
No.2时序数据库随笔 - IoTDB核心技术剖析
共 5996字,需浏览 12分钟
·
2021-03-18 01:13
2021 校招请阅读:阿里云2021春招
---------------------------------------------------------------------------
【阿里招聘】精通Java,熟悉数据结构和基本算法,有开源开发和IoT领域背景优先,边缘端 存储+计算 方向,P7/P8 级别。
有意愿加微信:18158190225 私聊,备注 应聘Java开发。
---------------------------------------------------------------------------
【摘要】Gartner指出赋能边缘是2020年十大战略技术趋势之一,5G加速IoT领域的发展,物联网设备数据的收集,存储和计算需求与日俱增。Apache IoTDB是物联网时序数据收集、存储、管理与分析为一体的的软件系统。Apache IoTDB作为Apache的2020新晋顶级项目,以其出色的表现得到了Apache的认可!目前Apache IoTDB与Hadoop、Spark和Flink等进行了深度集成,可以完全胜任工业物联网领域的海量数据存储、高速数据读取和复杂数据分析的需求。本次分享将为大家对Apache IoTDB的前世今生和核心的技术进行详细介绍.

大家好,很开心在今天的峰会和大家一起分享ApacheIoTDB 的核心技术剖析的内容。
首先,还是简单的自我介绍一下,我是孙金城,花名 金竹,来自阿里巴巴,从2016年开始一直投入在开源建设中,目前是ApacheFlinkPMC成员,ApacheBeamCommitter和ApacheIoTDB的PMC成员。同时也是Apache 软件基金会的成员,ApacheMember。

那么,今天我们会有4个部分的内容,首先是和大家一起聊聊IoT领域的发展趋势。

目前5G正当时,马老师也曾说过,5G催化了IoT的发展,80%的5G利好会体现在物联网领域。那么,这并不是一个预言而是一个现实,目前中国和美国工业互联网,以及德国的工业4.0都在蓬勃发展中。
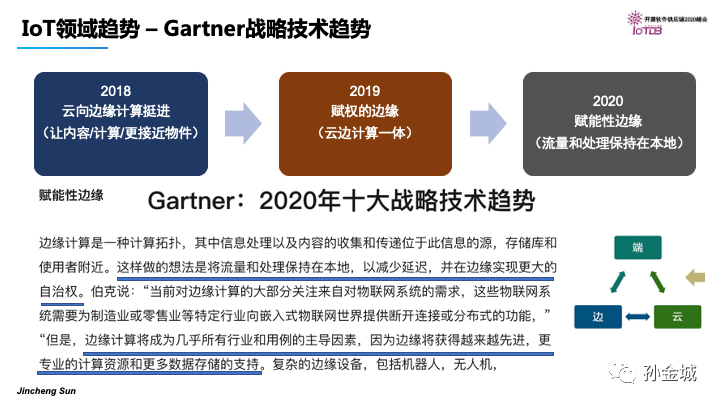
其实,早在2018年Gartner就评估出云向边缘计算挺进是十大战略技术趋势,在2019年和2020年也连续强调赋权和赋能边缘,云边端一体成为IoT领域的典型架构。
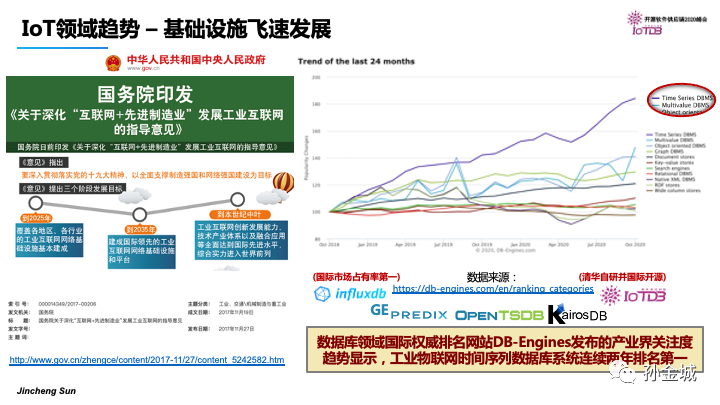
同时,国务院在2017年就发布了工业互联网的指导意见,并给出阶段性的基建目标。
从数据库领域的权威排名情况看,时序数据数据库从2018年开始,热度不断攀升,同时涌现出很多优秀的时序数据库产品,比如Influxdb,opentsdb以ApacheIoTDB。
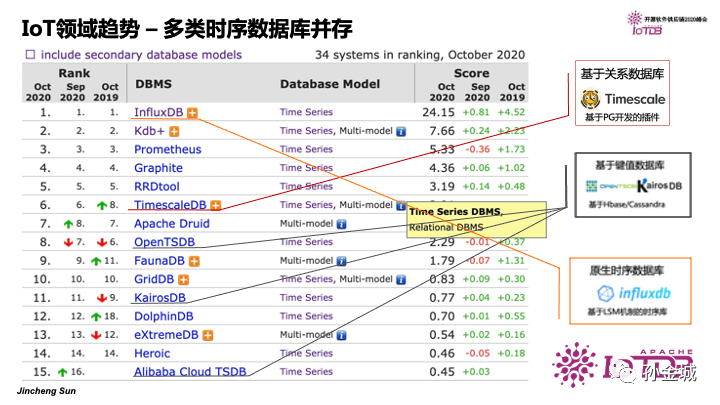
目前时序数据库有30多个,从架构的角度又可以分为三大类
第一类,以TimescaleDB为代表基于关系的时序数据库
第二类,以OpenTSDB为代表的基于KV的时序数据库
第三类,专门为时序数据数据而生的 InfluxDB和AapacheIoTDB。
那么这三类数据库有怎样的特点呢?
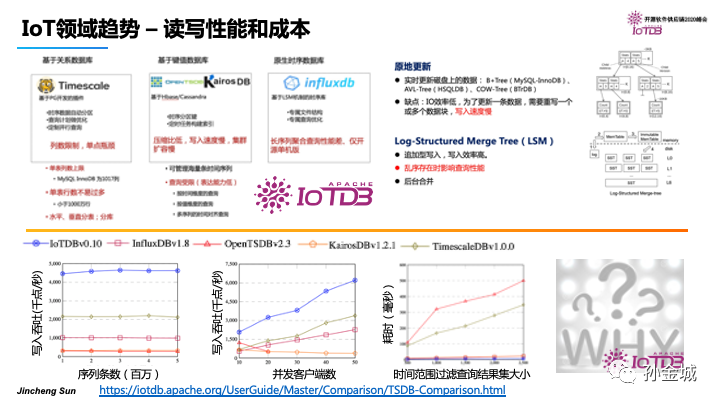
基于关系的时序数据库是建立在B+tree的数据结构之上的,在写入上有先天的局限。基于KV的时序数据库在索引的建立上存储弊端,导致查询能力受限。那么基于LSMTree的InfluxDB和IoTDB在架构上都解决了高吞吐写入问题,同时IoTDB官方也给出了一些性能测试数据。我们看到IoTDB不论是写入还是查询都有很大的优势。那么这些造就这些优势的本质是什么呢?就是我们今天要与大家分享的核心内容。

那么我们一起来看看IoTDB的核心技术点,这一部分可能会有点复杂,需要大家集中精力我们一起讨论。
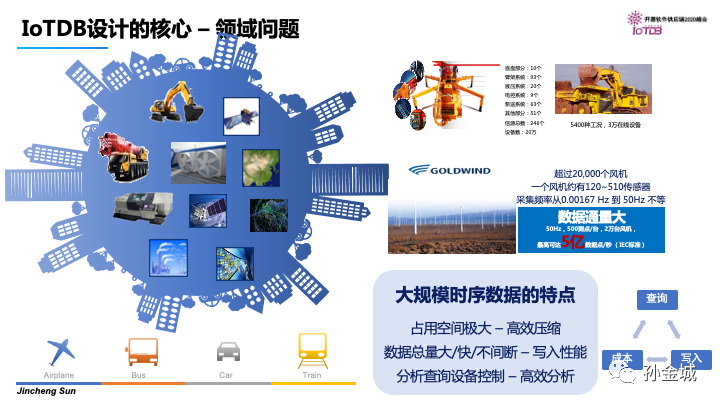
技术都是以解决实际问题为根本的,首先我们要看看IoT时序数据的领域问题有哪些。
时序数据的来源有多种,交通设施,智能楼宇,以及工况指标数据等。尤其在领域数据规模是一个不容忽视的现实问题,比如金风发电案例,2w个风机,每个风机500个测点,以50Hz的频率进行采集,数据量达到了5亿/秒的吞吐需求。
所以IoT领域的时序数据存储计算涉及到了 存储成本/写入吞吐/查询性能 三个非常重要的领域问题。
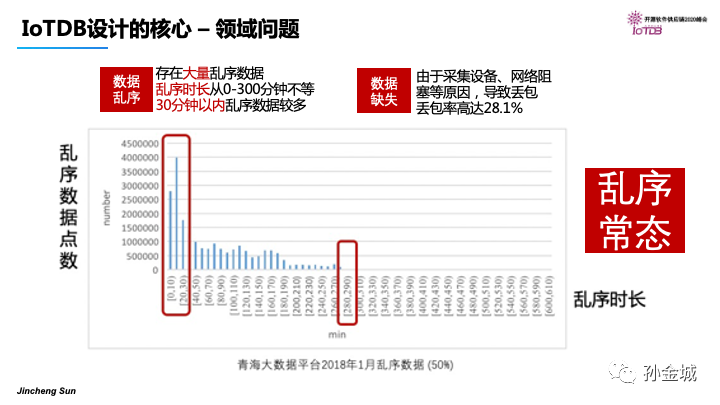
同时还有一个客观存在的问题就是乱序问题,这个是青海大数据平台在2018年真实数据情况,IoT工业领域的时序数据乱序是一种常态。
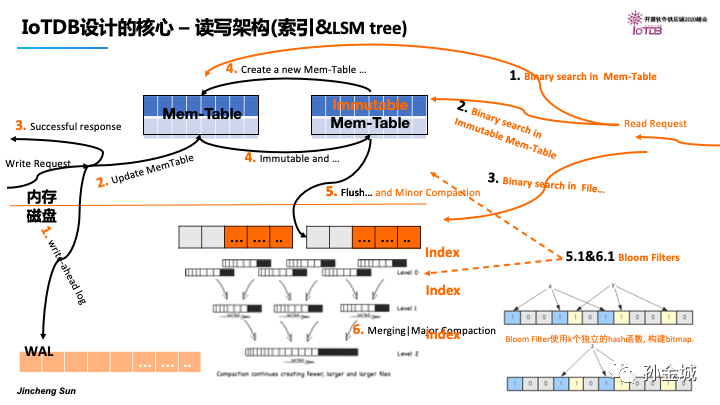
好,面对上面的问题IoTDB基于LSMtree的架构进行设计,LSM树的核心思想就是放弃部分读能力,换取写入能力的最大化。核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到一定程度后,再使用归并排序的方式将内存中的数据合并追加到磁盘队尾。我们来看一下这个基于LSM Tree的写入过程:
一个数据写入到来之后,先进行WAL的落盘。写WAL是为了恢复,真正的有序写入要将数据写入内存,也就是Mem-Table,然后对Mem-Table进行排序,数据写入到内存之后,就表示写入成功了。
那么写到内存之后会怎样操作呢?就是要解决落盘问题。当内存数据到达一定规模,就需要写入磁盘,LSM Tree的做法是将要刷磁盘的Mem-Table变成immutable,刷磁盘同时不影响写入请求,在创建一个新的Mem-table。同时我们对持久化的数据进行合并和索引的建立。
那么查询逻辑是怎么样的呢?查询逻辑最核心的是要查询索引,首先在内存Mem-table里面查询,然后在immutable Mem-table里面进行查找,然后是磁盘Flie里面进行查找。当然这里有Bloom filter辅助查询。Bloom filter本质就是一个bitmap,每个key数据用k个独立的hash就行计算,填充bitmap,数据查询时候Bloomfilter说没有一定没有,Bloomfilter说有,不一定有,还要继续索引查找。
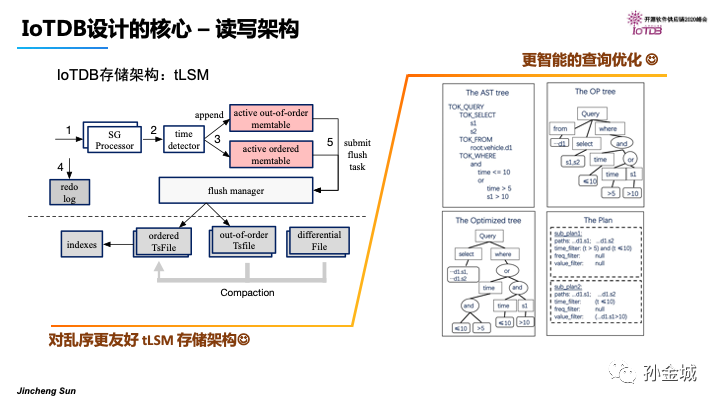
那么,IoTDB架构设计是对LSM的优化加强,针对IoT时序数据乱序问题进行了重点设计考虑,从内存到文件存储都有有序和乱序数据的特殊处理,更大程度的解决乱序问题。同时IoTDB具有查询优化机制,可以为用户提供极致的查询性能。这些从宏观的角度我们可以感知IoTDB的优秀,但是具体细节上有怎样的设计考虑呢,我们接下来看细节。
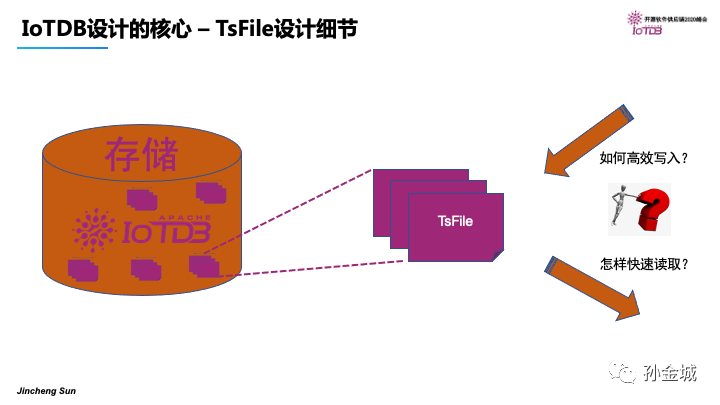
IoTDB本质是一个数据库,是一个存储系统,那么最终数据是以文件的方式进行存储管理,IoTDB设计了自己的TsFile格式,那么怎样的文件格式设计才能满足高效的写入和快速的读取呢?

首先以实际的查询需求来反推TsFile的文件格式,通常我们更希望同一个设备的数据存储在一起,并且每一个Measurement信息在磁盘上连续存储是最高效的。
所以,在逻辑上IoTDB将一个设备的数据抽象为一个ChunkGroup,每个ChunkGroup进行独立的云数据管理。
同时,对每个Measurement数据集中存储到一个Chunk中。
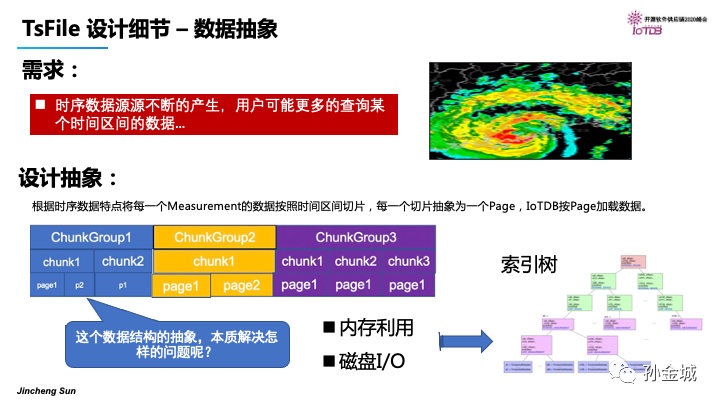
同时,在实际的工业场景中,我们大多会根据时间区间查询某些工况信息。
所以我们也需要针对时间区间进行抽象,IoTDB里面将chunk数据按时间区间再划分为若干的Page信息。
那么,这样的数据结构抽象,本质上是在最终达到怎样的目的呢?
那就是充分利用边缘端有限的内存资源,最大程度的减少磁盘的IO。我们以最优的方式构建索引树。
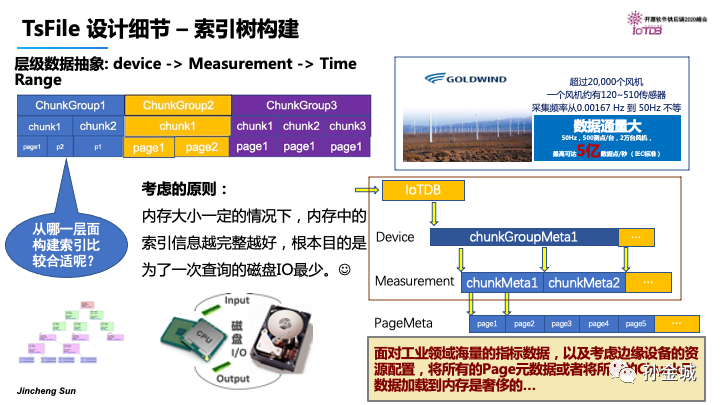
那么,索引树的节点信息保存那一层的数据抽象信息比较合适呢?是保存pange信息?还是chunk信息,还是全部信息,在有限的资源情况下,如何取舍?
那么这个取舍的原则就是,在内存大小一定的情况下,内存中的索引信息越完整越好。根本目的是为了减少磁盘IO。
既然page是细粒度的数据块,那么是否可以将所有page的元信息进行索引树构建呢?
其实通过刚才的风机案例,我们会发现工业场景7*24小时的不间断数据采集,每秒5亿的数据点,会形成海量的page,将page作为索引树节点信息,构建的树将将是一个巨大的树,即便是将所有chunk信息都加载到内存也是一个巨大的挑战。
那么最初,我们是利用了Device和Measurement的粒度进行索引信息的构建的。也就是我们针对ChunkGroup和Chunk进行Meta信息的构建。
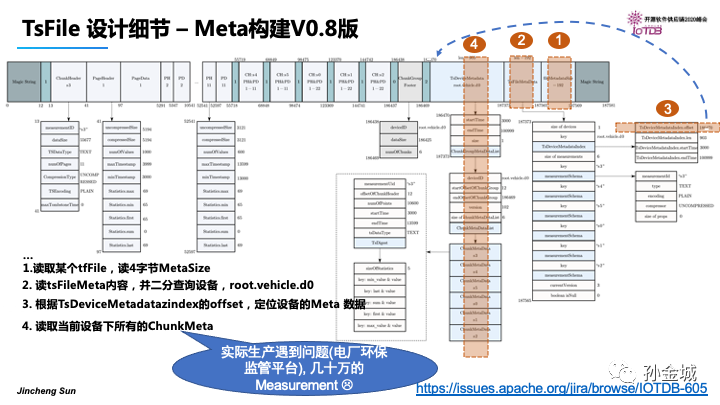
这是IoTDB0.8版本TsFile的完整结构,其中包括了data和tsFile的Meta信息/Device的Metat信息/Chunk的Meta信息。查询一个设备工况信息时候对文件的读取过程是这样的:
第一,读取4个字节的MetaSize,
第二,根据Meta的内容,进行二分查找,设备信息,比如d信息。
第三,根据Device的MetadataIndex的offset定位到Device的Meta数据。
第四,读取当前设备下所有的ChunkMeta信息到内存。
那么,这里在实际的生产过程中我遇到了一个设备有几十万的工况数据采集,加载与当前查询无关的Chunk信息也是一种极大的性能消耗。那么如何解决呢?
未来解决上面的问题,提供极致的查询性能,我们需要优化Meta信息的利用,在0.10版本我们根据设备和工况信息构建一颗B+Tree。假设一个设备有150个Measurement采集,我们从0.8到0.10进行了meta信息优化。
首先是对Chunk信息进行细粒度的时间切片,如图的TimeSeriesmeta;
更重要的是,我们对 Measurement进行了更高一层的逻辑抽象,LEAF_MEASUREMENT节点,这样我们就可以构建一颗索引树。
这样的索引树,当我们查询某个设备的某个Measurement信息时候,比如查询s0,那么优化后的索引结构,我们不需要将设备下的所有的Measurement的Meta信息全部读取,我们只需要读取s0-s9的数据就可以了。那么,这里内容的理解需要有一点磁盘数据块管理和读取的知识背景,磁盘数据块管理和B+Tree的数据结构性感内容大家可以扫描二维码,查看更细节的内容剖析。
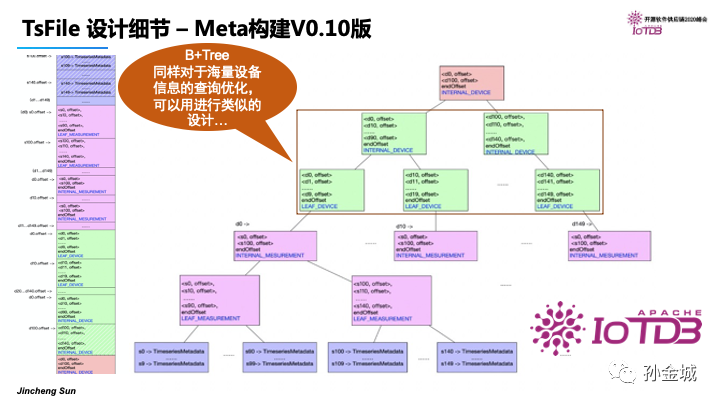
如果大家理解刚才对Measurement的中间层抽象优化的话,那么相信大家同样会秒懂,对于设备很多的情况下,也可以对设备的Meta信息进行一层INTERNAL_DEVICE节点抽象的原因了。
这样IoTDBv0.10对DEVICE和MESUREMENT进行了中间节点优化抽象,进而优化内存的利用/数据的解析和降低磁盘IO的成本,极大的提高查询性能。
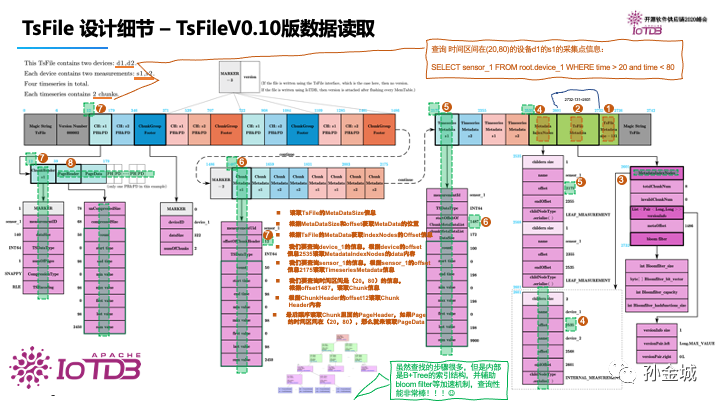
这个就是v0.10版本中完整的TsFile的数据结构。我们以一个具体的查询来完整的梳理一下查询逻辑:
假设我们要查询 时间区间在(20,80)的设备d1的s1的采集点信息:SELECT sensor_1 FROM root.device_1 WHERE time > 20 and time < 80
读取TsFile的MetaDataSize信息
根据MetaDataSize和offset获取MetaData的位置
根据TsFile的MetaData获取IndexNodes的Offset信息我们要查询device_1的信息,根据device的offset信息2535读取MetadataIndexNodes的data内容
我们要查询sensor_1的信息,根据sensor_1的offset信息2175读取TimeseriesMetadata信息
我们要查询时间区间是(20,80)的信息,根据offset1487,读取Chunk信息
根据ChunkHeader的offset12读取ChunkHeader内容
最后顺序读取Chunk里面的PageHeader,如果Page的时间区间在(20,80),那么就来读取PageData
虽然查找的步骤很多,但是内部是B+Tree的索引结构,并辅助bloom filter等加速机制,查询性能还是非常棒的!!!
那么其实IoTDB整体还是非常复杂的,内部细节很多,上面我们介绍的是Meta设计和读取过程细节,对于IoTDB在写上的设计也是很巧妙的,也有很多的细节需要和大家进行介绍。
会涉及到ChunkGourp/chunk/等部分的细致考虑,今天我们不进行展开,后续我会在公众中为大家细致剖析。
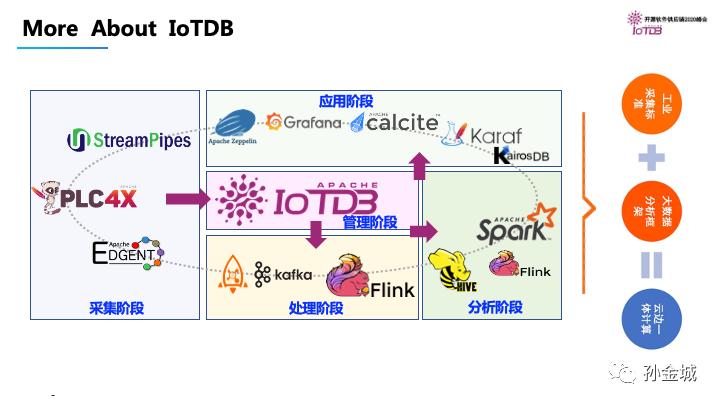
从细节跳出来我们在宏观上了解IoTDB的话,我们会发现IoTDB不仅在数据的读写上有优势,而且还对工业标准进行了集成,也更加注重和大数据生态的集成。非常适合企业构建云边端一体的存储计算体系平台。
好的,下面我们快速了解一下IoTDB的现状和未来规划。

IoTDB已经在2020年的9月份得到了最权威的开源社区的认可,成为了Apache 顶级项目。Apache 开源社区对项目的毕业控制非常严格,IoTDB成为顶级项目足以证明其优秀和潜力。

刚才我们也提到,ApacheIoTDB 非常注重工业领域标准集成,与Apache 顶级项目PLC4X有很好的生态集成和线下互动。

得到了多方的认可,包括工信部的认可和业界肯定,在2020年度也成为了开源中国,年度最受欢迎的开源项目。
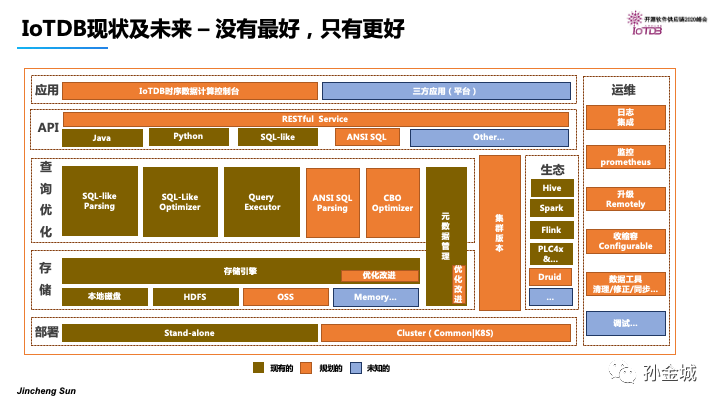
关于未来的规划,图中棕色部分是已经具备的功能,橙色部分是目前社区重点规划的部分。那么更多的功能规划和开发也欢迎在做的各位进行积极参与。J

好,接下来我们快速看一下IoTDB的现有投产应用案例。
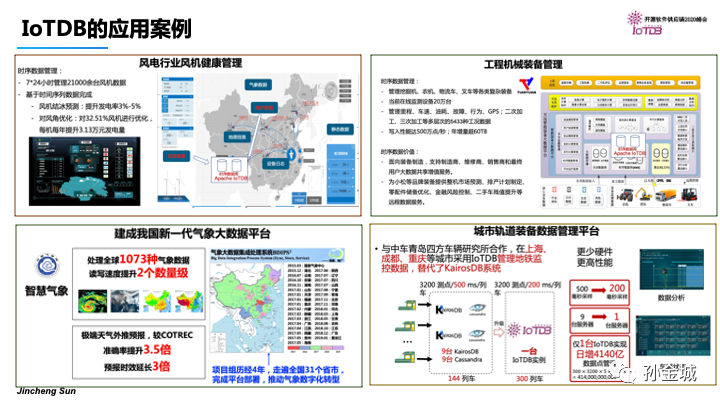
那么目前IoTDB已经投产与各种工业领域,包括风电行业,工程机械,气象大数据平台和城市轨道等项目中,其中在中车青岛四方车辆的合作项目中,一台IoTDB实例替换了老系统的10多条Cassandra实例。每天管理4000亿的数据点信息。
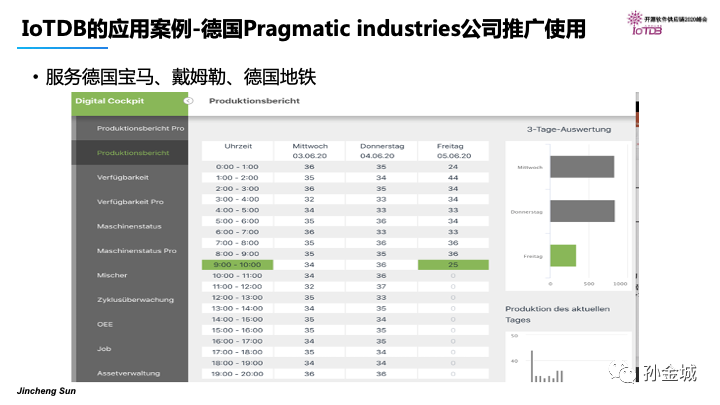
同时,IoTDB在德国和美国也有推广和应用,如图是IoTDB在德国的行业应用。

当然,还有更多的应用案例在进行中。。。

阿里招聘
时序数据库开发岗位
(P7/P8/P9)
(长期有效)
职位描述:
1. 精通Java/Scala编程
2. 精通常用数据结构和算法应用,具备良好的、精益求精的设计思维,每一个bit都是客户/技术价值。
3. 了解Hadoop/Flink/Spark等计算框架和熟悉HBase/LevelDB/RocksDB等主流NoSQL数据库,深入理解其实现原理和架构优势劣势;
4. 具备分布式系统的设计和应用的经历,能对分布式常用技术进行应用和改进者优先;
5. 有开源社区贡献,并成为Flink/Spark/Druid/OpenTSDB/InfluxDB/IoTDB等社区的Committer/PMC者优先;
6. 要具备良好的团队协作能力,良好的沟通表达能力,和对正确事情持之以恒的韧性和耐力。
来!让我看到你的简历,因为成就你的不仅仅是能力,更是雷厉风行的执行力!