
elasticsearch倒排索引与TF-IDF算法


点击上方蓝色“迈莫coding”,选择“设为星标”
一、倒排索引(Inverted Index)简介
在关系数据库系统里,索引是检索数据最有效率的方式。但对于搜索引擎,它并不能满足其特殊要求,比如海量数据下比如百度或者谷歌要搜索百亿级的网页,如果使用类似关系型数据库使用的B+树索引,可想而知其对cpu的计算能力要求得有多高。其次关系型数据库中一般存储的都是结构化的数据,数据格式都是一定的,操作上一般也都是curd等比较简单的操作。
倒排索引区别于正向索引,一般的倒排索引被用来做全文搜索。比如现在有一本10w字的书,单词使用量为3k,我要从中搜索某个词出现的章节,我们该怎么做?
正排索引:遍历这本书,记录该次出现的章节。我们几乎要遍历完10w个词才能统计完。
倒排索引:建立倒排索引,将每个词作为key,该词出现的章节为value。我们只要在3k个单词中找到我们的目标词即可。
这样的话,显然倒排索引对于全文搜索性能更好。(上面举得例子不太好,凑合吧)
一般的正排索引是以key找value,而倒排索引则是以value找key。反转了key-value的关系。
二、es中的倒排索引
在es中text类型字段默认只会建立倒排索引,其它几种类型在建立倒排索引的时候还会建立正排索引,当然es是支持自定义的。在这里这个正排索引其实就是Doc Value。本章节我们主要是介绍倒排索引。下面我们介绍一个例子,看看倒排索引是如何建立的。
比如我们有两个doc(document 文档),都有一个content字段
doc_1:The quick brown fox jumped over the lazy dogdoc_2:Quick brown foxes jump over lazy dogs in summer
首先在es底层分词器会对doc进行分词,得到一个个term(单词),然后建立一个映射关系,记录存在各个单词的文档。首先我们分析一下各个单词存在的文档。
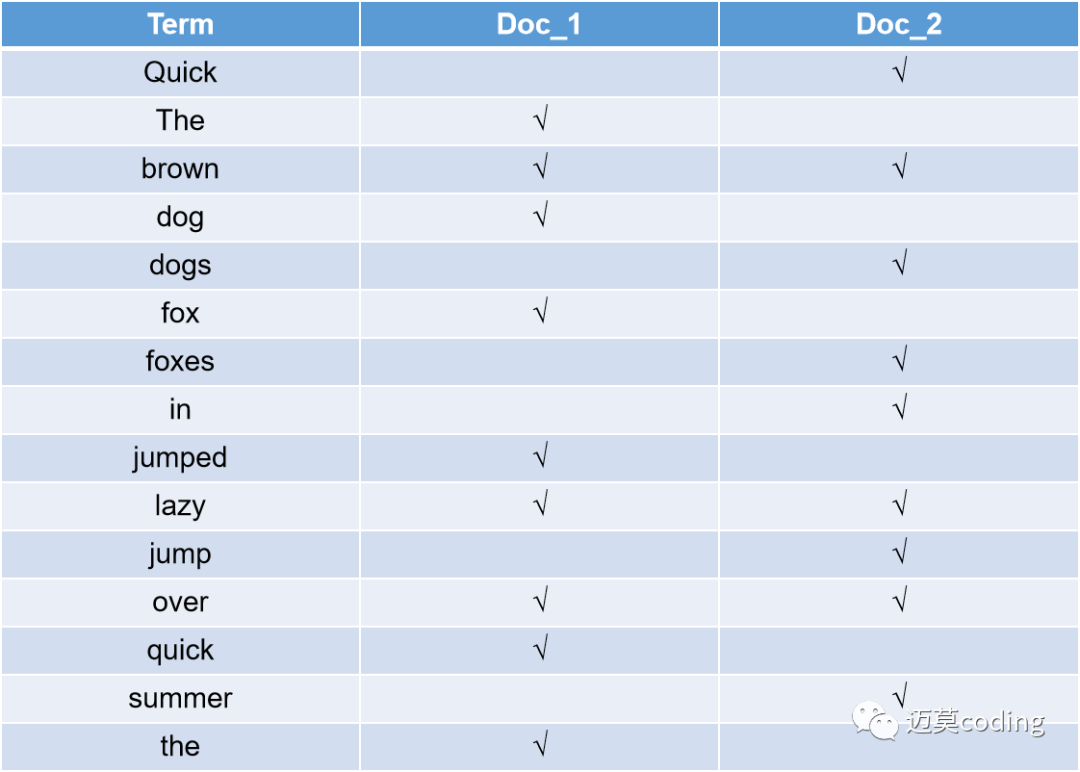
因为每个doc都是由id唯一标识的,所以其会建立一个映射关系。
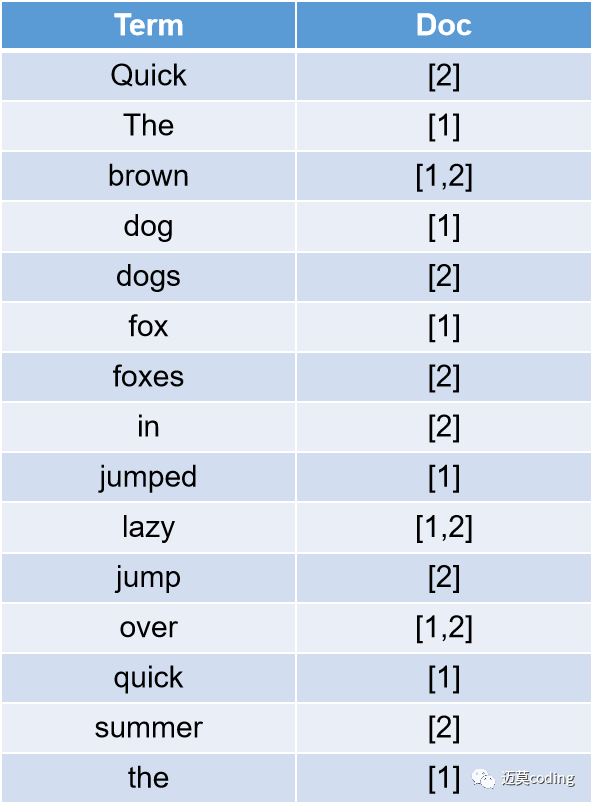
当es建立了这种映射关系,当我们搜索一个单词的时候,是不是就不需要遍历每个文档了呢。当然,es的倒排索引并不会这么简单。
term优化,比如我们用百度搜索“JUmped”这个词
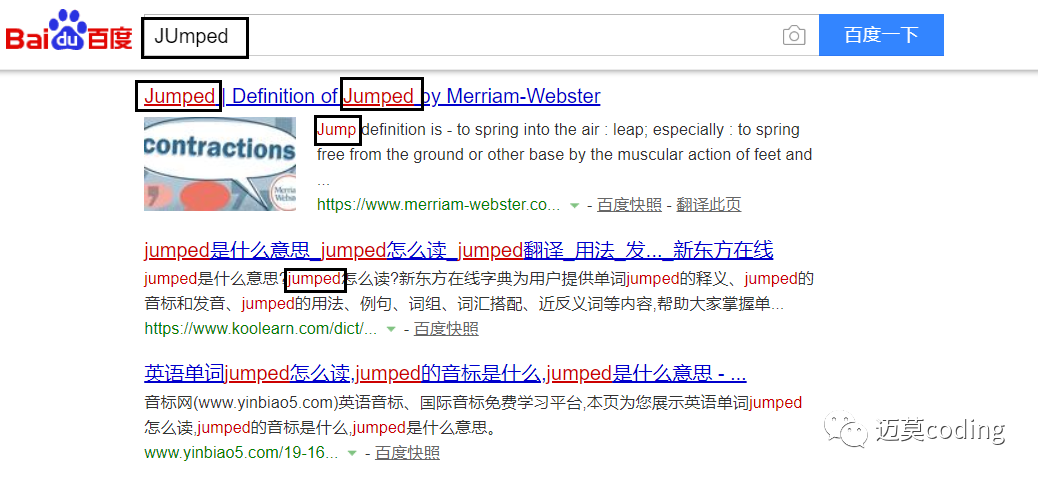
很容易发现,竟然区分好了大小写,并且还只能的匹配到了不同的时态。所以es同样也是这样的,es的分词器会对单词进行一定的处理,比如:
1 大小写转换:Quick --> quick2 近义词转换:mother --> mom3 时态转换:jumped --> jump4 单复数转换:dogs --> dog......注意:不同的分词器的分词方式和算法都是不尽相同的。要注意这一点。
当es进行了term优化之后,我们再看看这个倒排索引:

当倒排索引如上所示,我们很容易就能进行全文搜索。
三、TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
在es中进行全文搜索时,搜索结果的匹配度也是采用的TF-IDF算法。这个匹配度是能够在es的元数据 _score 属性中体现出来的。通过实验验证一下。
首先建立一个索引
PUT /my_index?pretty
插入数据
PUT /my_index/my_index_type/1{"content":"The quick brown fox jumped over the lazy dog"}PUT /my_index/my_index_type/2{"content":"Quick brown foxes jump over lazy dogs in summer"}
搜索
GET /my_index/my_index_type/_search{"query":{"match":{"content": "quick"}}}
搜索结果
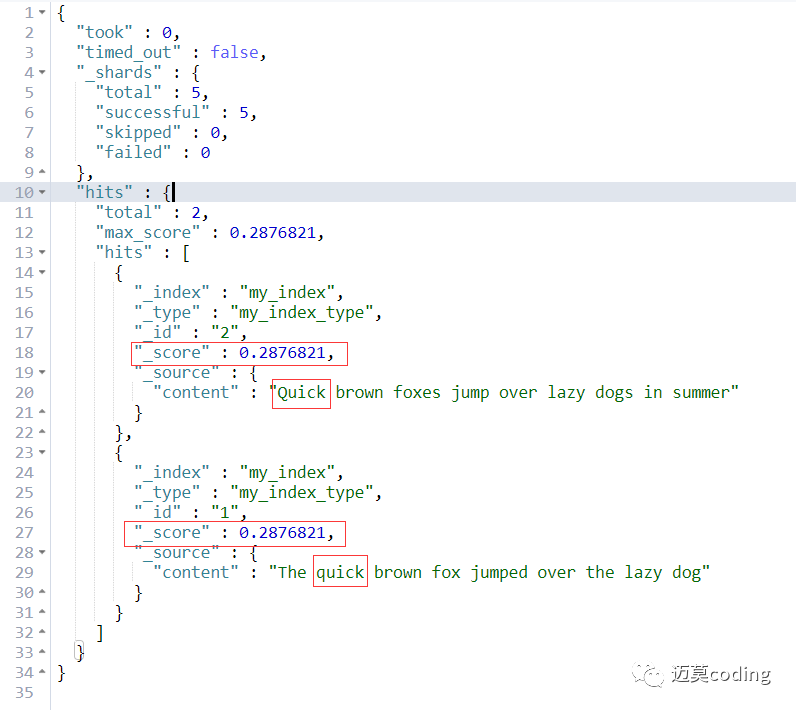
通过以上结果我们很容易发现,es通过TF-IDF算法计算出来了相关度 _score。并且还勿略了大小写。
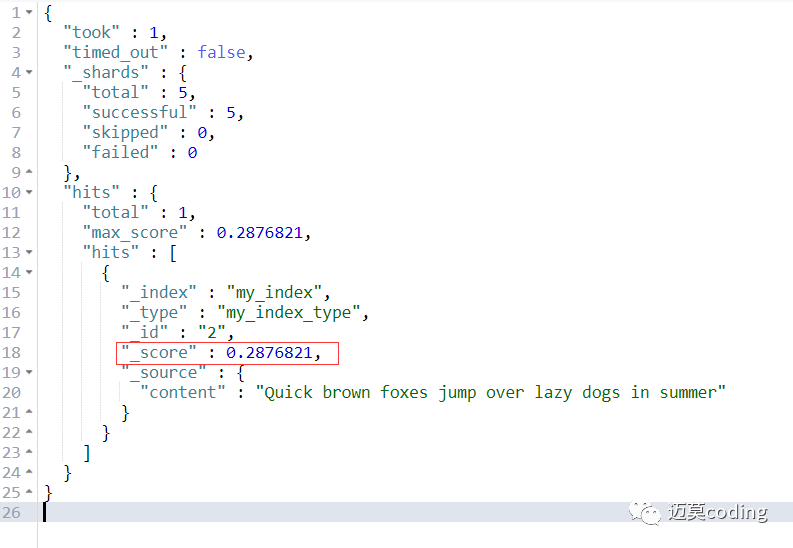
如果我们搜索单词“summer”,结果如下所示,只匹配到了doc1。
分割线
往期推荐
文章也会持续更新,可以微信搜索「 迈莫coding 」第一时间阅读。每天分享优质文章、大厂经验、大厂面经,助力面试,是每个程序员值得关注的平台。
你点的每个赞,我都认真当成了喜欢