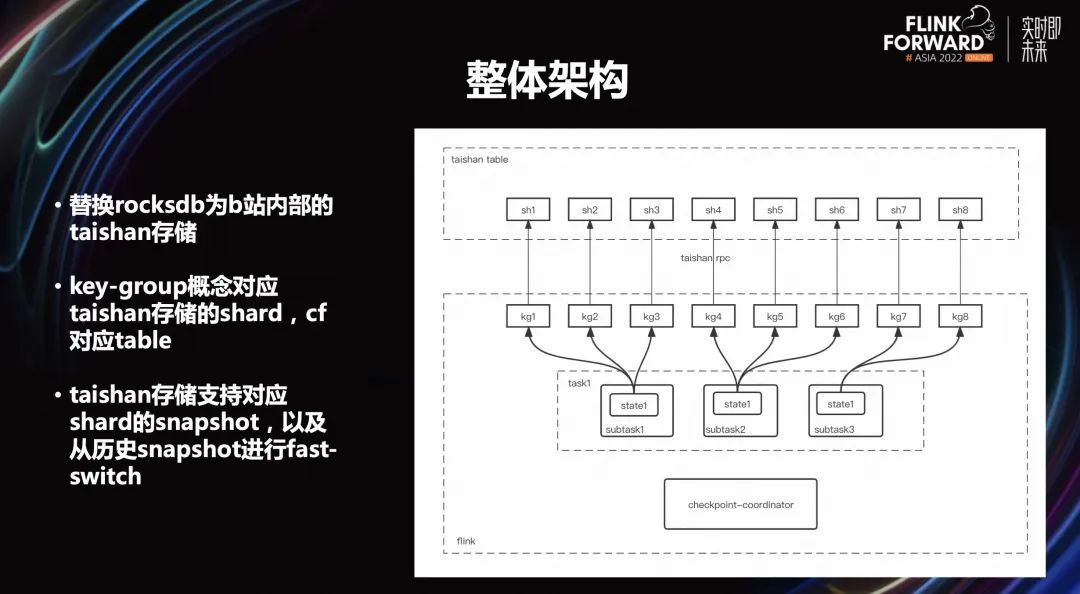
上图是 Remote state 整体架构,主要的核心工作有三点:
替换 rocksdb 为 B 站内部的 taishan 存储。Taishan 存储底层是分布式结构,Flink 的一些概念是可以对应到 taishan 存储上的。
key-group 概念对应 taishan 存储的 shard,cf 对应 table。key-group 的概念就可以对应上 taishan 存储,同时里面 cf 的概念也对应 taishan 存储中的一个 table 概念,也支持一个 table 里面可以有多个 key-group。
-
Taishan 存储支持对应 shard 的 snapshot,以及从历史的 snapshot 进行快速切换。比如重启的时候可以从老的 checkpoint 进行回复,实际上能够调用 taishan 存储这样一套接口进行快速 snapshot 切换,并可以指定对应的 snapshot 并进行加载,加载的速度非常快,基本是秒级左右。
3.4 缓存架构
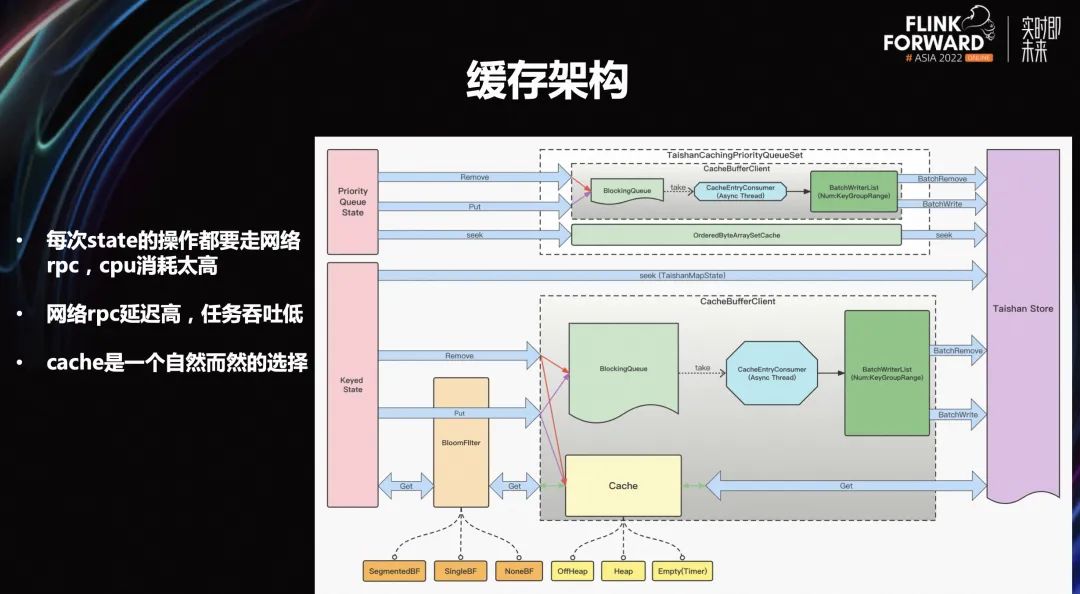
在上文介绍的基础上可以观察到,开发完之后实际上整个功能来说是完全够用的,但也发现了一些比较严重的性能问题:
每次 state 操作都需要走网络 rpc, cpu 的消耗太高
网络 rpc 的延迟高,任务吞吐低
-
cache 是一个自然而然的选择
3.5 缓存难点

读缓存是比较难的。读缓存是把场景进行拆分来看:
key 比较少的场景效果明显,命中率极高,效果好,甚至达到几百上千倍的效果提升。
稀疏的 key 场景,大量读 null,缓存命中率低。这个场景是当下比较大的难点。
-
周期性业务导致缓存定期失效,读 null,命中率暴跌。周期性业务到周期末节点,就会触发一个缓存失效,一旦跨过这个节点,缓存里就会变成新的数据。如果正巧遇上读 null,命中率就会很低,甚至导致任务抖动。这也是比较大的难点。
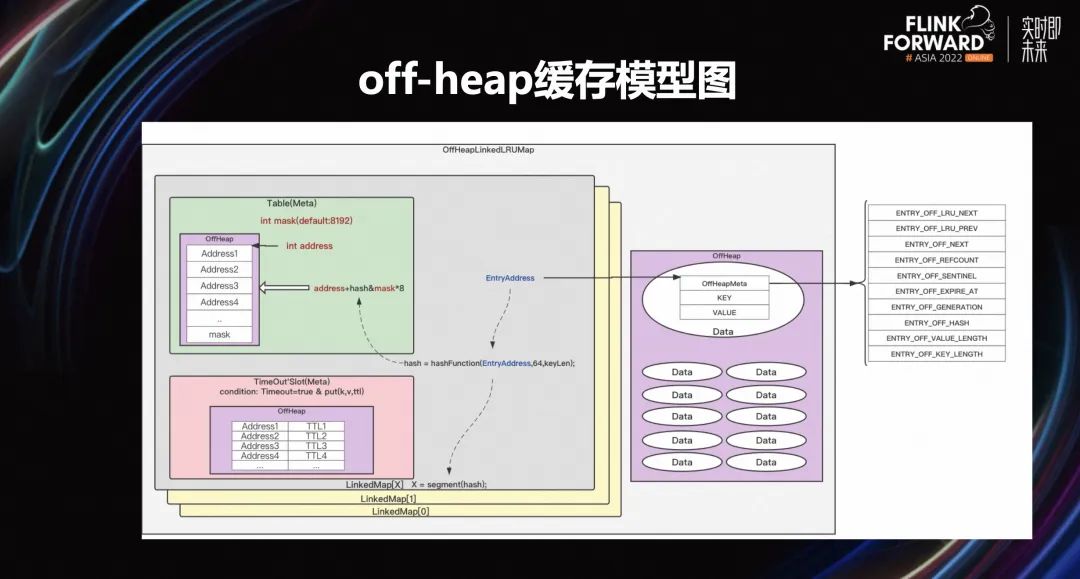
3.6 off-heap 缓存模型图
未来规划

8/26 活动预告
活动时间:8 月 26 日 13:00
活动地点:北京阿里中心·望京 A 座
线下报名地址:https://developer.aliyun.com/trainingcamp/4bb294cf64b04a2a8b3f8b153e188e9f
线上直播观看地址:https://gdcop.h5.xeknow.com/sl/1l4Sye

▼ 关注「Apache Flink」,获取更多技术干货 ▼
 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源