
冠军方案!2023第二届广州·琶洲算法大赛
Datawhale干货
作者:唐楚柳,算法工程师,冠军选手
1.简介
大家好我是Alex,31岁,现为一名图像算法工程师,主要研究方向是计算机视觉图像识别。工作之余的研究兴趣包括ocr,aigc,llm,vit。获得
-
2021 CVPR PIC Challenge: 3D Face Reconstruction From Multiple 2D Images(第7名) -
2021 IKCEST第三届“一带一路”国际大数据竞赛(第10名) -
2022“域见杯”医检人工智能开发者大赛(第6名) -
2022 粤港澳大湾区(黄埔)国际算法算例大赛-路测3D感知算法(第4名) -
2023 CVPR 2023 1st foundation model challenge-Track1(第6名)
本次主要分享在2023第二届广州·琶洲算法大赛基于文心交通大模型的多任务联合训练赛题的Rank1方案。

2.赛题分析
近年来,智慧汽车、人工智能等产业发展,为智能交通发展创造了良好的发展机遇。智能交通相关技术已经渗透到我们的日常生活中,但是现有大模型的多任务处理模式以及传统的感知方法(如分类、检测、分割等)无法满足我们对更广交通场景以及更高自动驾驶水平的追逐。我们从当前实际技术研究中的关键问题出发,解决多任务、多数据间冲突的问题。本赛道联合分类、检测、分割三项CV任务三大数据集至单一大模型中,使得单一大模型具备能力的同时获得领先于特定单任务模型的性能。
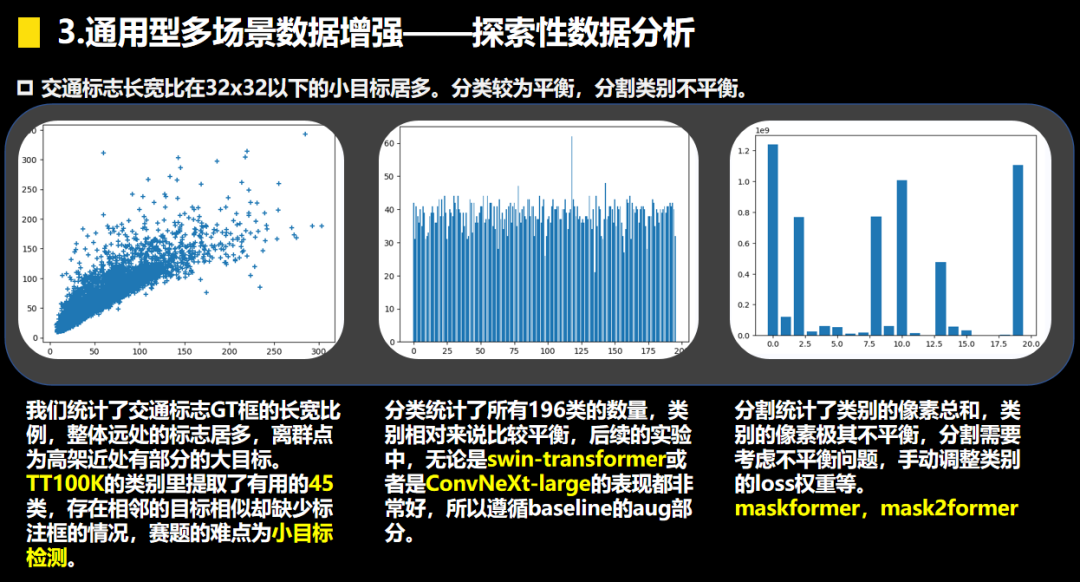
3.解题思路
在本次赛题的数据挖掘中,我们发现赛题的难点在于类别不平衡的语义分割和小目标检测,在backbone选型的问题上我们有一点小分歧,Convnext-Large 和Swin-L。从实践的角度看在数据量充足的情况考虑transformer,而数据量少的情况下优先考虑cnn,当前比较 优秀的两个backbone为swin-transformer和convnxet。我们在这两个backbone上的实验比较多,主要为了解决类别不平衡的语义分割和小目标检测,主要围绕以下的几点展开:
-
骨干网络选型Convnext-Large 和Swin-Large -
检测头和分割头的选型 (DINO,RT-DETR,YOLOv5,yolov7)(upernet,maskformer,mask2former) -
多尺度训练 -
检测的sahi切图方案。 -
检测的copypaste方案。 -
TTA 后处理 (检测的多尺度推理,分割的多次结果ensemble mulit scale推理)
4.方案
4.1 ConvNeXt多任务网络结构
我们的整体的方案如下图所示,主体的网络结构为ConvNeXt-Large,在网络的每一个stage后输出一个特征图feature,主体的设计为三个任务共享feature,目标检测部分单独使用一个FPN(输入为feature1,2,3)后接上yolov5Head,分类使用了feature4的特征,分割使用feature1,2,3,4,后接上mask2former Head。
4.2 YOLOCSPPAN的网络结构图
P2,P3,P4 对应4.1中的feature2,3,4。P4经过卷积,上采样和P3在通道上合并,由CSPLayer提取特征得到新P3,同理得到最终的P2,
最终输出的P2经过stride为2的卷积和新P3在通道上合并,由CSPLayer提取特征得到最终输出的P3,最终输出的P3经过stride为2的卷积和P4在通道上合并,由CSPLayer提取特征得到最终输出的P4.

FPN输出的P2,3,4会传入三个yolov5Head,ConvNeXt配合yolohead会有较高的涨点(图出自百度AI公众号-汇集YOLO系列经典和前沿算法,实现高精度实时检测!)
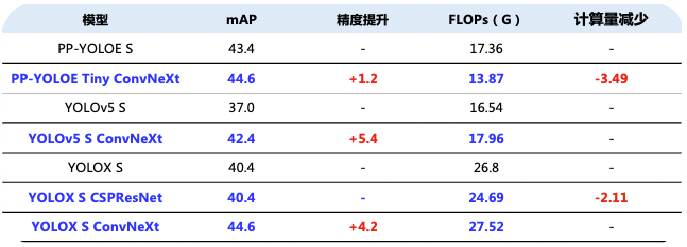

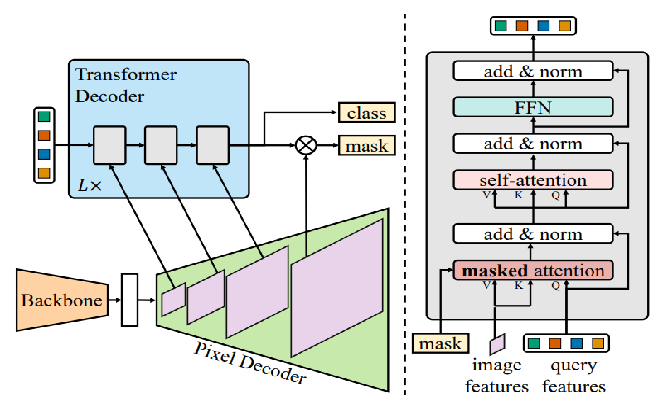
SegmentationHead我们考虑到了像素的类别不平衡的问题,最先开始调试MaskFormer,Masks2Former同时调试了,从下图我们可以看出Mask2Former在semantic的指标上比高出MaskFormer 1.1%,而在instance和panoptic上比MaskFormer高出5.1%和10%。
MaskFormer和Mask2Former的区别在于后者使用了多尺度的信息。

4.3数据增强
随机缩放(尺度变换):对输入图像进行随机的放大或缩小操作,可以增加数据样本的多样性,使模型能够处理不同尺度的目标物体。
随机裁剪(位置变换):从输入图像中随机裁剪出固定大小的区域作为训练样本,通过改变目标物体的位置来增加数据的多样性。
随机水平翻转(镜像):以一定的概率对输入图像进行水平翻转操作,使得模型能够学习到目标物体在不同方向上的特征。
高斯噪声:向输入图像中添加高斯噪声,可以增加图像的复杂性,使得模型能够更好地适应真实世界中的噪声情况。
高斯模糊:对输入图像进行高斯模糊操作,可以减少图像中的细节信息,从而使得模型能够更关注目标物体的整体形状和结构。
旋转:对输入图像进行随机旋转操作,可以增加目标物体在不同角度下的样本,提高模型对目标物体旋转不变性的学习能力。
网格型变:通过对输入图像进行网格型扭曲操作,可以引入局部形变,增加数据的多样性。
随机色彩变换:对输入图像进行随机的色彩变换,如调整亮度、对比度和饱和度等,以增加图像的多样性。
随机天气(BDD雨雾天气居多):通过向输入图像中添加随机的天气效果,如雨、雾等,模拟真实场景下的变化,提高模型对复杂环境的适应能力。
这些数据增强方法的使用可以有效地增加训练样本的多样性,从而提高模型对不同场景和变化的泛化能力。同时,合适的数据增强方法选择也需要根据具体任务的特点和需求进行调整和优化。

HSV 颜色增强:对输入图像进行 HSV 颜色空间的随机调整,如调整亮度、对比度和饱和度等,以增加样本的多样性和泛化能力。
随机裁剪:从输入图像中随机裁剪出固定大小的区域作为训练样本,这有助于模型学习到不同目标物体的局部特征,并提高模型的鲁棒性。
Resize 1024:将输入图像的大小调整为固定的尺寸(例如 1024x1024),这既有助于减少显存占用,增大批量大小(BS),又能够在一定程度上提高模型的检测精度。
随机翻转:以一定的概率对输入图像进行水平或垂直翻转操作,以增加数据样本的多样性,并保持目标物体的不变性。

4.4调参优化策略
整体考虑到显存数据集规模和模型收敛的节点 50000 iter 附近
训练设置 58200 max_iter
由于是余弦周期 考虑在50000 节点 衰减学习率solver_steps=[50000],)

optimizer = L(build_lr_optimizer_lazy)(
optimizer_type='AdamW',
base_lr=1e-4,
weight_decay=1e-4,
grad_clip_enabled=True,
grad_clip_norm=0.1,
apply_decay_param_fun=None,
lr_multiplier=L(build_lr_scheduler_lazy)(
max_iters=60000,
warmup_iters=200,
solver_steps=[50000],
solver_gamma=0.1,
base_lr=1e-4,
sched='CosineAnnealingLR',
),
)
调参策略:
-
swin-tiny -
upernet -
maskformer/mask2former -
RT-DETR -
yolov5 -
swin-transformer -
slice det image -
copypaste
调优过程:
我们从swin-tiny开始 再到convnext-L的upernet,dino(减少transformer层的)检测的效果一直不佳。优先考虑单任务的调参,从Segmentation开始,从PaddleSeg调试maskformer,mask2former其实在同阶段已经调通,我们为了节省调优的时间,mask2former需要更长的训练周期 2Days more,而且maskformer的精度是接近当时榜上的最好的成绩。检测部分仍然很差,开始调优ppyoloe-head,ppyolo的head train需要额外的参,过于复杂,所以调试了RT-DETR,这个过程中尝试了slice切图,2048的大尺度推理等策略,经过多轮的调参,我们把检测的head换回yolov5 anchor base的head,继续尝试多尺度的ms tta。
在6月底,重新修改了baseline。使用convnext-L+maskformer-fc head -yolov5 head,作为新基线。继续尝试1024 切图,mosaic 等transform。发现反而掉点,接下来对检测的目标进行crop,随机贴图全类别做会导致seg的掉点,我们平衡了数据集,将<400 个目标的class 进行贴图训练,指标能到94.8 接下来换backbone,我们将backbone 换成swin-transformer-L 那么当前的结构为 swin-L+maskformer +fc head yolov5。seg 直接涨到 0.69 但是 配上RT-DETR head 检测不佳。最终我们换回new base 7.1号的方案,把maskformer换成mask2former。
更多的实验结果可以去我的repo查看:https://github.com/chuliuT/OneForAll_mask2former_yolov5
5.调参经验
-
3e-4通常是一个很好的学习率,AdamW+CosineWarmup -
在模型选型的前期可以使用少量的数据和轻量级的网络来尝试调优 -
数据集的EDA分析在调优的同时尽快找出赛题难点,需要处理的地方 -
数据增强的组合需要更多的实验的尝试,但有效的只有那么两三个 -
模型训练的收敛时间节点需要实验去预估 -
不到最后一刻,不要放弃你的提交
6 .总结
随着数据的规模大小和模型的日益更新,越来越多的研究者开始倾向于使用transformer模型来处理图像任务。因为transformer模型具有较好的表现力和良好的迁移性,逐渐取代了传统的convnet模型在图像处理领域的主导地位。
然而,尺度变化一直是一个令人头疼的问题。在处理图像中的尺度变化时,尝试了各种策略,如多尺度训练和图像金字塔等方法,以应对不同尺度下的物体检测和分类任务。除了尺度变化,图像中还存在着其他挑战,例如小目标检测、细粒度分类和语义分割中的像素不平衡。
对于小目标检测问题,采用了random_crop和ms推理的方式来提高性能。在细粒度分类任务中,致力于解决类别之间差异较小导致的难题,通过引入更加精细的特征表示和auto-augment来改善分类结果。而在语义分割任务中,类别像素不平衡问题一直存在,探索了各种通用和任务特定的解决方案,如不确定损失函数、像素平衡采样等方法来解决。ConvNeXt和Swin-Transformer是当前主流的两种模型派系。ConvNeXt具有更快的收敛时间,适合处理大规模数据集,而Swin-Transformer在表现力和迁移能力方面更好。
在本赛题中,我们在设计方案时考虑了精度和收敛时间之间的权衡关系,选择了ConvNeXt-Large作为基础网络结构,并结合了clshead、mask2former和yolov5Head组合以达到更好的综合性能。然而,在多任务训练中,如何控制grad的scale仍然是一个待解决的问题。当前的训练策略导致了语义分割任务过早进入收敛期,而分类和目标检测任务仍处于欠拟合阶段。展望未来,多任务大模型的联合训练仍然是一个具有挑战性的课题。同时,在微调阶段如何保持历史知识也是一个重要的问题。视觉提示微调(Visual Prompt Tuning)给了我们一些启示,但还需要进一步的研究和验证其效果。我们相信通过不断地探索和创新,可以进一步提升多任务视觉大模型的性能和应用范围。
7 .参考文献
[1]. Liu, Zhuang, et al. A ConvNet for the 2020s. arXiv preprint arXiv:2201.03545, 2022.
[2]. Liu, Ze, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. p. 10012-10022.
[3] https://mp.weixin.qq.com/s/Hki01Zs2lQgvLSLWS0btrA
[4] Per-Pixel Classification is Not All You Need for Semantic Segmentation
[5] Masked-attention Mask Transformer for Universal Image Segmentation
[6] DETRs Beat YOLOs on Real-time Object Detection
[7] Unified Perceptual Parsing for Scene Understanding
[8]https://aistudio.baidu.com/aistudio/projectdetail/6337782?sUid=930878&shared=1&ts=1691544272476
[9]https://github.com/xiteng01/CVPR2023_foundation_model_Track1
[10] https://github.com/HandsLing/CVPR2023-Track1-2rd-Solution