
我在Github上发现了一个好东西!
好久不见,轩辕终于更新了。
作为一个天天都在CRUD的程序员,你有没有想过,数据库是如何工作的?
我猜,你曾经无数次的翻开讲数据库的书籍和文章,但总是看着看着就被劝退,太多的专业术语把人头都搞大了。

等等,看这画风,今天是要卖课的节奏啊!
NO!绝不卖课,请放心阅读。
一直以来,我都很想深入学习一下数据库。我这个人学东西,如果只知其然而不知其所以然是非常难受的,啥都想去了解下背后的原理,学编程语言是这样,学操作系统也是这样。数据库这个东西天天都在用,所以学习一下背后的原理也是非常实用和有必要的。
但无论是哪本书、哪个视频教程,一打开就被无数的专业术语淹没,太多概念淹没了数据库最本质最核心的东西。
所以今天,让我们从一个最最最简单的模型开始,揭开数据库神秘的一角。
对我们使用者而言,数据库就像是一个黑盒子,你可以往它里面写入数据,也可以从它里面读出数据。
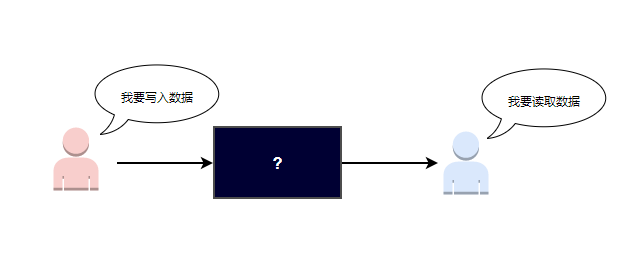
让我们暂时抛却SQL、网络连接、数据库等等概念,就来看这个最基本的需求:如果我们来实现一个可以对外提供读写数据的黑盒子,该怎么做?
假设我们的黑盒子很简单,里面只有一张表:
user_info
,用来存储用户信息。
表里面也很简单,只有三个字段,分别记录用户的ID、姓名和手机号。
user_id(uint32)
name(char[8])
phone(char[20])
我们可以用一个简单的结构体(或者一个class)来表示一条数据:
struct DataRecord{
uint32 user_id;
char name[8];
char phone[20];
};
user_id是一个uint32类型,占4个字节,name占8个字节,phone占20个字节,加起来一条数据总共占32个字节。
我们选择用一个文件来存储这些数据,存储非常简单,只需要一条一条的码在一起就行了,就像这样:
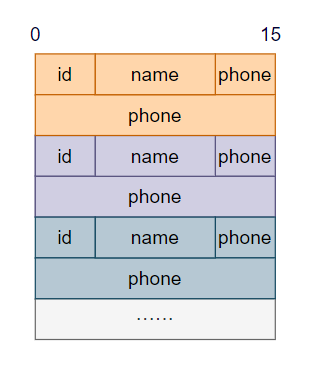
数据存储方式有了,接下来就是如何来读写了,我们来提供两个函数,分别来插入(insert)和查询(select)数据:
// 伪代码
void insert(Table* table, DataRecord record) {
fp = open(table->file_name);
fseek(fp, FILE_END);
write(fp, sizeof(DataRecord));
close(fp);
}
插入很简单,直接打开表对应的数据文件,然后把文件指针移动到文件尾部,接着追加数据,最后关闭文件,大功告成。这和把大象关进冰箱的步骤是一样一样的。
接下来是查询,我们提供一个可以通过id来查询用户的函数:
// 伪代码
DataRecord select(uint32 user_id) {
DataRecord result;
fp = open(table->file_name);
while (1) {
if (feof(fp))
break;
DataRecord record;
read(fp, &record, sizeof(DataRecord));
if (record.user_id == user_id) {
result = record;
break;
}
}
close(fp);
return result;
}
查询也很简单,我们打开文件,一条一条读取数据,然后比较用户id和给定的参数是否相同,直到找到符合条件的数据返回。
好了,以上,我们就实现了一个最最最基础的黑盒子:它里面有一张表,然后可以往里面写数据,从里面查数据。
现在来思考一下:
如果我们写了很多数据进去,比如几十万条,我们要查一个指定id的数据,要按照这样一条条比对,那不得等到猴年马月去了?
为什么要一条条比对呢?是因为我们的数据全都是一条一条码在一起的,完全没有顺序,所以要查询,只能这样一条条检查——全表扫描。
如果我们的数据是有顺序的呢?
假如我们插入数据的时候,是按照id从小到大排列着,这样我们就能用二分法快速找到指定id的数据了。
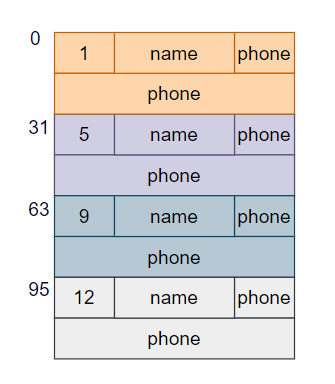
看上面这张图,假设我们要查找id为9的数据,我们可以读取第一条数据的id是1,就知道id为9的数据肯定在它后面。然后再读取最后一条数据id是12,就知道id为9的数据肯定在它前面,然后选择中间的数据读取,如此二分查找,很快就能锁定目标,不用每条数据都读取了。
因为每条数据都是32个字节,所以可以非常方便定位任意一条数据的位置:第n条数据的位置在32*(n-1)偏移处。
通过改变数据的存储组织形式,我们可以把数据查找的时间复杂度从O(N)下降到O(LogN)。
但如此一来,查找是变快了,但插入就麻烦了。以前的时候,我们直接把数据塞到文件最后就拍拍屁股走人了。但现在不行了,我们得把数据按照顺序,插入到合适的位置。
最麻烦的是,我们的数据是一条一条挨个码在一起的,如果中间某个位置要插入数据,就得把那个位置及其以后的数据通通往后移动,这就涉及到大量的数据复制移动,开销非常大。
要是每来一条insert操作就数据大量迁徙,那不得累得半死?
(其实不止插入,删除数据delete也同样如此麻烦)
就没有一种办法,可以同时插入快,查询也快吗?
仔细思考一下,前面我们把数据按顺序一条一条码在一起,查起来为什么快?
是因为做了排序以后,数据的存储位置有一条隐含的信息 :如果id比我们要找的小,那我们要找的肯定在它后面;反之,如果id比我们要找的大,那我们要找的肯定在它前面。
之所以有这个规律,是因为我们按id的大小进行了排序存储。
那如果现在回到最开始的那种方式,不排序了,还是一条一条顺序来写入,就没有这个信息了。
但如果,我们在每条数据记录中增加一些额外的信息,用来指示id比它小的在哪里,id比它大的又在哪里,是不是就能顺着这些额外的信息“顺藤摸瓜”找到你要找的数据呢?
或许,聪明的你已经看出来了,这是按照“二叉树”的形式在记录数据位置信息。
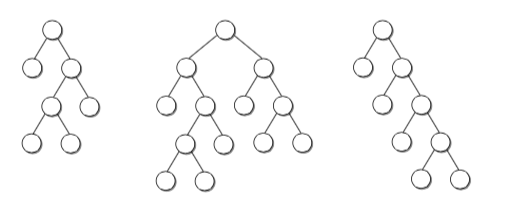
但实际上,二叉树也才两个分叉,如果数据量很大的话,这棵树就会很高很瘦。
而每一次走入一个分支,就对应着一次文件I/O,所以在实际使用中,不会使用二叉树,而是使用开了非常多个叉的树——B树或者B+树。
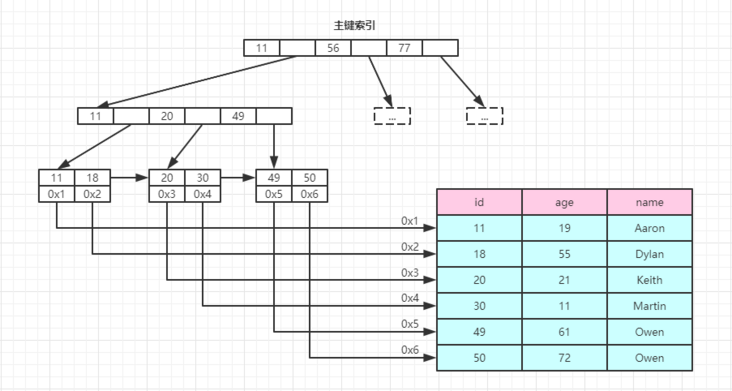
如果用B树或者B+树来将文件中的数据 在逻辑上 组织起来,要查找数据就会快得多。
用id来查找数据问题解决了,但如果要用name来查找又该怎么办呢?
想一想,如果另外有一个文件,记录了每个name和这个name对应的数据记录在文件中的偏移位置,就像这样:
| user_id | 数据位置(偏移) |
|---|---|
| xuanyuan | 0 |
| shuaidi | 31 |
| april | 63 |
| dibingfa | 95 |
有了这个东西,是不是就简单很多了?只需要在这里搜一遍,拿到数据的位置,然后打开文件,定位到对应的偏移,一下就读出来了。
我们可以另外准备一个文件,同样使用B树或者B+树的形式来组织上面表格中的对应关系。
聪明的你可能已经看出来了,这玩意儿其实就是索引。当然实际中的数据库系统的索引实现或多或少有一些差别,但道理是通用的。
是不是已经开始有些迷糊了?
没关系,这里轩辕推荐一个Github的开源项目,手把手教大家写一个最简单的数据库出来。
https://cstack.github.io/db_tutorial/

整个项目总共分13个课时,从最简单的内存数据库、到写磁盘持久化,从顺序写文件然后到B树和B+树的引入,完成一个完整的增删改查的数据库服务。
内容我看了,质量相当不错,Github收获了7.5K Star了,要说还是老外搞的开源项目给力啊。

我看很多朋友简历上的项目经历,要么是XXX管理系统,要么是一个Web服务器,这些都太烂大街了,你要是写上一个手写一个数据库系统,那绝对能让面试官眼前一亮。
数据库这块,用文字来描写感觉还是太过生涩了,轩辕打算后面用动画的形式做成视频放在B站,想看的同学点个赞吧,赞的越多,出的越快哦!
往期推荐