
CVPR2022 | 多模态Transformer用于视频分割效果惊艳
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
参考视频对象分割(referring video object segmentation, RVOS)任务涉及到给定视频帧中文本参考对象实例的分割。相比之下,在得到更广泛研究的参考图像分割(referring image segmention, RIS)任务中,对象主要通过它们的外观进行参考。在RVOS中,对象可以通过它们正在执行或参与的动作进行参考。这使得 RVOS比RIS复杂得多,因为参考动作的文本表达通常无法从单个静态帧中推导出来。
为了解决这些挑战,现有 RVOS 方法往往依赖复杂的 pipeline。在被CVPR 2022接收的一篇论文《End-to-End Referring Video Object Segmentation with Multimodal Transformers》中,来自以色列理工学院的研究者提出了一种简单的、基于Transformer的端到端RVOS方法——Multimodal Tracking Transformer(MTTR )。

项目地址:https://github.com/mttr2021/MTTR
Huggingface Spaces Gradio demo:https://huggingface.co/spaces/akhaliq/MTTR
具体地,他们使用MTTR 将任务建模成序列预测问题。给定一个视频和文本查询,该模型在确定文本参考的对象之前为视频中所有对象生成预测序列。并且,他们的方法不需要与文本相关的归纳偏置模块,利用简单的交叉熵损失对齐视频和文本。因此,该方法相比以往简单的多。
研究者提出的pipeline示意图如下所示。首先使用标准的Transformer文本编码器从文本查询中提取语言特征,使用时空编码器从视频帧中提取视觉特征。接着将这些特征传递给多模态 Transformer 以输出几个对象预测序列。然后为了确定哪个预测序列能够最好地对应参考对象,研究者计算了每个序列的文本参考分数。为此,他们还提出了一种时序分割voting方案,使模型在做出决策时专注于最相关的部分。

研究者还展示了一系列不同对象之间的实际分割效果,如下穿白色T恤和蓝色短裤的冲浪者(淡黄色冲浪板)。


方法介绍
任务定义。RVOS 的输入为帧序列
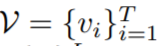 ,其中
,其中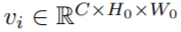 ;文本查询为
;文本查询为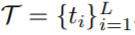 ,这里t_i是文本中的第i个单词;大小为
,这里t_i是文本中的第i个单词;大小为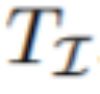 的感兴趣帧的子集为
的感兴趣帧的子集为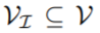 ,目标是在每一帧
,目标是在每一帧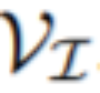 中分割对象
中分割对象 。
。特征提取。该研究首先使用深度时空编码器从序列 V 中的每一帧中提取特征。同时使用基于 Transformer 的文本编码器从文本查询 T 中提取语言特征。然后,将空间-时间和语言特征线性投影到共享维度 D。
实例预测。之后,感兴趣的帧特征被平化(flattened)并与文本嵌入分开连接,产生一组T_I多模态序列,这些序列被并行馈送到 Transformer。在 Transformer 的编码器层中,文本嵌入和每帧的视觉特征交换信息。然后,解码器层对每个输入帧提供N_q对象查询,查询与实体相关的多模态序列,并将其存储在对象查询中。该研究将这些查询(在图 1 和图 2 中由相同的唯一颜色和形状表示)称为属于同一实例序列的查询。这种设计允许自然跟踪视频中的每个对象实例。
输出生成。Transformer 输出的每个实例序列,将会生成一个对应的掩码序列。为了实现这一点,该研究使用了类似 FPN 的空间解码器和动态生成的条件卷积核。最后,该研究使用文本参考评分函数(text-reference score function),该函数基于掩码和文本关联,以确定哪个对象查询序列与 T 中描述的对象具有最强的关联,并将其分割序列作为模型的预测返回。
时间编码器。适合 RVOS 任务的时间编码器应该能够为视频中的每个实例提取视觉特征(例如,形状、大小、位置)和动作语义。相比之下,该研究使用端到端方法,不需要任何额外的掩码细化步骤,并使用单个主干就可完成。最近,研究者提出了 Video Swin Transformer [27] 作为 Swin Transformer 对视频领域的泛化。最初的 Swin 在设计时考虑了密集预测(例如分割), Video Swin 在动作识别基准上进行了大量测试。
据了解,该研究是第一个使用Video Swin (稍作修改)进行视频分割的。与 I3D 不同,Video Swin 仅包含一个时间下采样层,并且研究者可以轻松修改以输出每帧特征图。因此,Video Swin是处理完整的连续视频帧序列以进行分割的更好选择。
实例分割过程
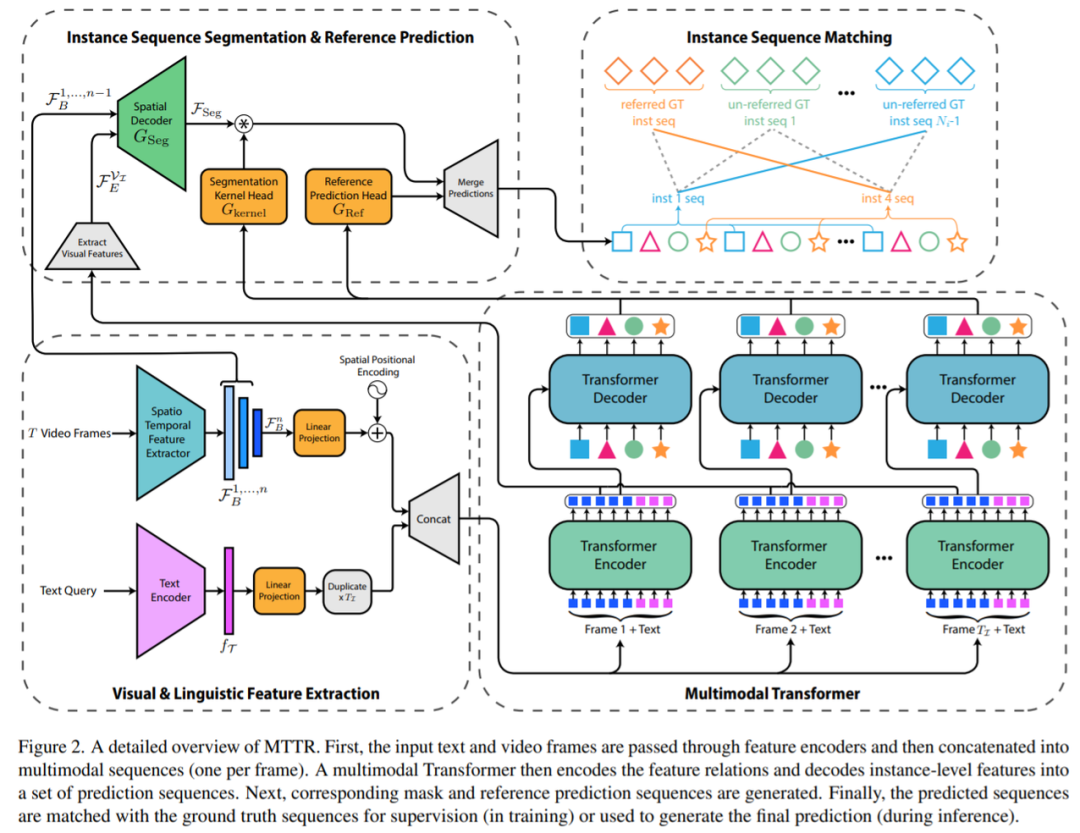
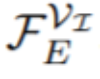 。然后,该研究采用时间编码器的前 n − 1 个块的输出
。然后,该研究采用时间编码器的前 n − 1 个块的输出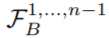 ,并使用类似 FPN 的 [21] 空间解码器 G_Seg 将它们与
,并使用类似 FPN 的 [21] 空间解码器 G_Seg 将它们与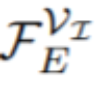 分层融合。这个过程产生了视频帧的语义丰富、高分辨率的特征图,表示为 F_Seg。
分层融合。这个过程产生了视频帧的语义丰富、高分辨率的特征图,表示为 F_Seg。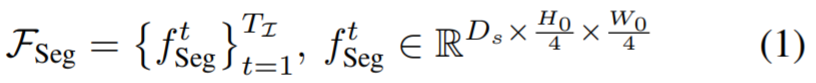
接下来,对于 Transformer 解码器输出的每个实例序列
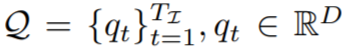 ,该研究使用两层感知器 G_kernel 生成相应的条件分割核序列。
,该研究使用两层感知器 G_kernel 生成相应的条件分割核序列。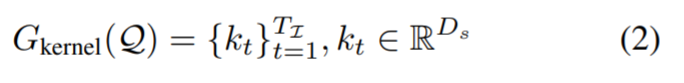
最后,通过将每个分割核与其对应的帧特征进行卷积,为
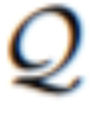 生成一系列分割掩码 M,然后进行双线性上采样操作以将掩码大小调整为真实分辨率
生成一系列分割掩码 M,然后进行双线性上采样操作以将掩码大小调整为真实分辨率
实验
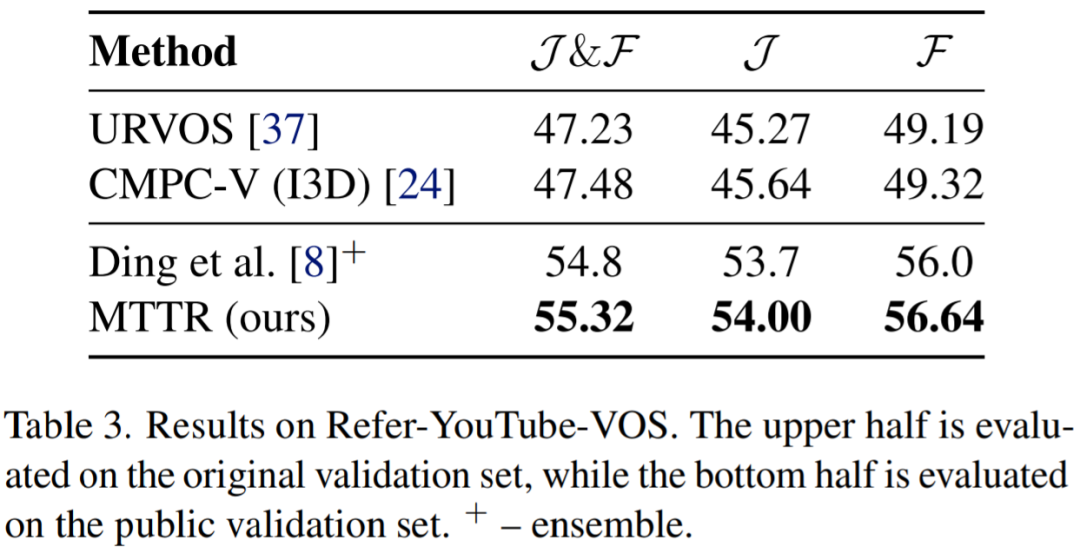
该研究在A2D-Sentences数据集上将MTTR与SOAT方法进行比较。结果如表 1所示,该方法在所有指标上都显着优于所有现有方法。
例如,该模型比当前SOTA模型提高了 4.3 mAP ,这证明了MTTR能够生成高质量的掩码。该研究还注意到,与当前SOTA技术相比,顶级配置(w = 10)的MTTR实现了 5.7 的 mAP 提高和 6.7% 的平均 IoU 和总体 IoU 的绝对改进。值得一提的是,这种配置能够在单个 RTX 3090 GPU 上每秒处理 76 帧的同时做到这一点。
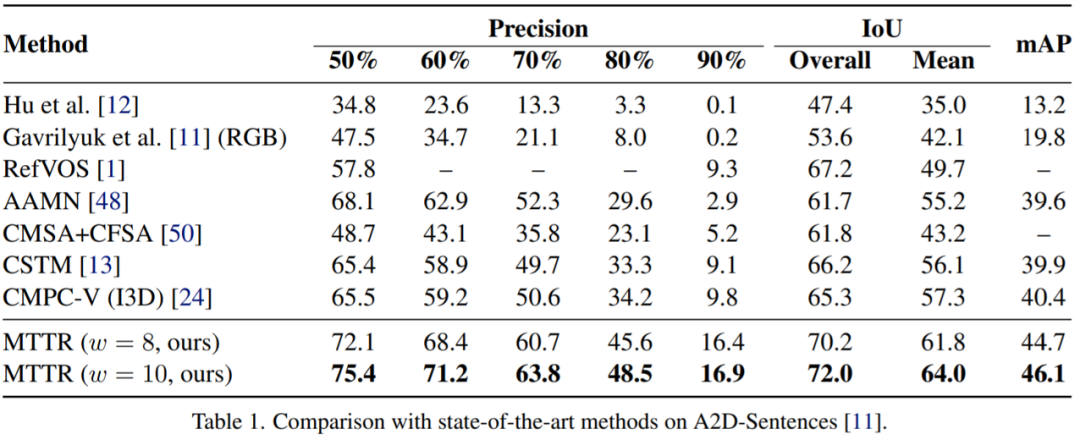
按照之前的方法 [11, 24],该研究通过在没有微调的 JHMDBSentences 上评估模型的泛化能力。该研究从每个视频中统一采样三帧,并在这些帧上评估模型。如表2所示,MTTR方法具有很好的泛化性并且优于所有现有方法。
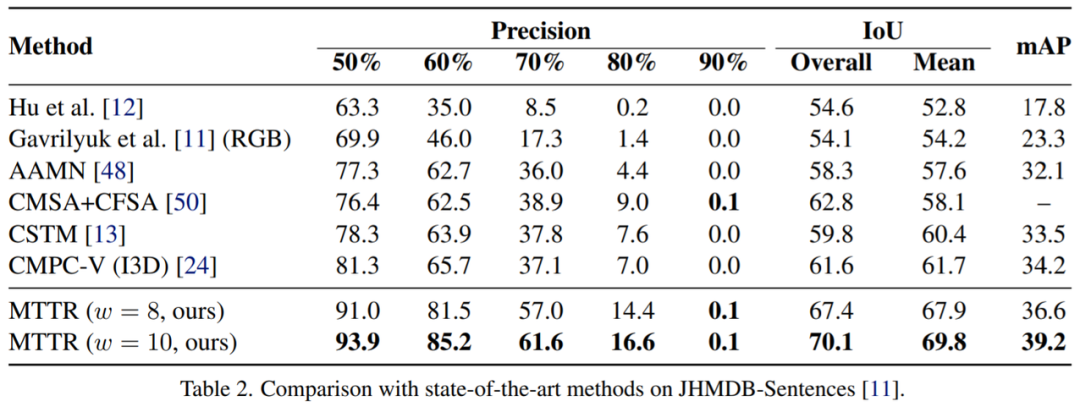
表3报告了在Refer-YouTube-VOS公共验证集上的结果。与现有方法[24,37]相比,这些方法是在完整数据集上进行训练和评估的,尽管该研究模型在较少的数据上进行训练,并专门在一个更具挑战性的子集上进行评估,但MTTR在所有指标上都表现出了卓越的性能。
如图 3 所示,MTTR 可以成功地跟踪和分割文本参考对象,即使在具有挑战性的情况下,它们被类似实例包围、被遮挡或在视频的广泛部分中完全超出相机的视野。

交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、NeRF、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文

评论