
基于 OpenCV 的车牌识别
点击上方“Jack Cui”,选择加"星标"或“置顶”
重磅干货,第一时间送达

车牌识别的相关步骤
1.车牌检测:第一步是从汽车上检测车牌所在位置。我们将使用OpenCV中矩形的轮廓检测来寻找车牌。如果我们知道车牌的确切尺寸,颜色和大致位置,则可以提高准确性。通常,也会将根据摄像机的位置和该特定国家/地区所使用的车牌类型来训练检测算法。但是图像可能并没有汽车的存在,在这种情况下我们将先进行汽车的,然后是车牌。
2.字符分割:检测到车牌后,我们必须将其裁剪并保存为新图像。同样,这可以使用OpenCV来完成。
3. 字符识别:现在,我们在上一步中获得的新图像肯定可以写上一些字符(数字/字母)。因此,我们可以对其执行OCR(光学字符识别)以检测数字。
1.车牌检测
让我们以汽车的样本图像为例,首先检测该汽车上的车牌。然后,我们还将使用相同的图像进行字符分割和字符识别。如果您想直接进入代码而无需解释,则可以向下滚动至此页面的底部,提供完整的代码,或访问以下链接。
https://github.com/GeekyPRAVEE/OpenCV-Projects/blob/master/LicensePlateRecoginition.ipynb
此次使用的测试图像如下所示。

第1步: 将图像调整为所需大小,然后将其灰度。相同的代码如下
img = cv2.resize(img, (620,480) )gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #convert to grey scale
调整大小后,可以避免使用较大分辨率的图像而出现的以下问题,但是我们要确保在调整大小后,车号牌仍保留在框架中。在处理图像时如果不再需要处理颜色细节,那么灰度变化就必不可少,这加快了其他后续处理的速度。完成此步骤后,图像将像这样被转换。

步骤2:每张图片都会包含有用和无用的信息,在这种情况下,对于我们来说,只有牌照是有用的信息,其余的对于我们的程序几乎是无用的。这种无用的信息称为噪声。通常,使用双边滤波(模糊)会从图像中删除不需要的细节。
gray = cv2.bilateralFilter(gray, 13, 15, 15)语法为 destination_image = cv2.bilateralFilter(source_image, diameter of pixel, sigmaColor, sigmaSpace)。我们也可以将sigma颜色和sigma空间从15增加到更高的值,以模糊掉更多的背景信息,但请注意不要使有用的部分模糊。输出图像如下所示可以看到该图像中的背景细节(树木和建筑物)模糊了。这样,我们可以避免程序处理这些区域。

步骤3:下一步是我们执行边缘检测的有趣步骤。有很多方法可以做到,最简单和流行的方法是使用OpenCV中的canny edge方法。执行相同操作的行如下所示
edged = cv2.Canny(gray, 30, 200) #Perform Edge detection语法为destination_image = cv2.Canny(source_image,thresholdValue 1,thresholdValue 2)。阈值1和阈值2是最小和最大阈值。仅显示强度梯度大于最小阈值且小于最大阈值的边缘。结果图像如下所示

步骤4:现在我们可以开始在图像上寻找轮廓
contours=cv2.findContours(edged.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)contours = imutils.grab_contours(contours)contours = sorted(contours,key=cv2.contourArea, reverse = True)[:10]screenCnt = None
一旦检测到计数器,我们就将它们从大到小进行排序,并只考虑前10个结果而忽略其他结果。在我们的图像中,计数器可以是具有闭合表面的任何事物,但是在所有获得的结果中,牌照号码也将存在,因为它也是闭合表面。
为了过滤获得的结果中的车牌图像,我们将遍历所有结果,并检查其具有四个侧面和闭合图形的矩形轮廓。由于车牌肯定是四边形的矩形。
for c in cnts:# approximate the contourperi = cv2.arcLength(c, True)approx = cv2.approxPolyDP(c, 0.018 * peri, True)# if our approximated contour has four points, then# we can assume that we have found our screenif len(approx) == 4:screenCnt = approxbreak
找到正确的计数器后,我们将其保存在名为screenCnt的变量中,然后在其周围绘制一个矩形框,以确保我们已正确检测到车牌。

步骤5:现在我们知道车牌在哪里,剩下的信息对我们来说几乎没有用。因此,我们可以对整个图片进行遮罩,除了车牌所在的地方。相同的代码如下所示
# Masking the part other than the number platemask = np.zeros(gray.shape,np.uint8)new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)new_image = cv2.bitwise_and(img,img,mask=mask)
被遮罩的新图像将如下所示

2.字符分割
车牌识别的下一步是通过裁剪车牌并将其保存为新图像,将车牌从图像中分割出来。然后,我们可以使用此图像来检测其中的字符。下面显示了从主图像裁剪出ROI(感兴趣区域)图像的代码
# Now crop(x, y) = np.where(mask == 255)(topx, topy) = (np.min(x), np.min(y))(bottomx, bottomy) = (np.max(x), np.max(y))Cropped = gray[topx:bottomx+1, topy:bottomy+1]
结果图像如下所示。通常添加到裁剪图像中,如果需要,我们还可以对其进行灰色处理和边缘化。这样做是为了改善下一步的字符识别。但是我发现即使使用原始图像也可以正常工作。

3.字符识别
该车牌识别的最后一步是从分割的图像中实际读取车牌信息。就像前面的教程一样,我们将使用pytesseract包从图像读取字符。相同的代码如下
#Read the number platetext = pytesseract.image_to_string(Cropped, config='--psm 11')print("Detected license plate Number is:",text)

原始图像上印有数字“ CZ20FSE”,并且我们的程序检测到它在jupyter笔记本上打印了相同的值。
车牌识别失败案例
车牌识别的完整代码,其中包含程序和我们用来检查程序的测试图像。要记住,此方法的结果将不准确。准确度取决于图像的清晰度,方向,曝光等。为了获得更好的结果,您可以尝试同时实现机器学习算法。
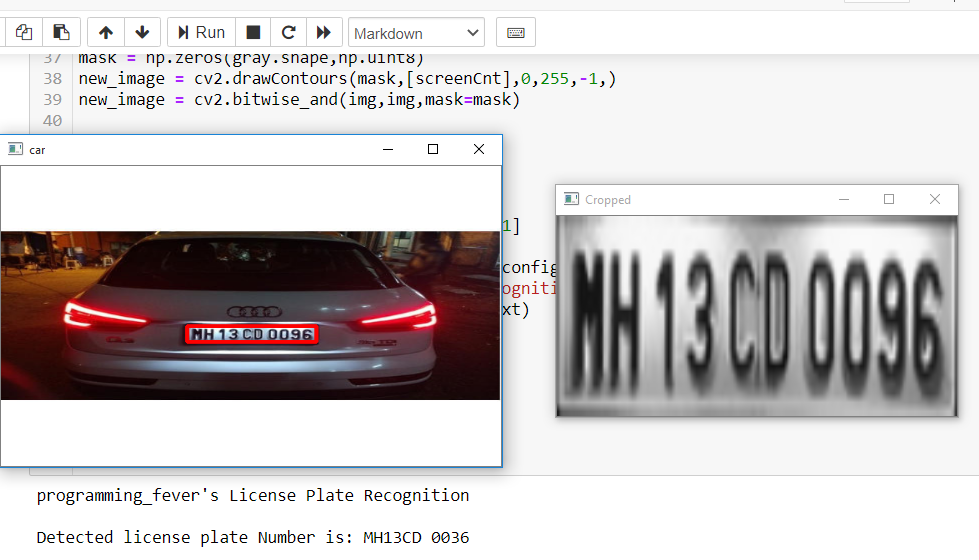
这个案例中我们的程序能够正确检测车牌并进行裁剪。但是,Tesseract库无法正确识别字符。OCR已将其识别为“ MH13CD 0036”,而不是实际的“ MH 13 CD 0096”。通过使用更好的方向图像或配置Tesseract引擎,可以纠正此类问题。
其他成功的例子
大多数时候,图像质量和方向都是正确的,程序能够识别车牌并从中读取编号。下面的快照显示了获得的成功结果。


完整代码
#@programming_feverimport cv2import imutilsimport numpy as npimport pytesseractpytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'img = cv2.imread('D://skoda1.jpg',cv2.IMREAD_COLOR)img = cv2.resize(img, (600,400) )gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)gray = cv2.bilateralFilter(gray, 13, 15, 15)edged = cv2.Canny(gray, 30, 200)contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)contours = imutils.grab_contours(contours)contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]screenCnt = Nonefor c in contours:peri = cv2.arcLength(c, True)approx = cv2.approxPolyDP(c, 0.018 * peri, True)if len(approx) == 4:screenCnt = approxbreakif screenCnt is None:detected = 0print ("No contour detected")else:detected = 1if detected == 1:cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)mask = np.zeros(gray.shape,np.uint8)new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)new_image = cv2.bitwise_and(img,img,mask=mask)(x, y) = np.where(mask == 255)(topx, topy) = (np.min(x), np.min(y))(bottomx, bottomy) = (np.max(x), np.max(y))Cropped = gray[topx:bottomx+1, topy:bottomy+1]text = pytesseract.image_to_string(Cropped, config='--psm 11')print("programming_fever's License Plate Recognition\n")print("Detected license plate Number is:",text)img = cv2.resize(img,(500,300))Cropped = cv2.resize(Cropped,(400,200))cv2.imshow('car',img)cv2.imshow('Cropped',Cropped)cv2.waitKey(0)cv2.destroyAllWindows()
