
Golang程序性能分析(一)pprof和go-torch
共 10225字,需浏览 21分钟
·
2021-01-19 08:59
前言
最近计划用三篇文章讲述一下Golang应用性能分析,本文是第一篇,先来介绍Go语言自带的性能分析库pprof怎么使用,后面两篇会讲解怎么用pprof对Echo或者Gin框架开发的应用进行性能分析以及如何使用pprof对gRPC 服务进行性能分析。
有兴趣追更的同学欢迎微信关注「网管叨bi叨」
Golang是一个非常注重性能的语言,因此语言的内置库里就自带了性能分析库pprof。
性能分析和采集在计算机性能调试领域使用的术语是profile,或者有时候也会使用profiling代表性能分析这个行为。所以pprof名字里的prof来源于对单词profile的缩写,profile这个单词的原意是画像,那么针对程序性能的画像就是应用使用 CPU 和内存等等这些资源的情况。都是哪些函数在使用这些资源?每个函数使用的比例是多少?
在Go 语言中,主要关注的程序运行情况包括以下几种:
CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据 Memory Profile(Heap Profile):报告程序的内存使用情况 Block Profile:报告导致阻塞的同步原语的情况,可以用来分析和查找锁的性能瓶颈 Goroutine Profile:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
工具型应用的性能分析
如果你的应用是工具类应用,执行完任务就结束退出,可以使用 `runtime/pprof` [1]库。
比如要想进行 CPU Profiling,可以调用 pprof.StartCPUProfile() 方法,它会对当前应用程序进行CPU使用情况分析,并写入到提供的参数中(w io.Writer),要停止调用 StopCPUProfile() 即可。
去除错误处理只需要三行内容,一般把部分内容写在 main.go 文件中,应用程序启动之后就开始执行:
f, err := os.Create(*cpuprofile)
...
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
应用执行结束后,就会生成一个文件,保存了我们应用的 CPU使用情况数据。
想要获得内存的数据,直接使用 WriteHeapProfile 就行,不用 start 和 stop 这两个步骤了:
f, err := os.Create(*memprofile)
pprof.WriteHeapProfile(f)
f.Close()
我们的文章会把重点篇幅放在服务型应用的性能分析,所以关于工具型应用的性能分析就说这么多。
服务型应用性能分析
如果你的应用是一直运行的,比如 web 应用或者gRPC服务等,那么可以使用 net/http/pprof 库,它能够在应用提供 HTTP 服务时进行分析。
如果使用了默认的 http.DefaultServeMux(通常是代码直接使用 http.ListenAndServe("0.0.0.0:8000", nil)),只需要在代码中添加一行,匿名引用net/http/pprof:
import _ "net/http/pprof"
如果你使用自定义的 ServerMux复用器,则需要手动注册一些路由规则:
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/heap", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
注册完后访问http://localhost/debug/pprof端点,它会得到类似下面的页面内容:
Types of profiles available:
Count Profile
// 下面是一些可访问的/debug/pprof/目录下的路由
2 allocs
0 block
0 cmdline
36 goroutine
2 heap
0 mutex
0 profile
13 threadcreate
0 trace
full goroutine stack dump
Profile Descriptions:
// 下面是对上面那些路由页面里展示的性能分析数据的解释
allocs: A sampling of all past memory allocations
block: Stack traces that led to blocking on synchronization primitives
cmdline: The command line invocation of the current program
goroutine: Stack traces of all current goroutines
heap: A sampling of memory allocations of live objects. You can specify the gc GET parameter to run GC before taking the heap sample.
mutex: Stack traces of holders of contended mutexes
profile: CPU profile. You can specify the duration in the seconds GET parameter. After you get the profile file, use the go tool pprof command to investigate the profile.
threadcreate: Stack traces that led to the creation of new OS threads
trace: A trace of execution of the current program. You can specify the duration in the seconds GET parameter. After you get the trace file, use the go tool trace command to investigate the trace.
这个路径下几个需要重点关注的子页面有:
/debug/pprof/profile:访问这个链接会自动进行 CPU profiling,持续 30s,并生成一个文件供下载,可以通过带参数?=seconds=60进行60秒的数据采集/debug/pprof/heap:Memory Profiling 的路径,访问这个链接会得到一个内存 Profiling 结果的文件/debug/pprof/block:block Profiling 的路径/debug/pprof/goroutines:运行的 goroutines 列表,以及调用关系
直接访问这些页面产生的性能分析数据我们是分析不过来什么的,Go在1.11版本后在它自带的工具集go tool里内置了pprof工具来分析由pprof库生成的数据文件。
使用go tool pprof
通过上面的设置可以获取服务的性能数据后,接下来就可以使用go tool pprof工具对这些数据进行分析和保存了,一般都是使用pprof通过HTTP访问上面列的那些路由端点直接获取到数据后再进行分析,获取到数据后pprof会自动让终端进入交互模式。在交互模式里pprof为我们提供了不少分析各种指标的子命令,在交互模式下键入help后就会列出所有子命令。
NOTE pprof子命令的使用方法可以参考
pprof --help或者 pprof 文档[2]。
CPU性能分析
进行CPU性能分析直接用go tool pprof访问上面说的/debug/pprof/profile端点即可,等数据采集完会自动进入命令行交互模式。
➜ go tool pprof http://localhost/debug/pprof/profile
Fetching profile over HTTP from http://localhost/debug/pprof/profile
Saved profile in /Users/Kev/pprof/pprof.samples.cpu.005.pb.gz
Type: cpu
Time: Nov 15, 2020 at 3:32pm (CST)
Duration: 30.01s, Total samples = 0
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
默认采集时长是 30s,如果在 url 最后加上 ?seconds=60 参数可以调整采集数据的时间为 60s。
采集完成我们就进入了一个交互式命令行,可以对解析的结果进行查看和导出。可以通过 help 来查看支持的子命令有哪些。
NOTE: 如果
pprof用性能数据生成分析图的话、包括后面的go-torch火焰图都依赖软件graphvizMac 用户直接
brew install graphviz就能安装,其他系统官网下载页面也有提供安装包,请访问https://graphviz.org/download/
列出最耗时的地方
一个有用的命令是 topN,它列出最耗时间的地方:
(pprof) top10
130ms of 360ms total (36.11%)
Showing top 10 nodes out of 180 (cum >= 10ms)
flat flat% sum% cum cum%
20ms 5.56% 5.56% 100ms 27.78% encoding/json.(*decodeState).object
20ms 5.56% 11.11% 20ms 5.56% runtime.(*mspan).refillAllocCache
20ms 5.56% 16.67% 20ms 5.56% runtime.futex
10ms 2.78% 19.44% 10ms 2.78% encoding/json.(*decodeState).literalStore
10ms 2.78% 22.22% 10ms 2.78% encoding/json.(*decodeState).scanWhile
10ms 2.78% 25.00% 40ms 11.11% encoding/json.checkValid
10ms 2.78% 27.78% 10ms 2.78% encoding/json.simpleLetterEqualFold
10ms 2.78% 30.56% 10ms 2.78% encoding/json.stateBeginValue
10ms 2.78% 33.33% 10ms 2.78% encoding/json.stateEndValue
10ms 2.78% 36.11% 10ms 2.78% encoding/json.stateInString
每一行表示一个函数的信息。前两列表示函数在 CPU 上运行的时间以及百分比;第三列是当前所有函数累加使用 CPU 的比例;第四列和第五列代表这个函数以及子函数运行所占用的时间和比例(也被称为累加值 cumulative),应该大于等于前两列的值;最后一列就是函数的名字。如果应用程序有性能问题,上面这些信息应该能告诉我们时间都花费在哪些函数的执行上。
生成函数调用图
pprof 不仅能打印出最耗时的地方(top),还能列出函数代码以及对应的取样数据(list)、汇编代码以及对应的取样数据(disasm),而且能以各种样式进行输出,比如 svg、gif、png等等。
其中一个非常便利的是 web 命令,在交互模式下输入 web,就能自动生成一个 svg 文件,并跳转到浏览器打开,生成了一个函数调用图(这个功能需要安装graphviz后才能使用)。
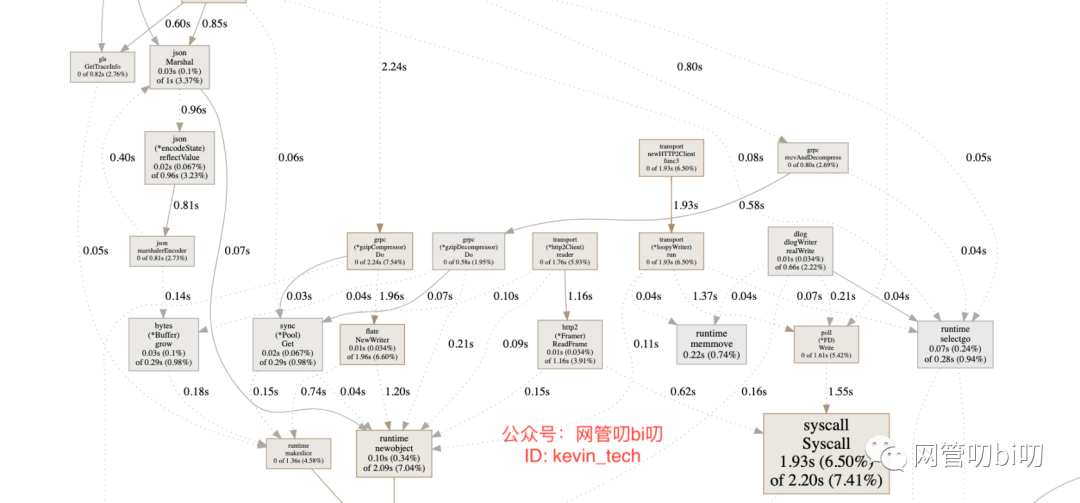
图中每个方框对应应用程序运行的一个函数,方框越大代表函数执行的时间越久(函数执行时间会包含它调用的子函数的执行时间,但并不是正比的关系);方框之间的箭头代表着调用关系,箭头上的数字代表被调用函数的执行时间。
这里还要提两个比较有用的方法,如果应用比较复杂,生成的调用图特别大,看起来很乱,有两个办法可以优化:
使用 web funcName的方式,只打印和某个函数相关的内容运行 go tool pprof命令时加上--nodefration参数,可以忽略内存使用较少的函数,比如--nodefration=0.05表示如果调用的子函数使用的 CPU、memory 不超过 5%,就忽略它,不要显示在图片中。
分析函数性能
想更细致分析,就要精确到代码级别了,看看每行代码的耗时,直接定位到出现性能问题的那行代码。pprof 也能做到,list 命令后面跟着一个正则表达式,就能查看匹配函数的代码以及每行代码的耗时:
(pprof) list podFitsOnNode
Total: 120ms
ROUTINE ======================== k8s.io/kubernetes/plugin/pkg/scheduler.podFitsOnNode in /home/cizixs/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/plugin/pkg/scheduler/generic_scheduler.go
0 20ms (flat, cum) 16.67% of Total
. . 230:
. . 231:// Checks whether node with a given name and NodeInfo satisfies all predicateFuncs.
. . 232:func podFitsOnNode(pod *api.Pod, meta interface{}, info *schedulercache.NodeInfo, predicateFuncs map[string]algorithm.FitPredicate) (bool, []algorithm.PredicateFailureReason, error) {
. . 233: var failedPredicates []algorithm.PredicateFailureReason
. . 234: for _, predicate := range predicateFuncs {
. 20ms 235: fit, reasons, err := predicate(pod, meta, info)
. . 236: if err != nil {
. . 237: err := fmt.Errorf("SchedulerPredicates failed due to %v, which is unexpected.", err)
. . 238: return false, []algorithm.PredicateFailureReason{}, err
. . 239: }
. . 240: if !fit {
内存性能分析
要想获得内存使用 Profiling 信息,只需要把数据源修改一下就行(对于 HTTP 方式来说就是修改 url 的地址,从 /debug/pprof/profile 改成 /debug/pprof/heap):
➜ go tool pprof http://localhost/debug/pprof/heap
Fetching profile from http://localhost/debug/pprof/heap
Saved profile in
......
(pprof)
和 CPU Profiling 使用一样,使用 top N 可以打印出使用内存最多的函数列表:
(pprof) top
11712.11kB of 14785.10kB total (79.22%)
Dropped 580 nodes (cum <= 73.92kB)
Showing top 10 nodes out of 146 (cum >= 512.31kB)
flat flat% sum% cum cum%
2072.09kB 14.01% 14.01% 2072.09kB 14.01% k8s.io/kubernetes/vendor/github.com/beorn7/perks/quantile.NewTargeted
2049.25kB 13.86% 27.87% 2049.25kB 13.86% k8s.io/kubernetes/pkg/api/v1.(*ResourceRequirements).Unmarshal
1572.28kB 10.63% 38.51% 1572.28kB 10.63% k8s.io/kubernetes/vendor/github.com/beorn7/perks/quantile.(*stream).merge
1571.34kB 10.63% 49.14% 1571.34kB 10.63% regexp.(*bitState).reset
1184.27kB 8.01% 57.15% 1184.27kB 8.01% bytes.makeSlice
1024.16kB 6.93% 64.07% 1024.16kB 6.93% k8s.io/kubernetes/pkg/api/v1.(*ObjectMeta).Unmarshal
613.99kB 4.15% 68.23% 2150.63kB 14.55% k8s.io/kubernetes/pkg/api/v1.(*PersistentVolumeClaimList).Unmarshal
591.75kB 4.00% 72.23% 1103.79kB 7.47% reflect.Value.call
520.67kB 3.52% 75.75% 520.67kB 3.52% k8s.io/kubernetes/vendor/github.com/gogo/protobuf/proto.RegisterType
512.31kB 3.47% 79.22% 512.31kB 3.47% k8s.io/kubernetes/pkg/api/v1.(*PersistentVolumeClaimStatus).Unmarshal
每一列的含义也是类似的,只不过从 CPU 使用时长变成了内存使用大小,就不多解释了。
类似的,web 命令也能生成 svg 图片在浏览器中打开,从中可以看到函数调用关系,以及每个函数的内存使用多少。
需要注意的是,默认情况下,统计的是内存使用大小,如果执行命令的时候加上 --inuse_objects 可以查看每个函数分配的对象数;--alloc-space 查看分配的内存空间大小。
go-torch 和火焰图
火焰图(Flame Graph)是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似火焰而得名。上面的 profiling结果也转换成火焰图,这里我们要介绍一个工具:go-torch[3]。这是 uber 开源的一个工具,可以直接读取 pprof的 profiling 数据,并生成一个火焰图的 svg 文件。
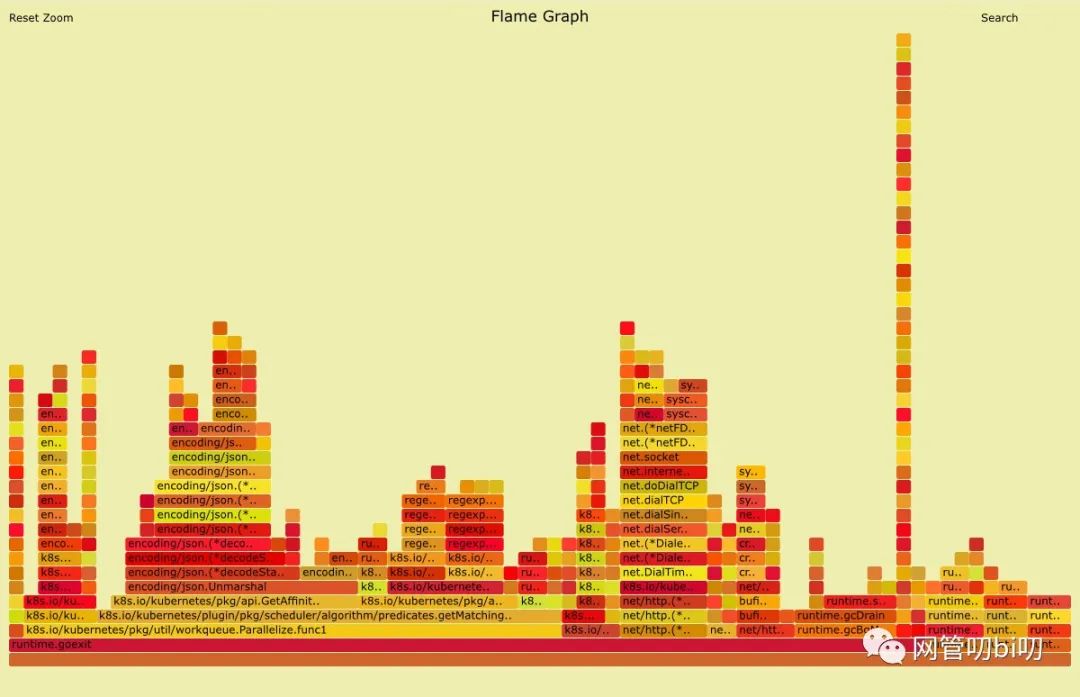
火焰图 svg 文件可以通过浏览器打开,它对于调用图的优点是:可以通过点击每个方块来分析它上面的内容。
火焰图的调用顺序从下到上,每个方块代表一个函数,它上面一层表示这个函数会调用哪些函数,方块的大小代表了占用 CPU 使用的长短。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
go-torch 工具的使用非常简单,没有任何参数的话,它会尝试从 http://localhost/debug/pprof/profile 获取 profiling 数据。它有三个常用的参数可以调整:
-u --url:要访问的 URL,这里只是主机和端口部分-s --suffix:pprof profile 的路径,默认为/debug/pprof/profile--seconds:要执行 profiling 的时间长度,默认为 30s
要生成火焰图,需要事先安装 FlameGraph[4]工具,这个工具的安装很简单,只要把对应的可执行文件放到 $PATH 目录下就行。
总结
今天的文章把Go语言的性能分析库pprof的安装和使用方法大体流程走了一遍,重点讲解了一下最常用的几个性能分析命令以及如何用pprof采集的profile数据找出程序里最耗费性能的部分。相信有了pprof的帮助在遇到需要优化程序性能的时候我们能有更多的参照指标从而有的放矢地对程序性能进行优化改进。
在使用pprof采集数据的时候一定要注意下面两点:
只有在有访问量的时候才能采集到这些性能指标数据。我是在公司的压测环境对接口压测时用 pprof拿到的数据,如果你是在本地运行程序的话最好用Postman或者Jmeter这些工具做个简单的并发访问。除非有健全的安全策略,否则最好只在测试和压测环境加上 pprof使用的那些路由,不要在生产环境上应用。
这篇文章就说这么多,后面的文章会介绍怎么在Echo和Gin框架下使用pprof,以及如何用pprof分析gRPC服务的性能。求关注、求点赞、求转发!我是网管,会在这里每周坚持输出原创,我们下期再见吧。
引用链接
runtime/pprof : https://golang.org/pkg/runtime/pprof/
pprof 文档: https://github.com/google/pprof/blob/master/doc/pprof.md
[3]go-torch: https://github.com/uber/go-torch
[4]FlameGraph: https://github.com/brendangregg/FlameGraph/tags
推荐阅读