
轻松学Pytorch – 行人检测Mask-RCNN模型训练与使用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

大家好,这个是轻松学Pytorch的第20篇的文章分享,主要是给大家分享一下,如何使用数据集基于Mask-RCNN训练一个行人检测与实例分割网络。这个例子是来自Pytorch官方的教程,我这里是根据我自己的实践重新整理跟解读了一下,分享给大家。
前面一篇已经详细分享了关于模型本身,格式化输入与输出的结果。这里使用的预训练模型是ResNet50作为backbone网络,实现模型的参数微调迁移学习。输入的数据是RGB三通道的,取值范围rescale到0~1之间。
数据集地址下载地址:
https://www.cis.upenn.edu/~jshi/ped_html/总计170张图像,345个标签行人,数据集采集自两所大学校园。

标注格式兼容Pascal标注格式。
基于Pytorch的DataSet接口类完成继承与使用,得到完成的数据聚集读取类实现代码如下:
from PIL import Image
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
import faster_rcnn.transforms as T
import os
class PennFudanDataset(Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.transforms = T.Compose([T.ToTensor()])
self.imgs = list(sorted(os.listdir(os.path.join(root_dir, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root_dir, "PedMasks"))))
def __len__(self):
return len(self.imgs)
def num_of_samples(self):
return len(self.imgs)
def __getitem__(self, idx):
# load images and bbox
img_path = os.path.join(self.root_dir, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root_dir, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path)
# convert the PIL Image into a numpy array
mask = np.array(mask)
# instances are encoded as different colors
obj_ids = np.unique(mask)
# first id is the background, so remove it
obj_ids = obj_ids[1:]
# split the color-encoded mask into a set
# of binary masks
masks = mask == obj_ids[:, None, None]
# get bounding box coordinates for each mask
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
if __name__ == "__main__":
ds = PennFudanDataset("D:/pytorch/PennFudanPed")
for i in range(len(ds)):
img, target = ds[i]
print(i, img.size(), target)
device = torch.device('cuda:0')
boxes = target["boxes"]
xmin, ymin, xmax, ymax = boxes.unbind(1)
targets = [{k: v.to(device) for k, v in t.items()} for t in [target]]
if i == 3:
break其中:
boxes表示的输入标注框
labels表示标签,这里0表示背景,1表示行人,两个分类
image_id表示图像标识
area表示标注框面积
mask对象标记,
训练数据集,epoch=8,因为我的计算机内存比较小,所有batchSize=1,不然我就会内存爆炸了,训练一定时间后,就好拉,我把模型保存为mask_rcnn_pedestrian_model.pt文件。训练的代码如下:
# 检查是否可以利用GPU
# torch.multiprocessing.freeze_support()
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available.')
else:
print('CUDA is available!')
# 背景 + 行人
num_classes = 2
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=num_classes, pretrained_backbone=True)
device = torch.device('cuda:0')
model.to(device)
dataset = PennFudanDataset("D:/pytorch/PennFudanPed")
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=1, shuffle=True, # num_workers=4,
collate_fn=utils.collate_fn)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.1)
num_epochs = 8
for epoch in range(num_epochs):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
lr_scheduler.step()
torch.save(model.state_dict(), "mask_rcnn_pedestrian_model.pt")上次训练Faster-RCNN的时候有人跟我说训练时候缺失文件,其实torchvision相关的辅助文件可以从这里下载,地址如下:
https://github.com/pytorch/vision/tree/master/references/detection这样大家就可以自己去下载拉!
当我们完成训练之后,就可以使用模型了,这里有个小小的注意点,当训练的时候我加载数据用的是Image.open方法读取图像,得到的是RGB顺序通道图像。在测试的时候我使用OpenCV来读取图像,得到是BGR顺序,所以需要通道顺序转换一下。千万别忘记。加载导出模型,读取测试图像,完成推理预测完整的代码如下:
import torchvision
import torch
import cv2 as cv
import numpy as np
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=2, pretrained_backbone=True)
model.load_state_dict(torch.load("./mask_rcnn_pedestrian_model.pt"))
model.eval()
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 使用GPU
train_on_gpu = torch.cuda.is_available()
if train_on_gpu:
model.cuda()
def object_detection__demo():
frame = cv.imread("D:/images/pedestrian_02.png")
frame = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
blob = transform(frame)
c, h, w = blob.shape
input_x = blob.view(1, c, h, w)
output = model(input_x.cuda())[0]
boxes = output['boxes'].cpu().detach().numpy()
scores = output['scores'].cpu().detach().numpy()
labels = output['labels'].cpu().detach().numpy()
index = 0
frame = cv.cvtColor(frame, cv.COLOR_RGB2BGR)
for x1, y1, x2, y2 in boxes:
if scores[index] > 0.9:
print("score: ", scores[index])
cv.rectangle(frame, (np.int32(x1), np.int32(y1)), (np.int32(x2), np.int32(y2)), (0, 0, 255), 2, 8, 0)
index += 1
cv.imshow("Mask-RCNN Demo", frame)
cv.imwrite("D:/pedestrian_02mask_rcnn.png", frame)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__ == "__main__":
object_detection__demo()测试了几张张图像,运行结果分别如下:

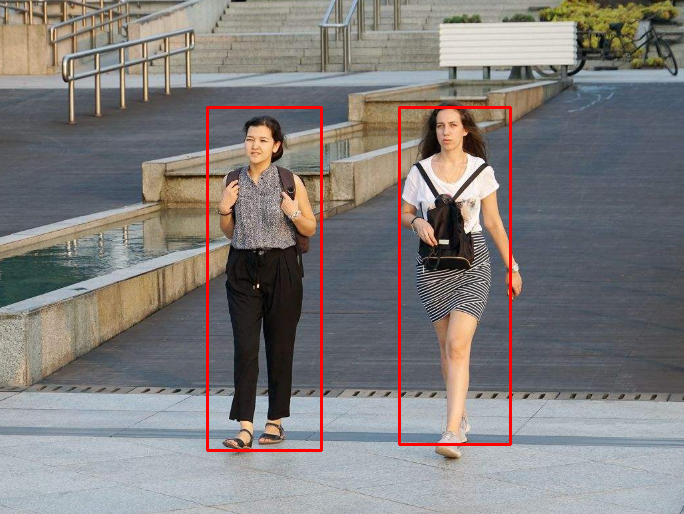

没想到效果这么好,真的很靠谱!真的实例分割模型,明显提升了检测效果。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~