
长链接转短链的那些难事!!!
点击上方蓝色“架构师修行之路”,选择“设为星标”
学最好的别人,做最好的我们
短网址的长度
短网址的长度该设计为多少呢?当前互联网上的网页总数大概是 45亿(参考 http://www.worldwidewebsize.com),超过了
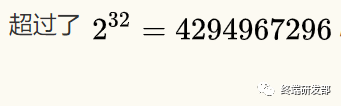
,那么用一个64位整数足够了。
一个64位整数如何转化为字符串呢?,假设我们只是用大小写字母加数字,那么可以看做是62进制数,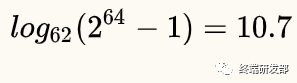 ,即字符串最长11就足够了。
,即字符串最长11就足够了。
实际生产中,还可以再短一点,比如新浪微博采用的长度就是7,因为 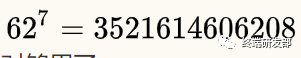 ,这个量级远远超过互联网上的URL总数了,绝对够用了。
,这个量级远远超过互联网上的URL总数了,绝对够用了。
现代的web服务器(例如Apache, Nginx)大部分都区分URL里的大小写了,所以用大小写字母来区分不同的URL是没问题的。
因此,正确答案:长度不超过7的字符串,由大小写字母加数字共62个字母组成
一对一还是一对多映射?
一个长网址,对应一个短网址,还是可以对应多个短网址?这也是个重大选择问题
一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个7位长度的短网址作为唯一ID,这个ID下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP头部的 User Agent等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
正确答案:一对多
如何计算短网址
现在我们设定了短网址是一个长度为7的字符串,如何计算得到这个短网址呢?
最容易想到的办法是哈希,先hash得到一个64位整数,将它转化为62进制整,截取低7位即可。但是哈希算法会有冲突,如何处理冲突呢,又是一个麻烦。这个方法只是转移了矛盾,没有解决矛盾,抛弃。
MySQL数据库有一个自增ID,能不能借鉴这个呢?每来一个长网址,就给它发一个号码,这个号码不断的自增。这个方法跟哈希相比,好处是没有冲突,不用考虑处理冲突的问题。如何实现单台的发号服务器呢?可以用一台MySQL服务器来做(一定要用 REPLACE INTO,不要存储所有ID),也可用一台Redis服务器(用INCR),一行代码也不用写;也可以自己写一个RESTful API,代码也很简单,就不赘述了。
单台发号器有什么缺点呢?它是一个单点故障(SPOF, Single Point Of Failure),也会成为性能瓶颈(其实,如果你的QPS能大到压垮这台MySQL,那说明你的短网址服务很成功,可以考虑上市了:D),所以它适合中小型企业,对于超大型企业(以及在面试显得追求高大上),我们还是要继续思考更好的方案,请接着往下看。
下面开始讲如何打造多台机器组成的分布式发号器。
使用UUID算法或者MongoDB产生的ObjectID。其实MongoDB的ObjectID也算是一种UUID,这类算法,每台机器可以独立工作,天然是分布式的,但是这类算法产生的ID通常都很长,那短网址服务还有什么意义呢?所以这个方法不行。
多台MySQL服务器。前面讲了单台MySQL作为发号服务器,那么自然可以扩展一下,比如用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,一次类推。前面用一个 round-robin load balancer 挡着,每来一个长网址请求,由 round-robin balancer 随机地将请求发给10台MySQL中的任意一个,然后返回一个ID。Flickr用的就是这个方案,仅仅使用了两台MySQL服务器。这个方法仅有的一个缺点是,ID是连续的,容易被爬虫抓数据,爬虫基本不用写代码,顺着ID一个一个发请求就是了,太方便了(手动斜眼)。
分布式ID生成器(Distributed Id Generator)。分布式的产生唯一的ID,比如 Twitter 有个成熟的开源项目,就是专门做这个的,Twitter Snowflake 。Snowflake的核心算法如下:
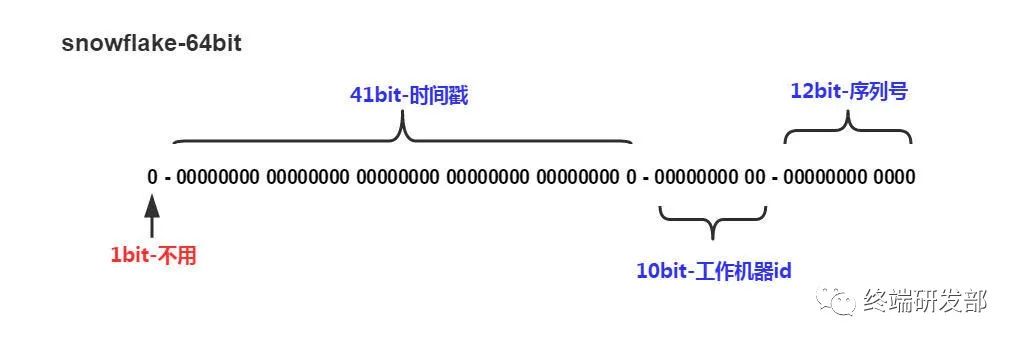
最高位不用,最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Instagram用了类似的方案,41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器),最低10位表示自增ID,怎么样,跟Snowflake的设计非常类似吧。这个方案用一个PostgreSQL集群代替了Twitter Snowflake 集群,优点是利用了现成的PostgreSQL,容易懂,维护方便。
因此,正确答案:分布式发号器(Distributed ID Generator),Flick, Twitter Snowflake 和 Instagram的方案都是不错的选择。
如何存储
如果存储短网址和长网址的对应关系?以短网址为 primary key, 长网址为value, 可以用传统的关系数据库存起来,例如MySQL, PostgreSQL,也可以用任意一个分布式KV数据库,例如Redis, LevelDB。
如果你手痒想要手工设计这个存储,那就是另一个话题了,你需要完整地造一个KV存储引擎轮子。当前流行的KV存储引擎有LevelDB何RockDB,去读它们的源码吧。
301还是302重定向
这也是一个有意思的问题。这个问题主要是考察你对301和302的理解,以及浏览器缓存机制的理解。
301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。但是如果用了301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以,正确答案是302重定向。
可以抓包看看新浪微博的短网址是怎么做的,使用 Chrome 浏览器,访问这个URL http://t.cn/RX2VxjI,是我事先发微博自动生成的短网址。来抓包看看返回的结果是啥,
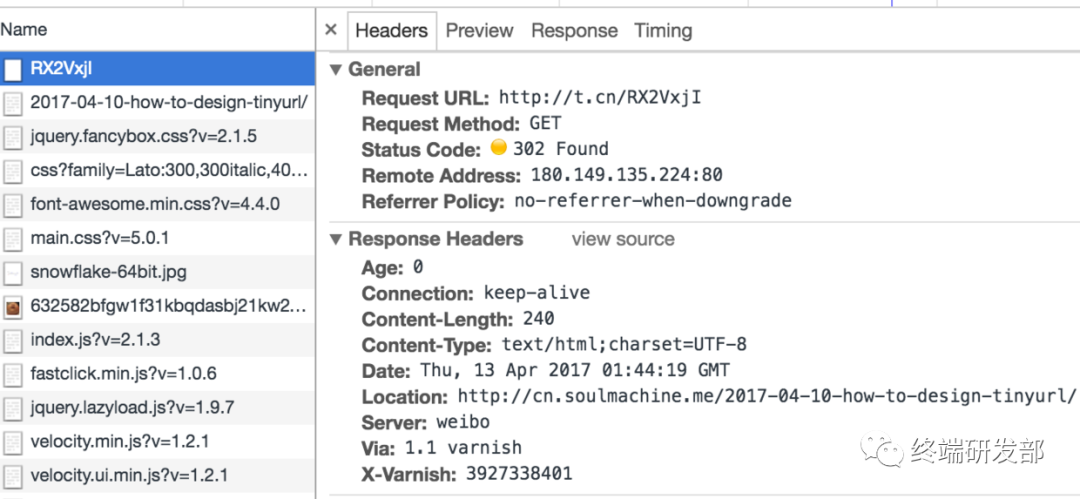
可见新浪微博用的就是302临时重定向。
预防攻击
如果一些别有用心的黑客,短时间内向TinyURL服务器发送大量的请求,会迅速耗光ID,怎么办呢?
首先,限制IP的单日请求总数,超过阈值则直接拒绝服务。
光限制IP的请求数还不够,因为黑客一般手里有上百万台肉鸡的,IP地址大大的有,所以光限制IP作用不大。
可以用一台Redis作为缓存服务器,存储的不是 ID->长网址,而是 长网址->ID,仅存储一天以内的数据,用LRU机制进行淘汰。这样,如果黑客大量发同一个长网址过来,直接从缓存服务器里返回短网址即可,他就无法耗光我们的ID了。
转载 http://cn.soulmachine.me/2017-04-10-how-to-design-tinyurl/


程序员的妈妈居然是产品经理,她会如何逼你结婚?
