
Service Mesh:Istio 的前世今生
来源:https://morven.life/posts/the_history_of_istio/
其实要彻底了解Istio以及服务网格出现的背景,就得从计算机发展的早期说起。
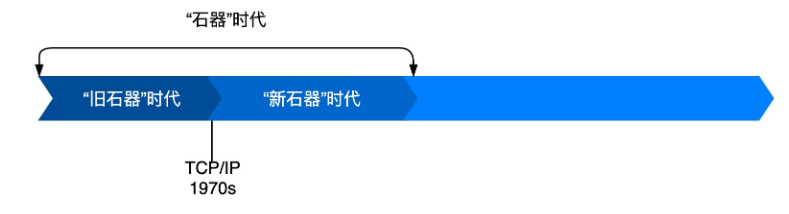
下面这张图展示的的通信模型变种其实从计算机刚出现不久的上世纪50年代开始就得到广泛应用,那个时候,计算机很稀有,也很昂贵,人们手动管理计算机之间的连接,图中绿色的网络栈底层只负责传输电子信号和字节码:
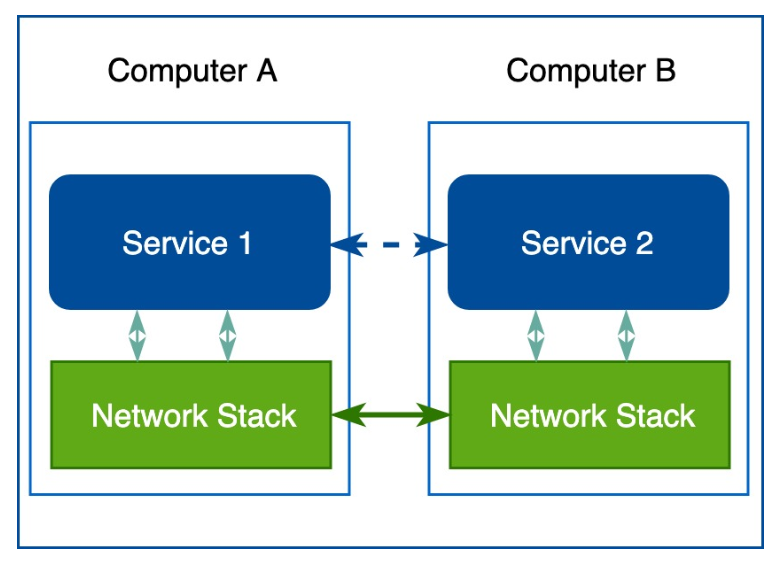
随着计算机变得越来越普及,价格也没那么贵了,计算机之间的连接数量和通信的数据量出现了疯狂式的增长,人们越来越依赖网络系统,工程师们必须确保他们开发的服务能够满足用户的要求。于是,如何提升系统质量成为人们关注的焦点。机器需要知道如何找到其他节点,处理同一个通道上的并发连接,与非直接连接的机器发生通信,通过网络路由数据包,加密流量……除此之外,还需要流量控制机制,流量控制可以防止下游服务器给上游服务器发送过多的数据包。
于是,在一段时期内,开发人员需要在自己的代码里处理上述问题。在下面这张图的示例中,为了确保下游服务器不给其他上游服务造成过载,应用程序需要处理流量控制逻辑,于是网络中的流量控制逻辑和业务逻辑就混杂在一起:
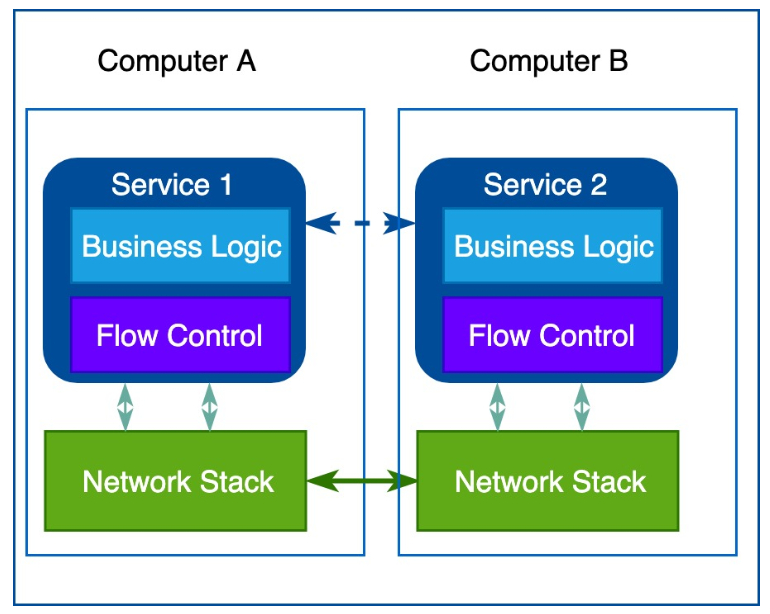
幸运的是,上世纪60年代末,TCP/IP协议栈的出现解决了可靠传输和流量控制等问题,此后尽管网络逻辑代码依然存在,但已经从应用程序里抽离出来,成为操作系统网络栈的一部分,工程师只需要按照操作系统的调用接口进行编程就可以解决基础的网络传输问题:

进入21世纪,计算机越来越普及,也越来越便宜,相互连接的计算机节点越来越多,业界出现了各种网络系统,如分布式代理和面向服务架构(SOA):

分布式为我们带来了更高层次的能力和好处,但却带来了新的挑战。这时候工程师的重心开始转移到应用程序的网络功能上面,这时候的服务之间的对话以“消息”为传输单元,当工程师们通过网络进行调用服务时,必须能为应用程序消息执行超时、重试、确认等操作。
于是,有工程师是开始尝试使用消息主干网(messaging backbone)集中式地来提供、控制应用程序网络功能,如服务发现、负载均衡、重试等等,甚至,比如协议调解、消息转换、消息路由、编排等功能,因为他们觉得如果可以将这些看似同一层面的内容加入到基础设施中,应用程序或许会更轻量、更精简、更敏捷等等。这些需求绝对是真实的,ESB(Enterprise Service Bus)演变并满足了这些需要。ESB在是2005年被提出的,它的概念特别类似于计算机硬件概念里的USB, USB作为电脑中的标准扩展接口,可以连接各种外部设备;而ESB则就把路由管理、协议转换、策略控制等通用应用程序网络功能加到现有的集中式消息总线里:
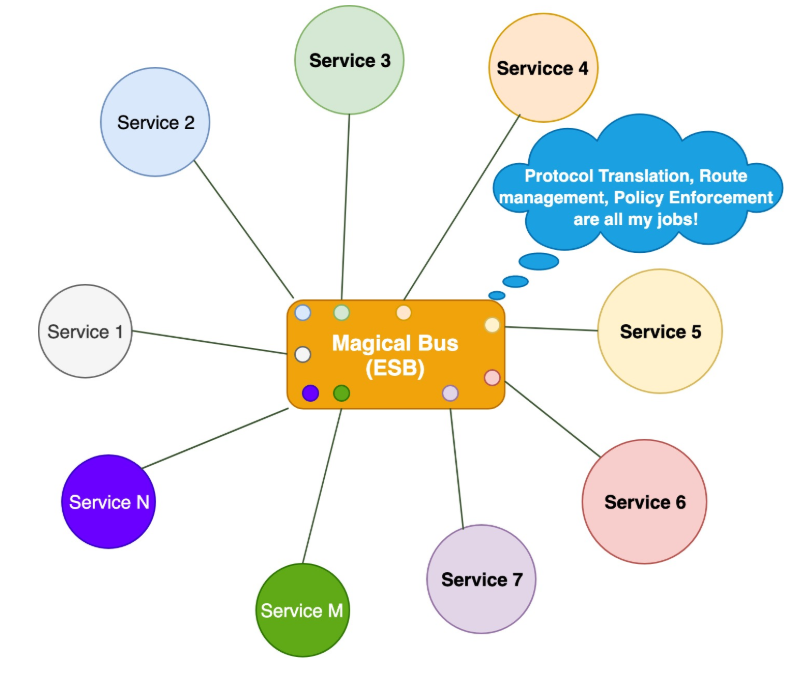
这看似行得通!
可是,在实施SOA架构的时候,工程师们发现这种架构有点儿用力过度,矫枉过正了。集中式的消息总线往往会成为架构的瓶颈,用它来进行流量控制、路由、策略执行等并不像我们想象那么容易。加上组织结构过于复杂,使用专有格式(XML等),需要业务逻辑需要实现路由转换和编排等功能,各个服务之间耦合度很高,在敏捷运动的时代背景下,ESB架构已经无法跟上时代的节奏了。
在接下来的几年内,REST革命和API优先的思潮孕育了微服务架构应用,而以docker为代表的容器技术和以Kubernetes为代表的容器编排技术的出现促进了微服务架构的落地。事实上,微服务时代可以以Kubernetes的出现节点划分为“前微服务时代”和“后微服务时代”:

“前微服务时代”基本上是微服务作为用例推动容器技术的发展,而到“后微服务时代”,特别是成为标准的Kubernetes其实在驱动和重新定义微服务的最佳实践,容器和Kubernetes为微服务架构的落地提供了绝佳的客观条件。
微服务架构有很多好处,比如:
快速分配计算资源
快速部署升级迭代
易于分配的存储
易于访问的边界等等
但是作为较复杂的分布式系统,微服务架构给运维带来了新的挑战。当工程师开始接尝试微服务架构,必须考虑如何进行微服务治理。狭义的微服务治理,关注的是微服务组件之间的连接与通讯,例如服务注册发现、东西向路由流控、负载均衡、熔断降级、遥测追踪等。
历史总是惊人的相似,第一批采用微服务架构的企业遵循的是与第一代网络计算机系统类似的策略,也就是说,解决网络通信问题的任务又落在了业务工程师的肩上。
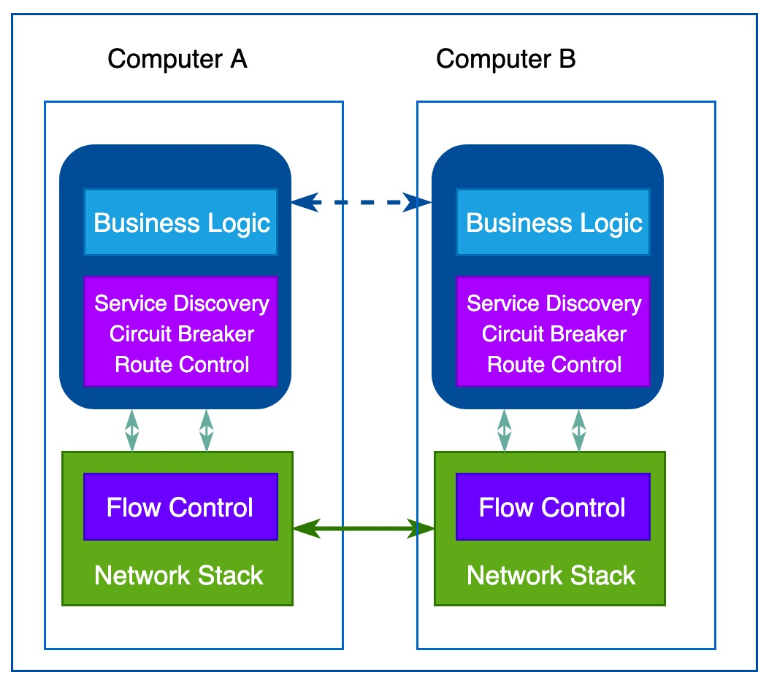
这个时候出现了看到诸如Netflix OSS堆栈、Twitter Finagle以及赫赫有名的Spring Cloud这样的框架和类库帮助业务工程师快速开发应用程序级别的网路功能,只需要写少量代码,就可以把服务发现,负载均衡,路由管理,遥测收集,监控告警等这些功能实现:
但是如果仔细想一下的话,就会发现这样编写微服务程序的问题很明显。
这些类库或者框架是特定语言编写的,并且混合在业务逻辑中(或在整个基础设施上层分散的业务逻辑中)。姑且不说类库和框架的学习成本和门槛,我们知道微服务架构问世的一个承诺就是不同的微服务可以采用不同的编程语言来编写,可是当你开始编写代码的时候会发现有些语言还没有提供对应的类库。这是一个尴尬的局面!这个问题非常尖锐,为了解决这个问题,大公司通常选择就是统一编程语言来编写微服务代码另外的问题是,升级怎么办?框架不可能一开始就完美无缺,所有功能都齐备,没有任何BUG。升级一般都是逐个版本递进升级,一旦出现客户端和服务器端版本不一致,就要小心维护兼容性。实际上,每做出一次变更都需要进行集成、测试,还要重新部署所有的服务——尽管服务本身并没有发生变化。
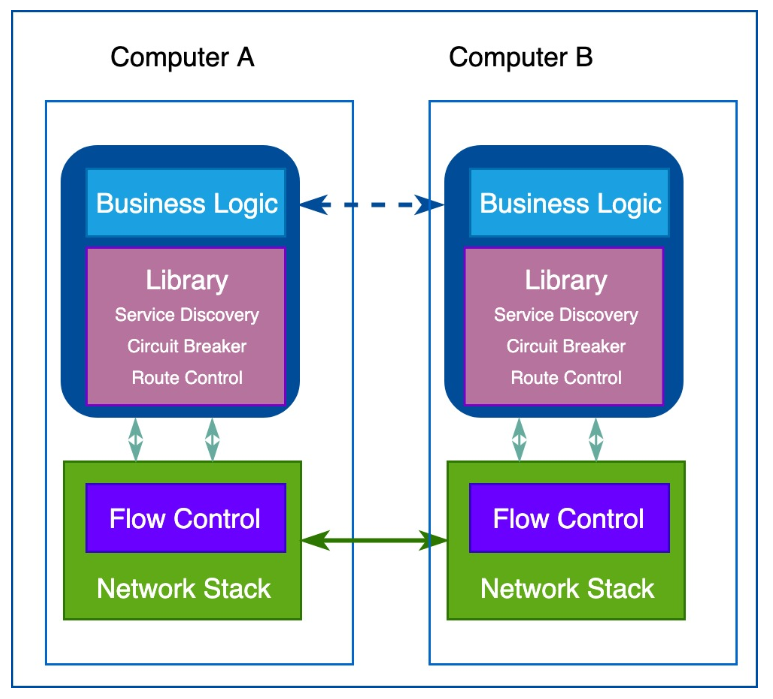
与网络协议栈一样,工程师们急切地希望能够将分布式服务所需要的一些特性放到底层的平台中。这就像工程师基于HTTP协议开发非常复杂的应用,无需关心底层TCP如何控制数据包。在开发微服务时也是类似的,业务工程师们聚焦在业务逻辑上,不需要浪费时间去编写服务基础设施代码或管理系统用到的软件库和框架。把这种想法囊括到之前架构中,就是下边这幅图所示的样子:

不过,在网络协议栈中加入这样的一个层是不实际的。貌似可以尝试一下代理的方案!事实上,确实有有一些先驱者,尝试过使用代理的方案,例如nginx,haproxy,proxygen等代理。也就是说,一个服务不会直接与上游服务发生连接,所有的流量都会流经代理,代理会拦截服务之间的请求并转发到上游服务。可是,那时候代理的功能非常简陋,很多工程师尝试之后觉得没有办法实现服务的客户端所有的需求。
在这样的诉求下,第一代的Sidecar出现了,Sidecar扮演的角色和代理很像,但是功能就齐全很多,基本上原来微服务框架在客户端实现的功能都会有对应的实现:
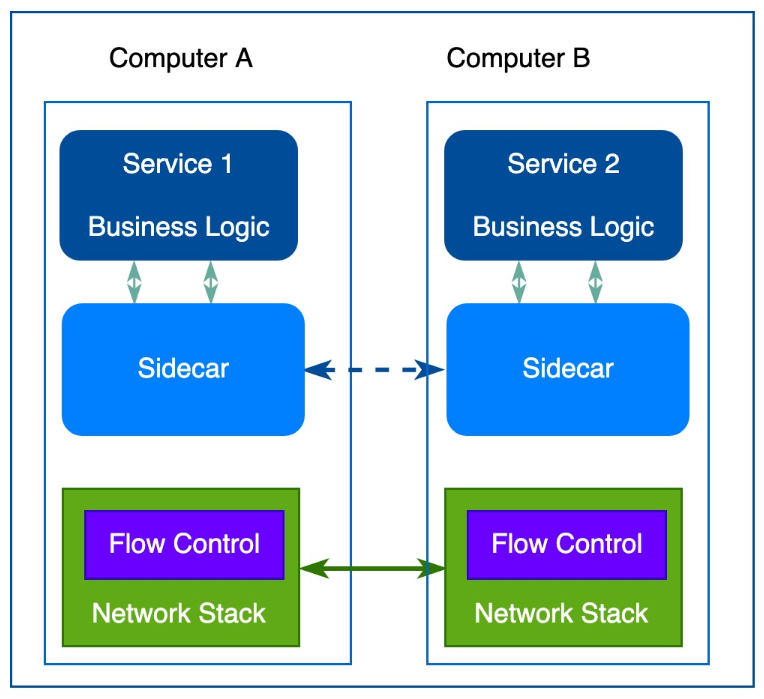
但是第一代的sidecar有一个重要的限制,它们是专门为特定基础设施组件而设计的,导致无法通用。例如,Airbnb的Nerve和Synapse,它们工作的基础是服务一定是注册到ZooKeeper上的,而Netflix的Prana要求一定要使用Netflix自己的Eureka注册服务…
随着微服务架构日渐流行,新一波的sidecar出现了,可以用在不同基础设施组件上,我们把他们叫做通用型的sidecar。其中Linkerd是业界第一个通用型sidecar,它是基于Twitter微服务平台而开发的,实际上也正是它创造了Service Mesh,即服务网格的概念。2016年1月15日,Linkerd 0.0.7版本发布,随后加入CNCF,1.0版本于2017年4月份发布;随后的通用型sidecar就是大名鼎鼎来自于Lyft的envoy,Lyft在2016年9月发布envoy的1.0版本之后。2017年9月envoy加入CNCF;最后一个比较新的sidecar来自于我们熟悉的NGINX,叫做Nginmesh,2017年9月发布了第一个版本。
有了通用型sidecar,每个微服务都会有一个sidecar代理与之配对,服务间通信都是通过sidecar代理进行的。正如我们在下这幅图上看到的那样,sidecar代理之间的连接形成了一种网格网络:

这就是服务网格概念的来源,下面是服务网格概念地官方定义,它不再把sidecar代理看成单独的组件,并强调了这些sidecar代理所形成的网络的重要性。
A service mesh is a dedicated infrastructure layer for making service-to-service communication safe, fast, and reliable.
实际上,就像TCP/IP网络栈为我们抽象了网络传输的细节一样,有了服务网格,我们不需要再担心微服务之间通信的各种网络诉求,如服务发现和负载均衡,流量管理,策略执行,监控告警等。
服务网格的概念出现之后,有部分工程师们开始将的微服务部署到更为复杂的运行时(如Kubernetes和Mesos)上,并开始使用这些基础平台提供的网络工具来管理整个服务网格里的所有sidecar,也就是从一系列独立运行的sidecar代理转向使用集中式的控制面板来管理所有的sidecar代理。
在Google内部,很早通过一个分布式平台对微服务进行管理,通过代理处理内部与外部的协议。这些代理的背后是一个控制面板,它在开发者与运维人员之间提供了一层额外的抽象,在这层抽象之上对跨语言与系统平台的服务进行管理。经过实战的检验,这套架构已经证明它能够确保高伸缩性、低延迟性,并为Google的各项服务提供了丰富的特性。
在2016年,Google决定开发一个对微服务进行管理的开源项目,它与Google内部使用的平台有很大的相似性,该项目命名为“Istio”, Istio在希腊语中的意思是“启航”。就在Google启动Istio项目的几乎同一时间,IBM也发布了一个名为Amalgam8的开源项目,这是一个基于NGINX代理技术,为微服务提供基于内容的路由方案的项目。随后,Google和IBM意识到这两个项目在使用场景与产品愿景上存在很大一部分交集,于是答应成为的合作伙伴,IBM放弃Amalgam8的开发,共同基于Lyft公司 的envoy项目打造Istio这款产品。
Istio的出现将服务网格的概念发扬光大,它创新性地将服务网格逻辑上划分为控制面板和数据面板,
随着分布式应用一起部署的sidecar成为数据平面(Data Plane),它能够拦截网络请求,并控制服务之间的通信;
而集中是的管理模块成为控制平面(Control Plane),它提供策略实施、遥测数据收集以及证书轮换等功能;
在整个网络里面,所有的流量都在sidecar代理的控制当中,所有的sidecar代理都在控制面板控制当中,因此,可以通过控制面板控制整个服务网格,这是Istio带来的最大的革新。
就如我们在上面这幅图上看到的那样,Istio默认使用envoy作为sidecar代理(事实上,Istio利用了envoy内建的大量特性,例如服务发现与负载均衡、流量拆分、故障注入、熔断器以及金丝雀发布等功能),而在控制平面Istio也分为四个主要模块:
Pilot: 为sidecar代理提供服务发现功能和配置下发功能;它将控制流量的高级路由规则转换为特定于envoy的配置,并在运行时将它们传播到envoy;
Mixer: 负责在服务网格上执行访问控制和策略检查,并从envoy代理收集遥测数据;代理提取请求级属性,发送到Mixer进行评估;
Citadel: 证书分发和管理中心;通过内置身份和凭证管理,用于升级服务网格中未加密的流量,并为运维人员提供基于服务标识的访问策略;
Galley: 统一的配置消化,验证和分发中心;未来的版本中Galley将承担更多的责任,从而将其他的Istio组件与从底层平台(例如Kubernetes)细节中隔离开来;
2018年7月31日,Istio1.0正式发布,距离最初的0.1版本发布以来已经过了一年多时间了。
从0.1起,Istio就在蓬勃发展的社区、贡献者和用户的帮助下迅速发展。现在已经有许多公司成功将Istio应用于生产,并通过Istio提供的洞察力和控制力获得了真正的价值。Istio帮助大型企业和快速发展的创业公司,如eBay、Auto Trader UK、Descartes Labs、HP FitStation、Namely、PubNub和Trulia使用Istio从头开始连接、管理和保护他们的服务。
同时,整个Istio生态系统也不断的扩张,envoy增加了许多对生产级别服务网格至关重要的功能,包括与许多可观察性工具的集成,像Datadog、 SolarWinds、 Sysdig、Google Stackdriver和Amazon CloudWatch这样的可观察性提供商也编写了插件来将Istio与他们的产品集成在一起;Red Hat构建的Kiali为网格管理和可观察性提供了良好的用户体验;Knative无服务化项目也正基于Istio开发下一代下一代流量路由堆栈;Apigee宣布计划在他们的API管理解决方案中使用它。
- END -
推荐阅读
点亮,服务器三年不宕机
