
Java 应用最常见的3个问题排查思路
来源:https://ricstudio.top/archives/java-online-question-probe
本文总结了一些常见的线上应急现象和对应排查步骤和工具。分享的主要目的是想让对线上问题接触少的同学有个预先认知,免得在遇到实际问题时手忙脚乱。毕竟作者自己也是从手忙脚乱时走过来的。
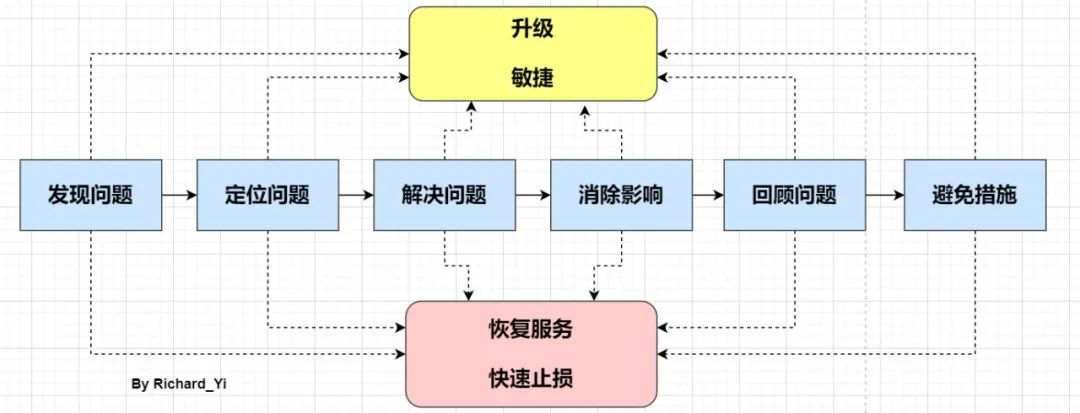
只不过这里先提示一下。在线上应急过程中要记住,只有一个总体目标:尽快恢复服务,消除影响。不管处于应急的哪个阶段,我们首先必须想到的是恢复问题,恢复问题不一定能够定位问题,也不一定有完美的解决方案,也许是通过经验判断,也许是预设开关等,但都可能让我们达到快速恢复的目的,然后保留部分现场,再去定位问题、解决问题和复盘。
在大多数情况下,我们都是先优先恢复服务,保留下当时的异常信息(内存dump、线程dump、gc log等等,在紧急情况下甚至可以不用保留,等到事后去复现),等到服务正常,再去复盘问题。
好,现在让我们进入正题吧。
常见现象1:CPU 利用率高/飙升
场景预设:
监控系统突然告警,提示服务器负载异常。
预先说明:
CPU飙升只是一种现象,其中具体的问题可能有很多种,这里只是借这个现象切入。
注:CPU使用率是衡量系统繁忙程度的重要指标。但是CPU使用率的安全阈值是相对的,取决于你的系统的IO密集型还是计算密集型。一般计算密集型应用CPU使用率偏高load偏低,IO密集型相反。
常见原因:
频繁 gc 死循环、线程阻塞、io wait...etc
模拟
这里为了演示,用一个最简单的死循环来模拟CPU飙升的场景,下面是模拟代码,
在一个最简单的SpringBoot Web 项目中增加CpuReaper这个类,
/**
* 模拟 cpu 飙升场景
* @author Richard_yyf
*/
@Component
public class CpuReaper {
@PostConstruct
public void cpuReaper() {
int num = 0;
long start = System.currentTimeMillis() / 1000;
while (true) {
num = num + 1;
if (num == Integer.MAX_VALUE) {
System.out.println("reset");
num = 0;
}
if ((System.currentTimeMillis() / 1000) - start > 1000) {
return;
}
}
}
}
打包成jar之后,在服务器上运行。java -jar cpu-reaper.jar &
第一步:定位出问题的线程
方法 a: 传统的方法
top定位CPU 最高的进程执行
top命令,查看所有进程占系统CPU的排序,定位是哪个进程搞的鬼。在本例中就是咱们的java进程。PID那一列就是进程号。(对指示符含义不清楚的见【附录】)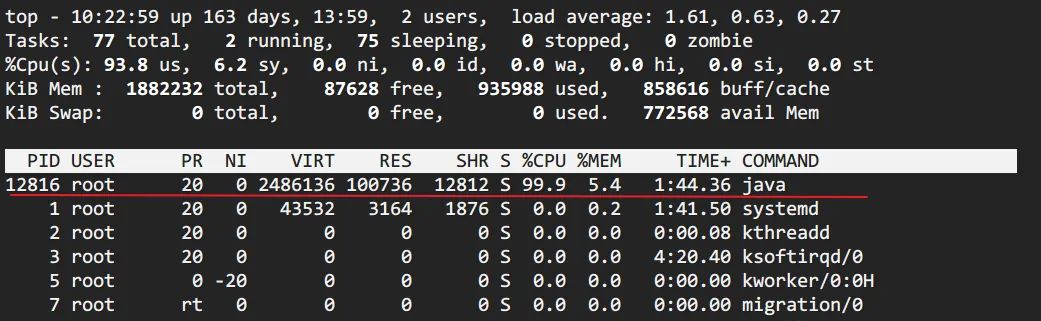
top -Hp pid定位使用 CPU 最高的线程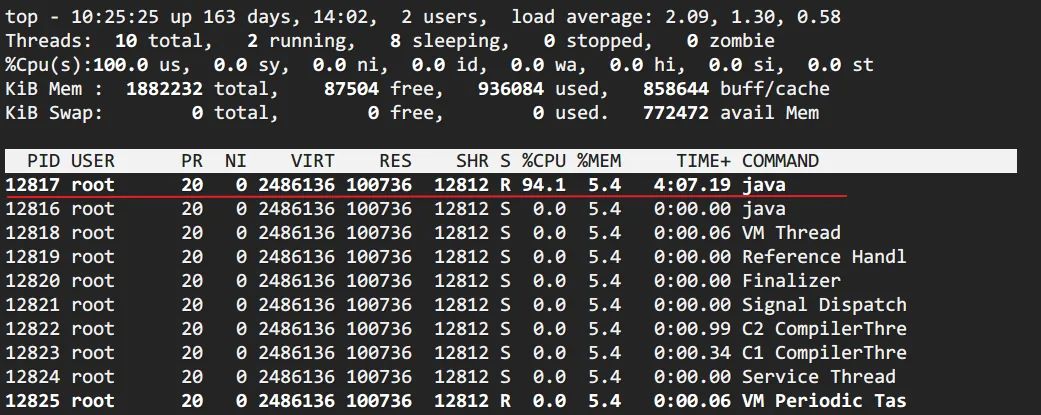
printf '0x%x' tid线程 id 转化 16 进制
> printf '0x%x' 12817> 0x3211
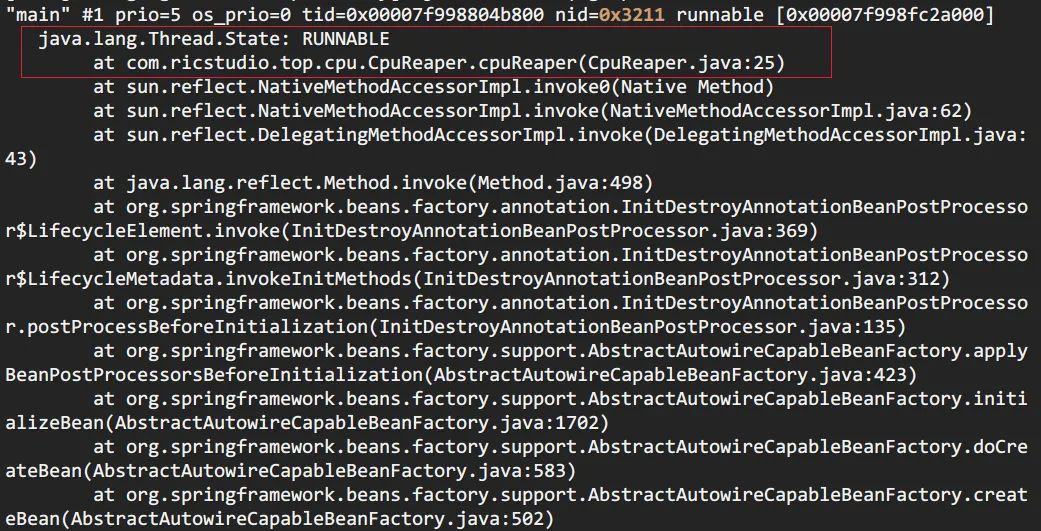
jstack pid | grep tid找到线程堆栈
> jstack 12816 | grep 0x3211 -A 30
方法 b: show-busy-java-threads
这个脚本来自于github上一个开源项目,项目提供了很多有用的脚本,show-busy-java-threads就是其中的一个。使用这个脚本,可以直接简化方法A中的繁琐步骤。如下,
> wget --no-check-certificate https://raw.github.com/oldratlee/useful-scripts/release-2.x/bin/show-busy-java-threads
> chmod +x show-busy-java-threads
> ./show-busy-java-threads
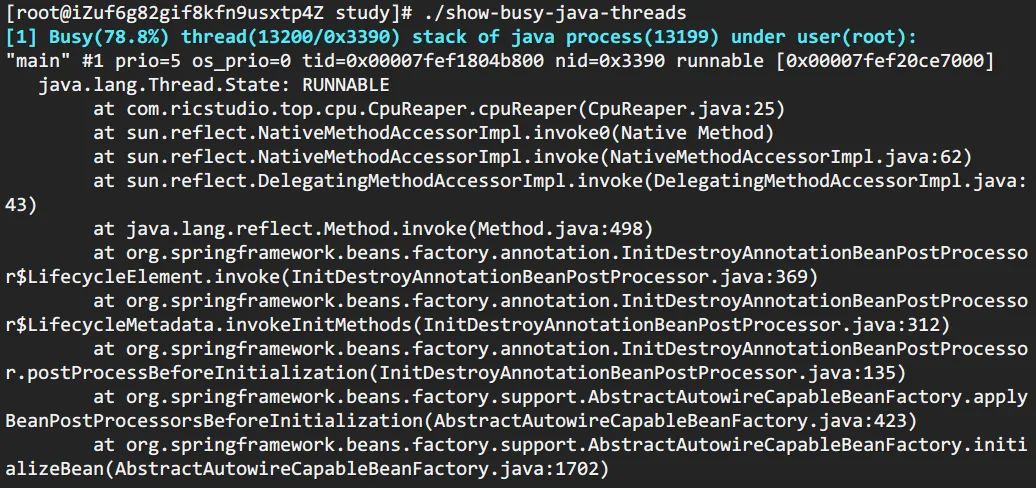
show-busy-java-threads
# 从所有运行的Java进程中找出最消耗CPU的线程(缺省5个),打印出其线程栈
# 缺省会自动从所有的Java进程中找出最消耗CPU的线程,这样用更方便
# 当然你可以手动指定要分析的Java进程Id,以保证只会显示你关心的那个Java进程的信息
show-busy-java-threads -p <指定的Java进程Id>
show-busy-java-threads -c <要显示的线程栈数>
方法 c: arthas thread
阿里开源的arthas现在已经几乎包揽了我们线上排查问题的工作,提供了一个很完整的工具集。在这个场景中,也只需要一个thread -n命令即可。
> curl -O https://arthas.gitee.io/arthas-boot.jar # 下载
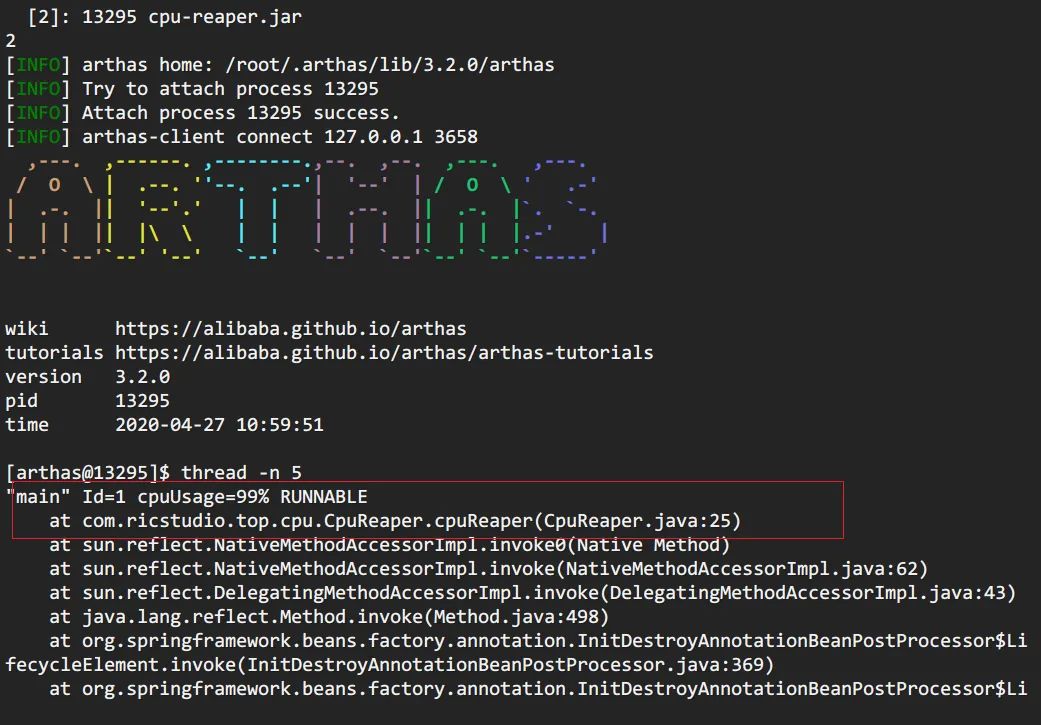
要注意的是,arthas的cpu占比,和前面两种cpu占比统计方式不同。前面两种针对的是Java进程启动开始到现在的cpu占比情况,arthas这种是一段采样间隔内,当前JVM里各个线程所占用的cpu时间占总cpu时间的百分比。
具体见官网:https://alibaba.github.io/arthas/thread.html
后续
通过第一步,找出有问题的代码之后,观察到线程栈之后。我们就要根据具体问题来具体分析。这里举几个例子。
情况一:发现使用CPU最高的都是GC 线程。
GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fd99001f800 nid=0x779 runnableGC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fd990021800 nid=0x77a runnable GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fd990023000 nid=0x77b runnable GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fd990025000 nid=0x77c runnabl
gc 排查的内容较多,所以我决定在后面单独列一节讲述。
情况二:发现使用CPU最高的是业务线程
io wait 比如此例中,就是因为磁盘空间不够导致的io阻塞 等待内核态锁,如 synchronized jstack -l pid | grep BLOCKED查看阻塞态线程堆栈dump 线程栈,分析线程持锁情况。 arthas提供了 thread -b,可以找出当前阻塞其他线程的线程。针对 synchronized 情况
常见现象2:频繁 GC
1. 回顾GC流程
在了解下面内容之前,请先花点时间回顾一下GC的整个流程。
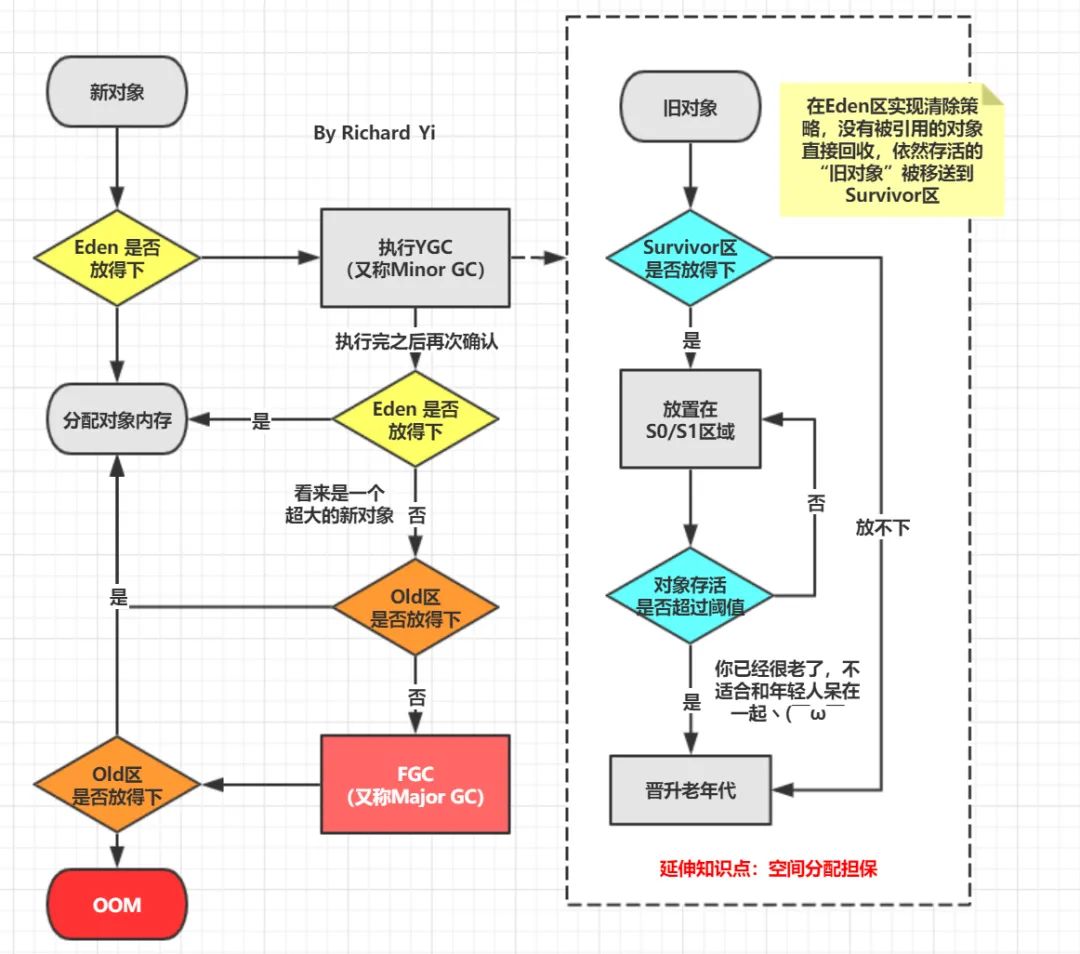
接前面的内容,这个情况下,我们自然而然想到去查看gc 的具体情况。
方法a : 查看gc 日志 方法b : jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一致统计方法c : 如果所在公司有对应用进行监控的组件当然更方便(比如Prometheus + Grafana)
这里对开启 gc log 进行补充说明。一个常常被讨论的问题(惯性思维)是在生产环境中GC日志是否应该开启。因为它所产生的开销通常都非常有限,因此我的答案是需要开启。但并不一定在启动JVM时就必须指定GC日志参数。
HotSpot JVM有一类特别的参数叫做可管理的参数。对于这些参数,可以在运行时修改他们的值。我们这里所讨论的所有参数以及以“PrintGC”开头的参数都是可管理的参数。这样在任何时候我们都可以开启或是关闭GC日志。比如我们可以使用JDK自带的jinfo工具来设置这些参数,或者是通过JMX客户端调用
HotSpotDiagnostic MXBean的setVMOption方法来设置这些参数。这里再次大赞arthas❤️,它提供的
vmoption命令可以直接查看,更新VM诊断相关的参数。
获取到gc日志之后,可以上传到GC easy帮助分析,得到可视化的图表分析结果。
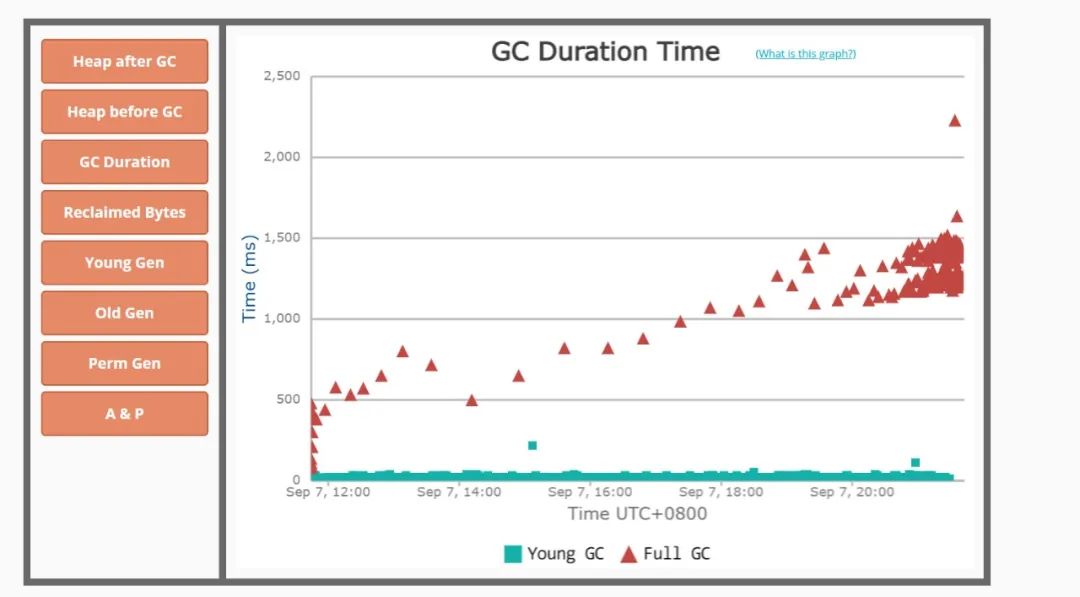
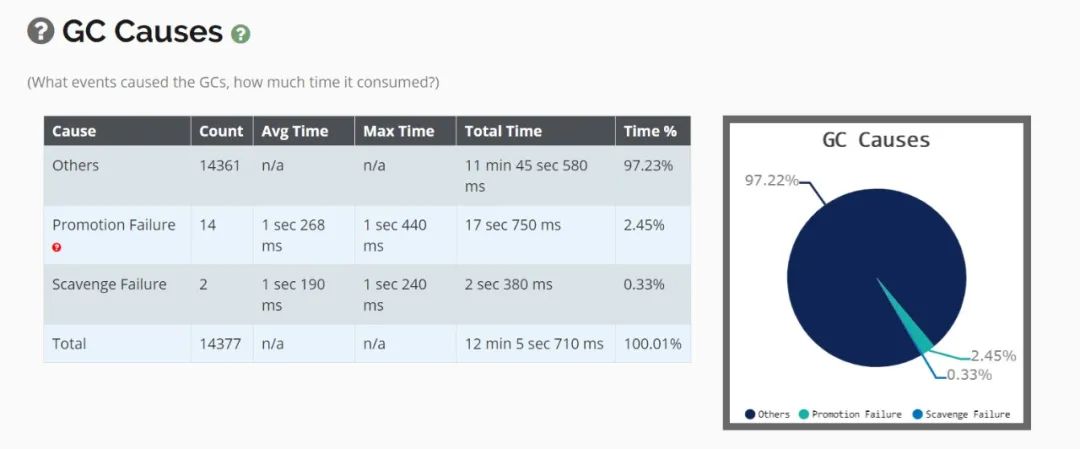
2. GC 原因及定位
prommotion failed
从S区晋升的对象在老年代也放不下导致 FullGC(fgc 回收无效则抛 OOM)。
可能原因:
survivor 区太小,对象过早进入老年代
查看 SurvivorRatio 参数
大对象分配,没有足够的内存
dump 堆,profiler/MAT 分析对象占用情况
old 区存在大量对象
dump 堆,profiler/MAT 分析对象占用情况
你也可以从full GC 的效果来推断问题,正常情况下,一次full GC应该会回收大量内存,所以 正常的堆内存曲线应该是呈锯齿形。如果你发现full gc 之后堆内存几乎没有下降,那么可以推断:**堆中有大量不能回收的对象且在不停膨胀,使堆的使用占比超过full GC的触发阈值,但又回收不掉,导致full GC一直执行。换句话来说,可能是内存泄露了。
一般来说,GC相关的异常推断都需要涉及到内存分析,使用jmap之类的工具dump出内存快照(或者 Arthas的heapdump)命令,然后使用MAT、JProfiler、JVisualVM等可视化内存分析工具。
至于内存分析之后的步骤,就需要小伙伴们根据具体问题具体分析啦。
常见现象3:线程池异常
场景预设:
业务监控突然告警,或者外部反馈提示大量请求执行失败。
异常说明:
Java 线程池以有界队列的线程池为例,当新任务提交时,如果运行的线程少于 corePoolSize,则创建新线程来处理请求。如果正在运行的线程数等于 corePoolSize 时,则新任务被添加到队列中,直到队列满。当队列满了后,会继续开辟新线程来处理任务,但不超过 maximumPoolSize。当任务队列满了并且已开辟了最大线程数,此时又来了新任务,ThreadPoolExecutor 会拒绝服务。
常见问题和原因
这种线程池异常,一般可以通过开发查看日志查出原因,有以下几种原因:
下游服务 响应时间(RT)过长
这种情况有可能是因为下游服务异常导致的,作为消费者我们要设置合适的超时时间和熔断降级机制。
另外针对这种情况,一般都要有对应的监控机制:比如日志监控、metrics监控告警等,不要等到目标用户感觉到异常,从外部反映进来问题才去看日志查。
数据库慢 sql 或者数据库死锁
查看日志中相关的关键词。
Java 代码死锁
jstack –l pid | grep -i –E 'BLOCKED | deadlock'
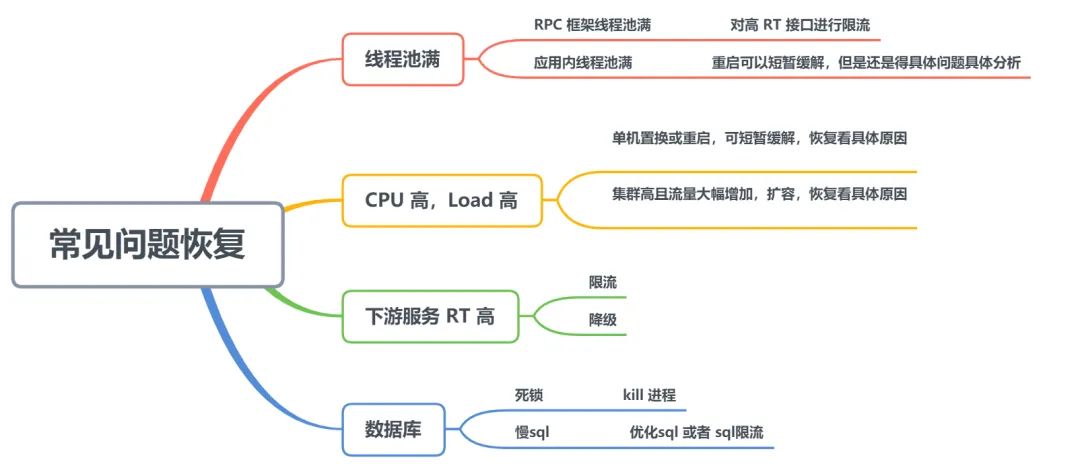
常见问题恢复
对于上文提到的一些问题,这里总结了一些恢复的方法。
- END -
精彩文章推荐:
点亮,服务器三年不宕机
