
终于有人把知识图谱讲明白了


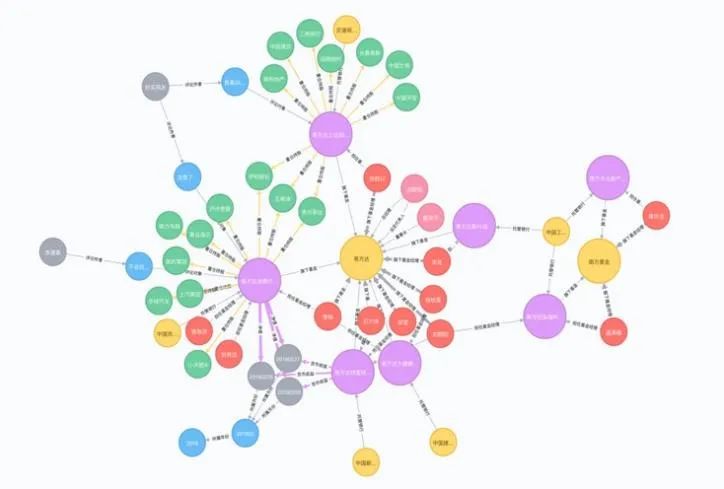




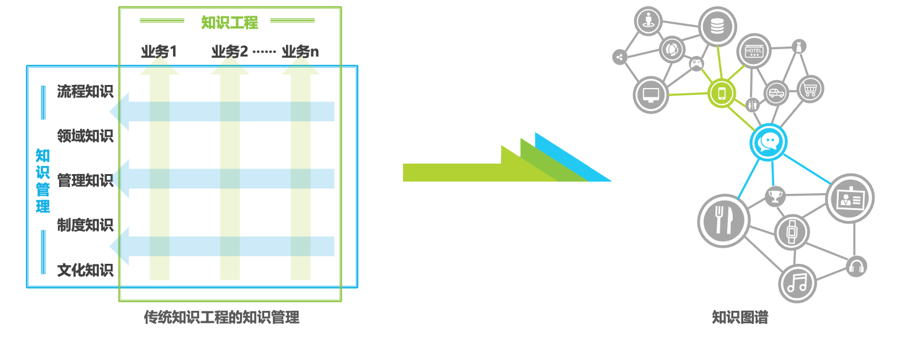
城市治理:知识图谱赋能城市智能公共管理系统,打造城市“数字大脑”
环保:构建生态环境知识库,形成统一环境数据标准
医疗健康:在就医导诊、辅助诊断、药企市场拓展等领域提供知识服务
教育知识 :教育知识图谱与机器学习算法结合实现智适应教育
智慧建筑:集合构建以BIM数据与规范为主的建筑工程行业知识图谱
通用企业管理:企业内部知识管理平台高效实现知识资源创造、沉淀和使用
通用制造业:对基础数据进行建模,在制造全流程实现多方面协调管控
智能风控与信用评估 :知识图谱与机器学习相结合,重塑金融领域智能风控过程
智能投资研究顾问 :通过自动抓取和产业链关系推理解决投研领域痛点
智能产品营销 :知识图谱构建客户多维画像,实现精准个性化推荐
明确业务和专家要求:确定收集数据的目标并定义想要回答的问题。
收集和分析相关数据:发现哪些数据集、分类法和其他信息(专有的、开放的或商业可用的)最适合实现领域、范围、来源、维护等方面的目标。
清理数据以确保数据质量:纠正任何数据质量问题,使数据最适合的任务。这包括删除无效或无意义的条目、调整数据字段以适应多个值、修复不一致等。
创建语义数据模型:彻底分析不同的数据模式,为协调数据做好准备。重用或设计本体、应用程序配置文件、RDF 形状或其他一些关于如何一起使用它们的机制。使用 RDF Schema 和 OWL 等标准形式化数据模型。
将数据与ETL或虚拟化集成:应用ETL工具将数据转换为RDF或使用数据虚拟化通过NoETL、OBDA、GraphQL Federation等技术访问它。生成语义元数据,使数据更容易更新、发现和重用。
通过协调、融合和对齐来协调数据:在具有重叠范围的数据集中匹配同一个实体的描述,处理它们的属性以合并信息并映射它们的不同分类法。
构建数据管理和搜索层:使用 RDF 数据模型完美地合并不同的图。对于本地存储的数据,GraphDB™ 可以通过推理、一致性检查和验证有效地强制执行数据模型的语义。它可以在集群中扩展并与 Elasticsearch 等搜索引擎同步,以匹配预期的使用和性能要求。
通过推理、分析和文本分析来扩充图表:丰富数据,从文本中提取新的实体和关系。应用推理和图形分析来发现新信息。现在图表包含的数据比其组成数据集的总和还多。它还具有更好的互连性,从而带来更多内容并实现更深入的分析。
最大化数据的可用性:开始通过不同的知识发现工具(例如强大的 SPARQL 查询、易于使用的 GraphQL 界面、语义搜索、分面搜索、数据可视化等)为原始问题提供答案。此外,确保数据是公平的(可查找、可访问、可互操作和可重用)。
使 KG 易于维护和发展:最后,在制作知识图谱并且人们开始使用它之后,通过设置维护程序来保持它的活力——它的发展方式和来自不同来源的更新将是消耗的同时保持高数据质量。


