
95%PyTorch库都会中招的bug!特斯拉AI总监都没能幸免

明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
到底是怎样的一个bug,能让95%的Pytorch库中招,就连特斯拉AI总监深受困扰?
还别说,这个bug虽小,但有够“狡猾”的。
这就是最近Reddit上热议的一个话题,是一位网友在使用再平常不过的Pytorch+Numpy组合时发现。
最主要的是,在代码能够跑通的情况下,它甚至还会影响模型的准确率!

除此之外,网友热议的另外一个点,竟然是:
而是它到底算不算一个bug?

这究竟是怎么一回事?
事情的起因是一位网友发现,在PyTorch中用NumPy来生成随机数时,受到数据预处理的限制,会多进程并行加载数据,但最后每个进程返回的随机数却是相同的。
他还举出例子证实了自己的说法。
如下是一个示例数据集,它会返回三个元素的随机向量。这里采用的批量大小分别为2,工作进程为4个。

然后神奇的事情发生了:每个进程返回的随机数都是一样的。
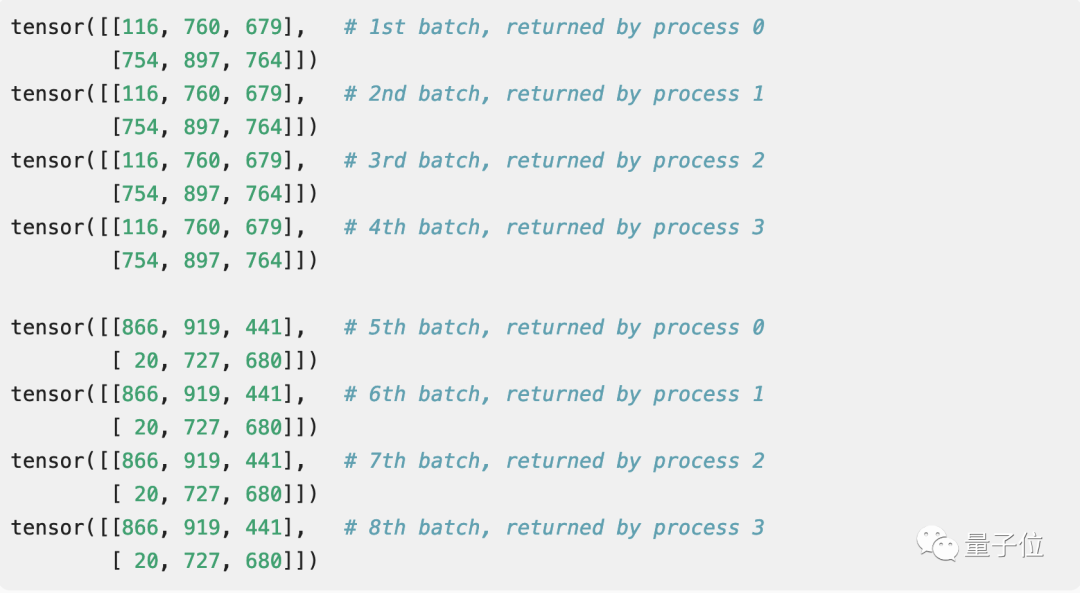
这个结果会着实让人有点一头雾水,就好像数学应用题求小明走一段路程需要花费多少时间,而你却算出来了负数。
发现了问题后,这位网友还在GitHub上下载了超过10万个PyTorch库,用同样的方法产生随机数。
结果更加令人震惊:居然有超过95%的库都受到这个问题的困扰!
这其中不乏PyTorch的官方教程和OpenAI的代码,连特斯拉AI总监Karpathy也承认自己“被坑过”!
但有一说一,这个bug想要解决也不难:只需要在每个epoch都重新设置seed,或者用python内置的随机数生成器就可以避免这个问题。
到底是不是bug?
如果这个问题已经可以解决,为什么还会引起如此大的讨论呢?
因为网友们的重点已经上升到了“哲学”层面:
这到底是不是一个bug?
在Reddit上有人认为:这不是一个bug。
虽然这个问题非常常见,但它并不算是一个bug,而是一个在调试时不可以忽略的点。

就是这个观点,激起了千层浪花,许多人都认为他忽略了问题的关键所在。
这不是产生伪随机数的问题,也不是numpy的问题,问题的核心是在于PyTorch中的DataLoader的实现

对于包含随机转换的数据加载pipeline,这意味着每个worker都将选择“相同”的转换。
而现在NN中的许多数据加载pipeline,都使用某种类型的随机转换来进行数据增强,所以不重新初始化可能是一个预设。
另一位网友也表示这个bug其实是在预设程序下运行才出现的,应该向更多用户指出来。
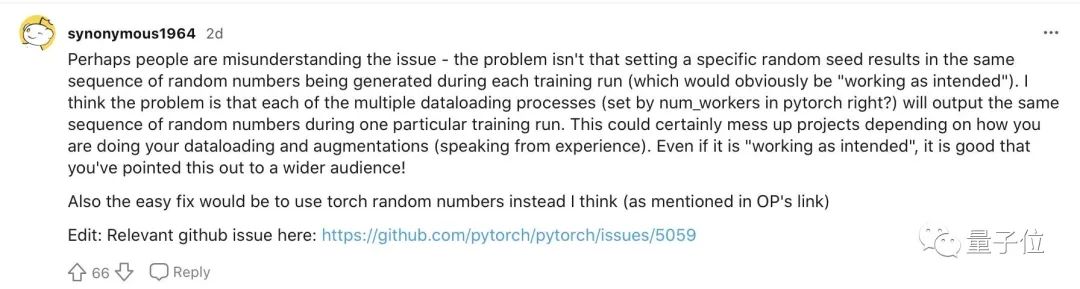
并且95%以上的Pytorch库受此困扰,也绝不是危言耸听。
有人就分享出了自己此前的惨痛经历:
我认识到这一点是之前跑了许多进程来创建数据集时,然而发现其中一半的数据是重复的,之后花了很长的时间才发现哪里出了问题。

也有用户补充说,如果 95% 以上的用户使用时出现错误,那么代码就是错的。

顺便一提,这提供了Karpathy定律的另一个例子:即使你搞砸了一些非常基本代码,“neural nets want to work”。
你有踩过PyTorch的坑吗?
如上的bug并不是偶然,随着用PyTorch的人越来越多,被发现的bug也就越来越多,某乎上还有PyTorch的坑之总结,被浏览量高达49w。

其中从向量、函数到model.train(),无论是真bug还是自己出了bug,大家的血泪史还真的是各有千秋。
所以,关于PyTorch你可以分享的经验血泪史吗?
欢迎评论区留言讨论~
参考链接:
[1]https://tanelp.github.io/posts/a-bug-that-plagues-thousands-of-open-source-ml-projects/
[2]https://www.reddit.com/r/MachineLearning/comments/mocpgj/p_using_pytorch_numpy_a_bug_that_plagues/
[3]https://www.zhihu.com/question/67209417/answer/866488638
— 完 —