
DARTS:年轻人的第一个NAS模型

极市导读
Darts 是用于构建双数组 Double-Array的简单的 C++ Template Library。DARTS做到了大幅提升搜索算法的速度,本文作者结合论文详细解释了DARTS的相关基础概念及解释,并简述一些自己的关于假设以及发展方向的思考。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1. 薰风说
DARTS是第一个提出基于松弛连续化的,使用梯度下降进行搜索的神经网络架构搜索(neural architecture search, NAS)算法,将最早矿佬们(说的就是你Google)花成千上万个GPU-hour(即用一块卡跑一小时)的搜索算法降低到了一块卡四天就能跑完。这使得我们这种穷苦的实验室也有了研究NAS这个酷炫方法的可能,不愧是年轻人的第一个NAS模型哈哈哈。
DARTS最大的贡献在于使用了Softmax对本来离散的搜索空间进行了连续化,并用类似于元学习中MAMAL的梯度近似,使得只在一个超网络上就可以完成整个模型的搜索,无需反复训练多个模型。(当然,之后基于演化算法和强化学习的NAS方法也迅速地借鉴了超网络这一特性)。
而实际上,DART还有个更大的贡献就是开源了。不过源代码是基于Pytorch 0.3写的,和主流的1.x版本差别很大,所以需要一段时间进行重新复现。我现在写了1.4版本的分布式并行搜索代码,等后续可视化和保存模型都摸熟了会发实现的教程(在做了在做了)。
除此之外,DARTS虽然想法十分优雅,但我个人觉得其在假设上有不少值得推敲的地方。在略读了CVPR2020里有关NAS的20篇论文后,的确很多工作都是针对我觉得很“有趣”的假设做的233。之后,我也会持续更新CVPR2020中NAS有关的论文,尤其是基于梯度下降方法的。

2. 正文开始
2.1 概念介绍与符号声明
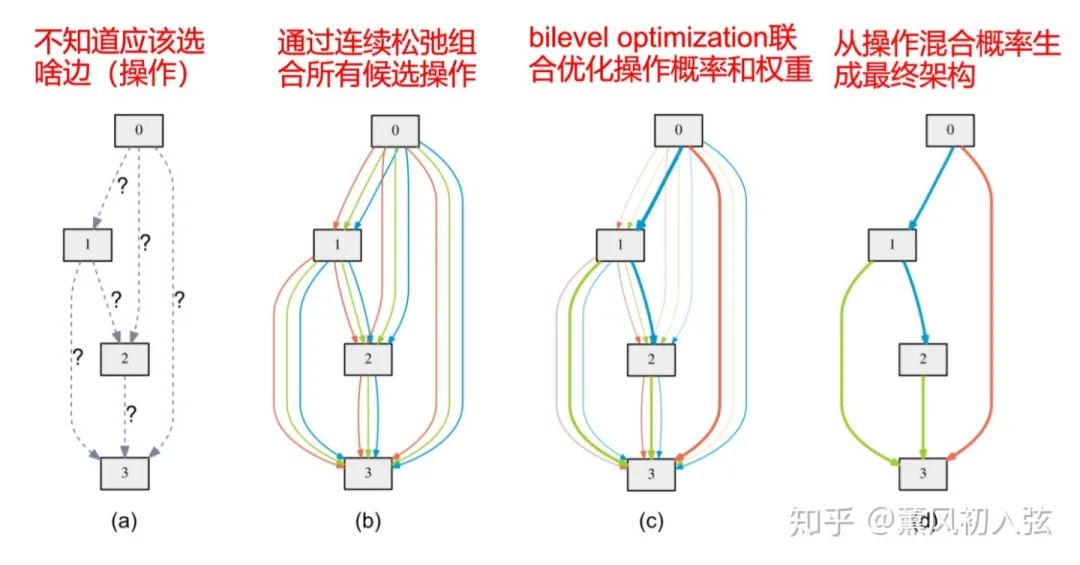
 个节点的有向无环图。在这个有向无环图中,有节点
个节点的有向无环图。在这个有向无环图中,有节点  和边
和边  ,其中
,其中节点 是第  个特征图
个特征图边 是从第 个特征图到第  个特征图之间的变换(如卷积、池化)
个特征图之间的变换(如卷积、池化)

 中选取出来的。
中选取出来的。2.2 连续松弛化
中寻找最好的操作,都是使用强化学习或者演化算法等启发式算法取某个操作,也就是说这种选择是非此即彼的离散操作。
 ,其含义为:第 个特征图到第 个特征图之间的操作 的权重。这也是我们之后需要搜索的架构参数。
,其含义为:第 个特征图到第 个特征图之间的操作 的权重。这也是我们之后需要搜索的架构参数。 ,那么就可以认为我们完全不需要这个操作。
,那么就可以认为我们完全不需要这个操作。 。
。 为网络架构(的编码)本身。
为网络架构(的编码)本身。2.3 两级最优化
 和
和  。网络中操作的的权重为
。网络中操作的的权重为  ,有 * 上标则说明其为最优的。因此,我们其实希望找到的是一个能在训练集训练好之后(最优权重
,有 * 上标则说明其为最优的。因此,我们其实希望找到的是一个能在训练集训练好之后(最优权重  ),在验证集上损失最小的架构(
),在验证集上损失最小的架构(  )。
)。 。而最优的权重本身必然是和架构对应的,架构变化,对应的权重也会跟着变化。 为上级变量,权重 为下级变量的两级最优化问题:
。而最优的权重本身必然是和架构对应的,架构变化,对应的权重也会跟着变化。 为上级变量,权重 为下级变量的两级最优化问题:
2.4 近似梯度
 是权重的学习率)
是权重的学习率)
 )时,
)时,  。
。 (训练集上对权重执行一次梯度下降)来近似最优权重
(训练集上对权重执行一次梯度下降)来近似最优权重  。
。在验证集损失上梯度下降更新架构参数 在训练集损失上梯度下降更新操作权重
李斌:【论文笔记】DARTS公式推导
 记为
记为  ,其中:
,其中:



 ):
):

 (复合函数对第一项的偏微分)
(复合函数对第一项的偏微分) (复合函数对第二项的偏微分)
(复合函数对第二项的偏微分)

 变成了一个常数,而不是之前一个变量为架构参数 的复合函数!
变成了一个常数,而不是之前一个变量为架构参数 的复合函数! (经验中取
(经验中取  )。
)。


 来替代
来替代  ,则有
,则有
 替代 , 再把
替代 , 再把  换成
换成  ,还有把
,还有把  换成 ,最后把
换成 ,最后把  换成
换成  ,就是有限差分近似的结果啦~
,就是有限差分近似的结果啦~ 降至
降至 
 。这种操作等价于假设当前的权重 就是最优权重 ,此时梯度将退化为一阶近似。
。这种操作等价于假设当前的权重 就是最优权重 ,此时梯度将退化为一阶近似。2.5 生成最优模型
3. 思考
3.1 "有趣"的假设
CNN可以由相同的Cell堆叠得到,RNN可以由相同的Cell递归连接得到 每个Cell有两个输入节点和一个输出节点组成,对于CNN来说输入节点是前两个Cell的输出(the cell outputs of the in the previous two layers) 每个Cell的输出实际上是对所有中间节点作reduction操作(比如concatenate)得到的 在验证集上效果最好的模型,在测试集上效果也最好 作者并没有证明这个梯度近似的收敛性,所以直接拿来用了hhh 作者将每个Cell的每个节点之间都取前2个最大权重的操作,(作者的理由是别人都是这么做的) 作者忽略了定义在搜索空间中的0操作(因为作者认为0操作在搜索过程中不会改变运算的结果) 在小模型搜到的Cell在大模型上也会很好用,因此无需重新搜索。 Reduction Cell 和 Normal Cell的搜索空间是一样的,且全都是深度可分离卷积,都有池化层。
3.2 作者给出的下一步方向
连续体系结构编码和派生离散模型之间存在差异,所以最好让引入类似有退火阈值的01编码。
在搜索工程中学到的共享参数是否可以用于设计一个性能可感知(performance aware)的架构派生机制。
推荐阅读
