
HBase 剖析 | HBase 读链路解析
正文之前
在讲HBase的读路径时,我们先来看几个简单的类图。
InternalScanner是一个Interface主要提供了两个方法,next(List<Cell> result)方法——获取下一行的数据。而next(List<Cell> result, ScannerContext scannerContext)提供功能相同,只不过允许传入一个ScannerContext用以记录当前scan任务的上下文,判断是否可以提前结束、是否要去读下一列、是否要去读下一行等。并且发生在InternalScanner中的数据比较等操作,都是基于byte[](而不用先转化为RowResults),更加接近于数据在物理上的存储形式,可以获得更高的性能。

KeyValueScanner也是一个接口,换成CellScanner可能更容易理解。对,它主要提供在一个“可读取的对象上”,获取cell的能力。这里使用“可读取的对象”这个词,主要是因为它可以是一个物理概念上的HFile,但也可以是逻辑意义上有迭代读取能力的scanner。
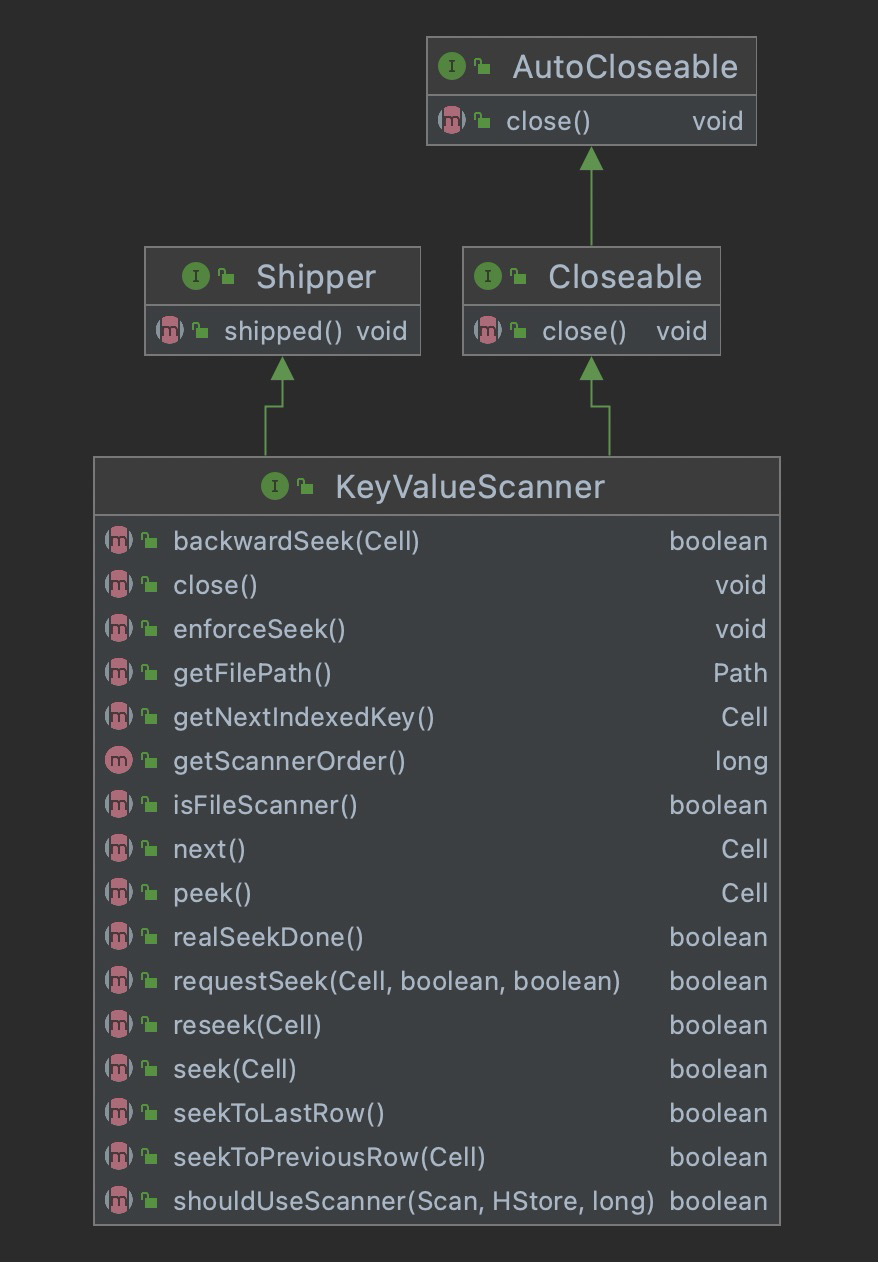
最后一个关键的类就是KeyValueHeap,该类实现了KeyValueScanner与InternalScanner接口,具备了获取cell及获取行的能力。KeyValueHeap中还有一个关键的属性,为heap,它是一个PriorityQueue<KeyValueScanner>对象,comparator = CellComparatorImp(即按照key的格式:rowkey:family:qualifier:timestamp)。即KeyValueHeap允许传入多个KeyValueScanner,通过PriorityQueue的形式将这些scanner管理起来,向上提供获取cell及获取行数据的能力!
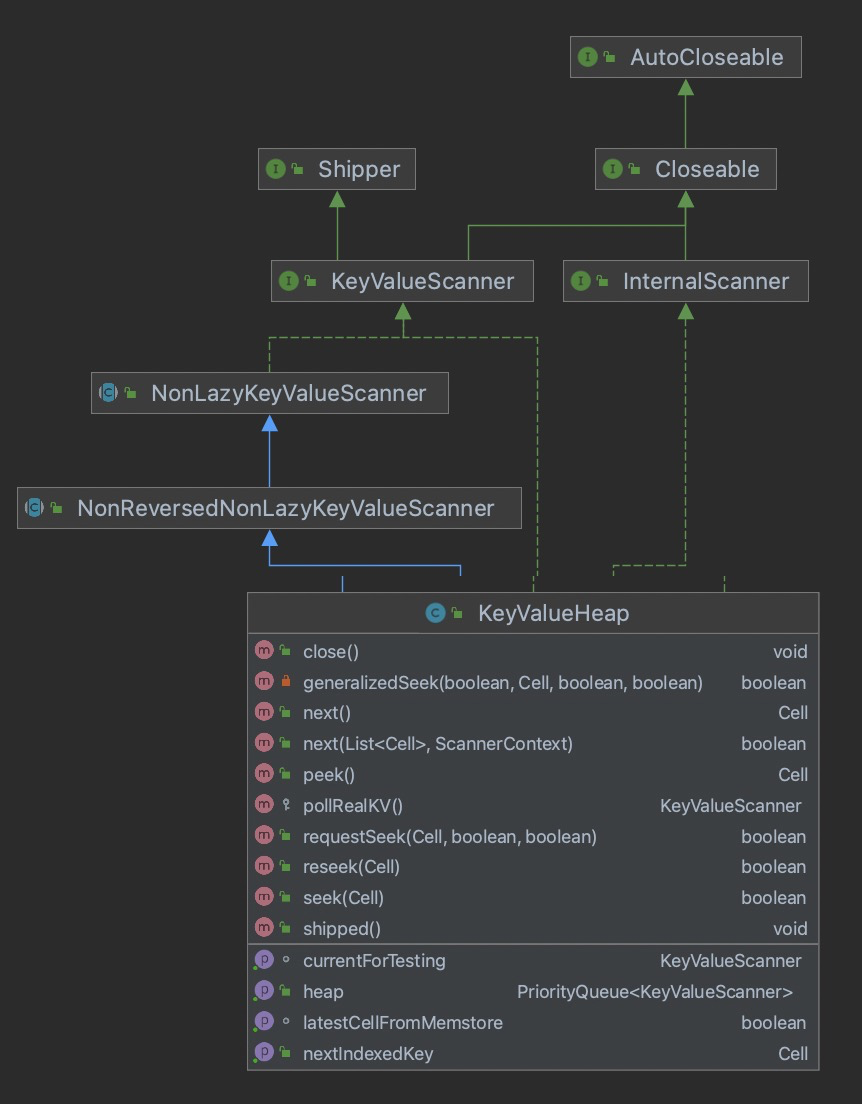
有了InternalScanner,KeyValueScanner和KeyValueHeap其实已经可以做很多事情了。
我们知道,HBase的查询抽象地来看的话,是表现为下面这个流程的:
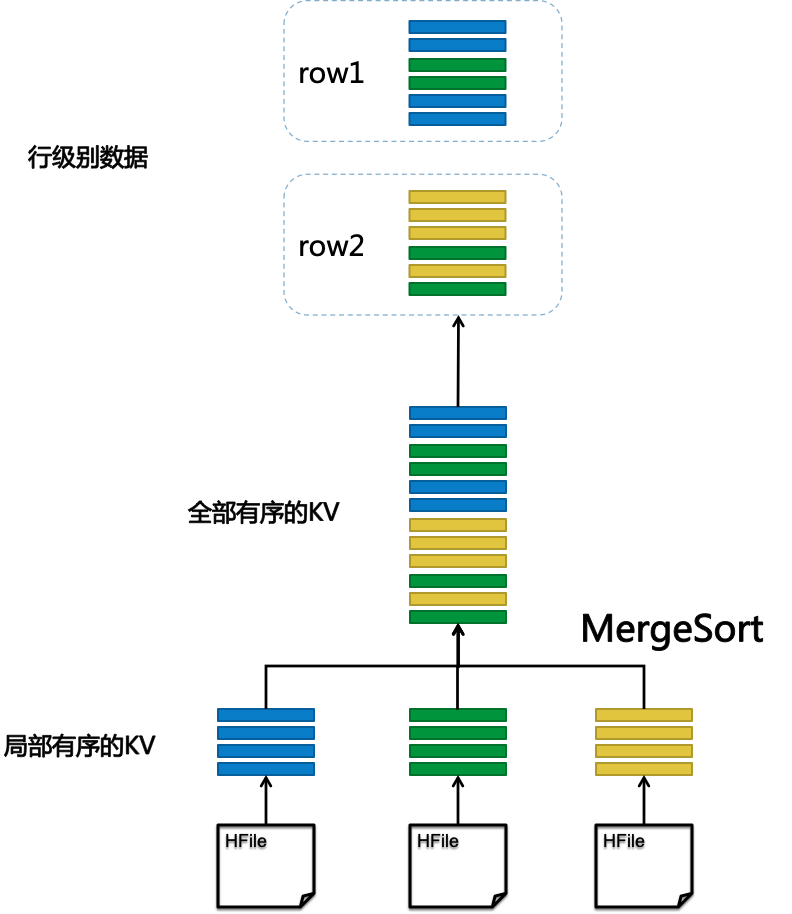
即从不同的HFile中进行数据读取,在内存中进行一个MergeSort,拼接成一行数据向上返回。
你们看KeyValueScanner、InternalScanner是不是就像其负责中HFile的读取Scanner,而KeyValueHeap负责的其实就是图中的MergeSort的任务。KeyValueHeap控制着下层KeyValueScanner、InternalScanner的数据读取,KeyValueScanner、InternalScanner是真正读取数据的Scanner。
好,大体的流程思路已经讲清楚了。其实HBase的读取流程远比这复杂,涉及的对象也更多,但有了上面的基础相信可以理解得很容易,接下来我们来仔细看看HBase的读取流程。
正文
我们从RegionScanner出发,仔细看看HBase的读取流程。
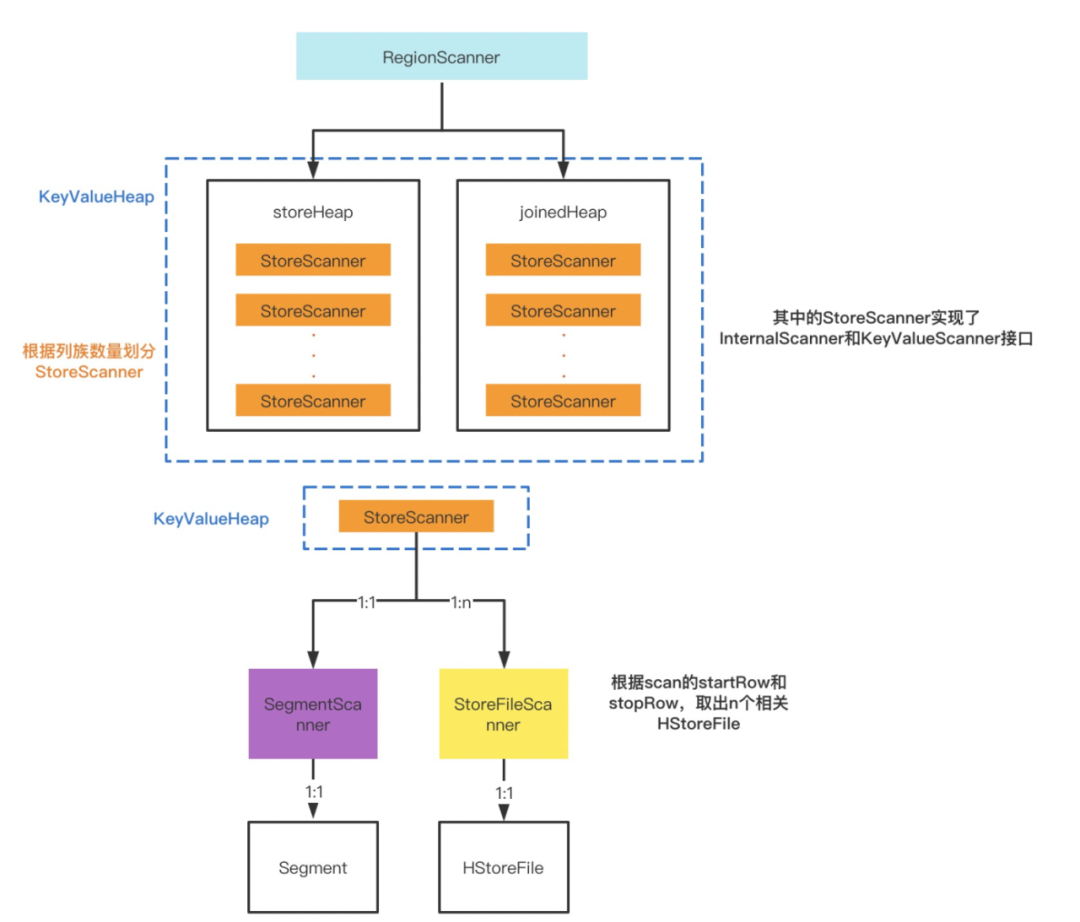
上图中的RegionScanner主要靠成员变量storeHeap,joinedHeap(KeyValueHeap)进行数据读取迭代。而StoreScanner也不是一个单纯的Scanner,而是扮演了跟RegionScanner类似的角色,它也拥有自己的heap,以此来进行数据的读取。跟【正文之前】说的一样,KeyValueHeap控制着下层KeyValueScanner、InternalScanner的数据读取,KeyValueScanner、InternalScanner是真正读取数据的Scanner。只不过RegionScanner中多嵌了一层StoreScanner(KeyValueHeap),变成了这样的调用链路:KeyValueHeap(RegionScanner)->KeyValueHeap(StoreScanner)
->KeyValueScanner,InternalScanner(StoreFileScanner及SegmentScanner)。
为什么HBase要这样封装?
其实是为了抽象不同的功能。
简单来说,
1)StoreScanner是为了联合StoreFileScanner与SegmentScanner向上提供整行的数据迭代读取功能。
2)而RegionScanner,一方面是对获取的数据做了过滤功能,另一方面是为了将全部数据分为两段获取形式(storeHeap和joinedHeap),用以优化性能。因为从storeHeap中获取的数据如果会被过滤,那么就没有必要再获取joinedHeap中的数据了。
详细内容我们见下文。
HBase的读取任务开始之前需要构建初始的Scanner体系,涉及RegionScanner与StoreScanner的对象初始化,我们详细来看:
1)RegionScanner对象的初始化:
1.建立RegionScanner对象,准备开始Scan任务涉及的所有Scanner的生成。
2.根据scan任务涉及的所有column family,在本region上分别会为其中的每个column family生成一个StoreScanner。如果开启了on-demand column family loading,那么会根据传入FilterList的isFamilyEssential方法进行判断,如果isFamilyEssential,那么会将该StoreScanner放入storeHeap中,否则放入joinedHeap中。
3.storeHeap和joinedHeap中存放StoreScanner的形式为PriorityQueue,优先级为CellComparatorImp。
2)StoreScanner对象的初始化
接下来我们介绍RegionScanner对象的初始化中,我们一笔带过的StoreScanner的生成过程:
1.根据scan.isReversed()控制StoreScanner中的Scanner的优先级顺序。
2.根据传入的scan信息,生成matcher内置对象,该对象在查询过程中会对StoreScanner读取的数据进行一个筛选。
3.根据scan信息startRow,stopRow在storeEngine中查询出涉及的HStoreFile,对这些HStoreFile分别建立StoreFileScanner,组成scannerList,并且以StoreFileComparators.SEQ_ID为优先级(maxSequenceId升序,FileSize降序,BulkTime升序,PathName升序)。
4.对scannerList根据timestamp range, row key range, bloomFilter做一个过滤。
5.scannerList中剩余的scanner根据startRow,stopRow将指针seek到正确的位置。
6.将scanners以PriorityQueue的形式组织,优先级同样为CellComparatorImp。
PS:StoreFileComparators.SEQ_ID —— Comparator.comparingLong(HStoreFile::getMaxSequenceId) .thenComparing(Comparator.comparingLong(new GetFileSize()).reversed()) .thenComparingLong(new GetBulkTime()).thenComparing(new GetPathName())
组建好需要Scanner体系之后,后续就是读取流程了。
读取流程如下图所示:
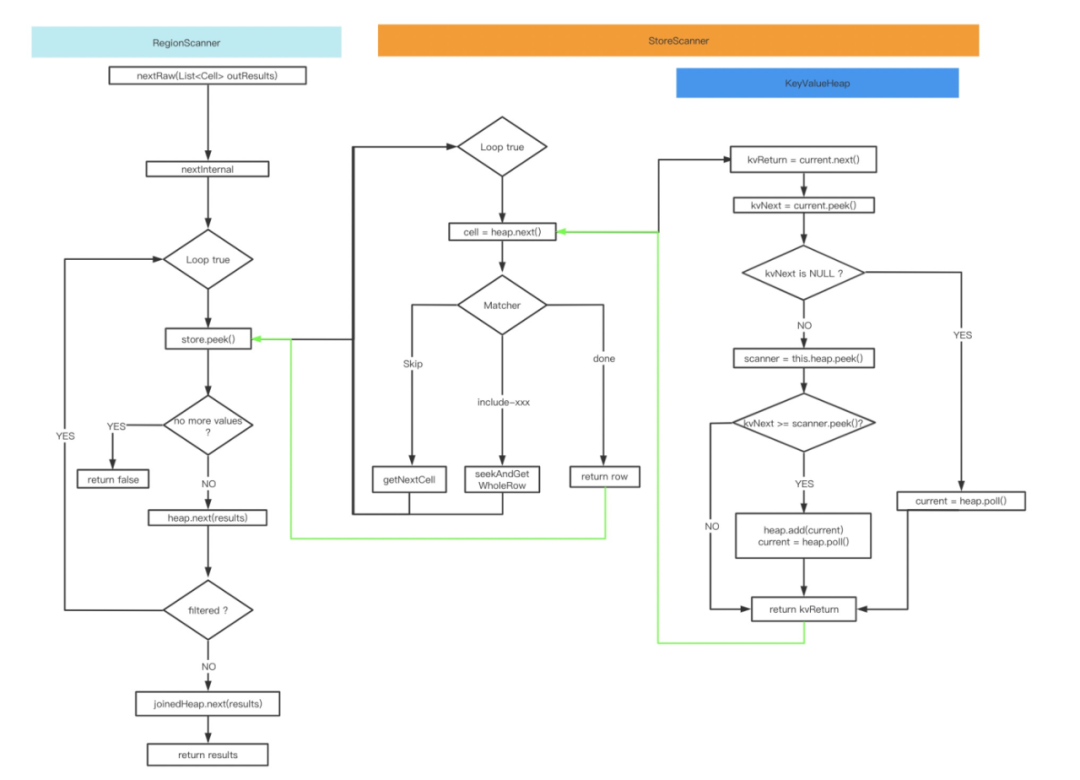
RegionScanner主要负责以下功能:
其包含storeHeap与joinedHeap都为KeyValueHeap的对象实例,heap底层是包含了多个StoreScanner组成的PriorityQueue,comparator = CellComparatorImp。向上提供符合条件的整行数据的迭代查询。
1.循环从storeHeap上获取cell数据,以此判断是否还存在待获取数据。如果没有,return false。如果有:
2.那么先从storeHeap上获取family essential相关的数据,使用filter进行过滤。如果被过滤,continue loop。如果没有:
3.那么从joinedHeap上获取剩余数据,返回。
StoreScanner主要负责以下功能:
StoreScanner虽然是实现了KeyValueScanner和InternalScanner的类,但主要靠其成员变量heap(KeyValueHeap)来完成必要的操作。heap由多个StoreFileScanner实例按照PriorityQueue组成,comparator = CellComparatorImp。
1.循环从heap中获取cell。
2.通过matcher匹配cell获得返回的MatchCode,不同MatchCode会触发不同的操作,见下表。
MatchCode | Operation |
INCLUDE | check fill results heap.next() continue Loop |
INCLUDE_AND_SEEK_NEXT_ROW | check fill results seekOrSkipToNextRow continue Loop |
INCLUDE_AND_SEEK_NEXT_COL | check fill results seekOrSkipToNextColumn continue Loop |
DONE | return results |
DONE_SCAN | close heap return |
SEEK_NEXT_ROW | if no data: return false; else: seekOrSkipToNextRow continue; |
SEEK_NEXT_COL | seekOrSkipToNextColumn continue; |
SKIP | heap.next() continue Loop |
SEEK_NEXT_USING_HINT | seekAsDirection or heap.next() |
3.不停循环,直到数据组成整行,向上返回。
StoreScanner中KeyValueHeap的next功能:
storeScanner中的heap.next()究竟做了什么?简单来说,做了以下两件事情:1)从current(当前的StoreFileScanner,不在heap中)获取cell返回。2)更新当前current,把current放回heap重新排序,再获取当前最优先的StoreFileScanner作为current。
具体做法如下:
1.从当前的StoreFileScanner current中获取下一个cell(kvReturn)。再获取kvReturn往后的第一个cell(kvNext)
2.判断kvNext是否为空。为空代表当前current读取完毕,需要从heap中获取下一个scanner记为current。不为空则
3.从当前heap中获取第一个scanner,与current 进行对比。判断它们谁通过peek()获得的cell key最小,如果scanner更小,那么把current放回heap。重新heap.poll()获得最新current。
4.返回kvReturn cell。
至此整个HBase的读路径分析结束,留待补充的点:
1.Matcher的实现逻辑分析。
2.BloomFilter的过滤分析。
3.StoreFileScanner以下直到HDFS之间的链路分析,中间涉及一个BlockCache。