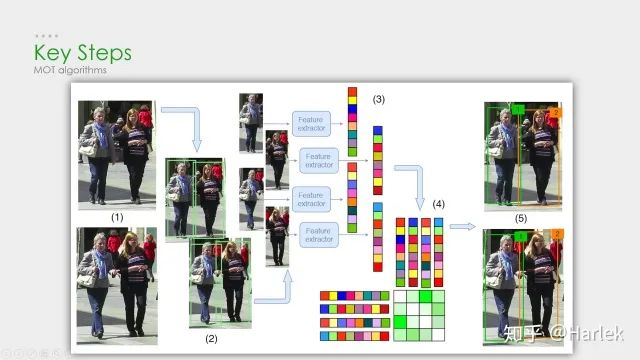
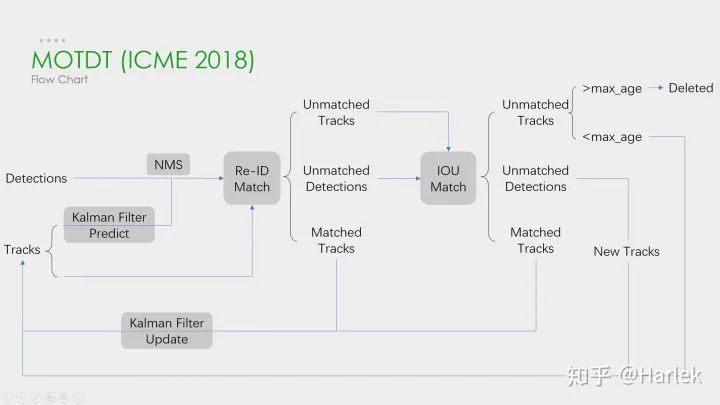
这是刚才列举的第一篇论文(MOTDT)的流程图,大概和DeepSORT差不多。这个图画的比较简单,其实在NMS之前有个基于SqueezeNet的区域选择网络R-FCN和轨迹评分的机制。这两个东西的目的就是为了产生一个统一检测框和预测框的标准置信度,作为NMS的输入。这篇文章的翻译在《Real-Time Multiple People Tracking With Deeply Learned Candidate Selection And Person Re-ID》论文翻译
最后用多目标追踪未来的一些思考作为结尾,这句话是最近的一篇关于多目标追踪的综述里的。它在最后提出对未来的方向里有这样一句话,用深度学习来指导关联问题。其实现在基于检测的多目标追踪都是检测模块用深度学习,Re-ID模块用深度学习,而最核心的数据关联模块要用深度学习来解决是很困难的。现在有一些尝试是用RNN,但速度慢、效果不好,需要走的路都还很长。我个人觉得短期内要解决实际问题,还是从Re-ID的方面下手思考怎样提取更有效的特征会更靠谱,用深度学习的方法来处理数据关联不是短时间能解决的。参考文献:[1] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468. IEEE, 2016.[2] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep associationmetric. In2017 IEEE International Conference on Image Processing (ICIP), pages 3645–3649. IEEE, 2017.[3] Chen Long, Ai Haizhou, Zhuang Zijie, and Shang Chong. Real-time multiple people tracking with deeplylearned candidate selection and person re-identification. InICME, 2018.[4] Zhongdao Wang, Liang Zheng, Yixuan Liu, Shengjin Wang. Towards Real-Time Multi-Object Tracking. arXiv preprint arXiv:1909.12605[5] Gioele Ciaparrone, Francisco Luque Sánchez, Siham Tabik, Luigi Troiano, Roberto Tagliaferri, Francisco Herrera. Deep Learning in Video Multi-Object Tracking: A Survey. arXiv preprint arXiv:1907.12740