首先,论文将SMCA与基础的DETR模型进行了比较。实验结果如表1所示,通过简单地替换DETR中现有的共同注意力机制并使用多尺度特征,SMCA将DETR的收敛速度提升了接近10倍,并取得了更高的性能。表1 与DETR的对比其次,论文在下游任务,如全景分割上也对SMCA机制进行了测试。基于MaskFormer[4] ResNet50模型,在将网络中的共同注意力机制替换为SMCA后(未使用多尺度特征融合),论文中的方法仅使用1/6的训练时间即取得了和原模型相当的结果。表2 SMCA在Panoptic Segmentation任务上的结果此外,为了进一步验证本文所提出的共同注意力机制的有效性,论文对解码器中的注意力权重以及预测的物体位置进行了可视化。如图3所示,相较于原始的DETR,通过在多头注意力模型的每一分支中对位置和尺寸分别进行预测,SMCA可以产生更加准确和紧凑的注意力权重分布,加速了对于物体特征的提取过程。图3 SMCA中共同注意力机制的可视化最后,如表3所示,与其他同类方法相比,SMCA可以使用类似或更少的训练时间取得相当的检测结果,证明了本文所提出方法的有效性。表3 与其他模型的比较图4 可视化结果[1] N. Carion, F. Massa, G. Synnaeve, N.Usunier, A. Kirillov, and S. Zagoruyko, “End-to-End Object Detection withTransformers,” in In European Conference on Computer Vision, 2020, pp.213–229.[2] S.Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time objectdetection with region proposal networks,” in Advances in Neural InformationProcessing Systems, 2015, vol. 2015-January.[3] T.Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Featurepyramid networks for object detection,” in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2017, vol.2017-Janua, pp. 936–944.[4] B.Cheng, A. G. Schwing, and A. Kirillov, “Per-Pixel Classification is Not All YouNeed for Semantic Segmentation,” arXiv, 2021.如需了解更多详情,可访问本文第一作者,上海人工智能实验室青年科学家高鹏的个人主页 https://gaopengcuhk.github.io/




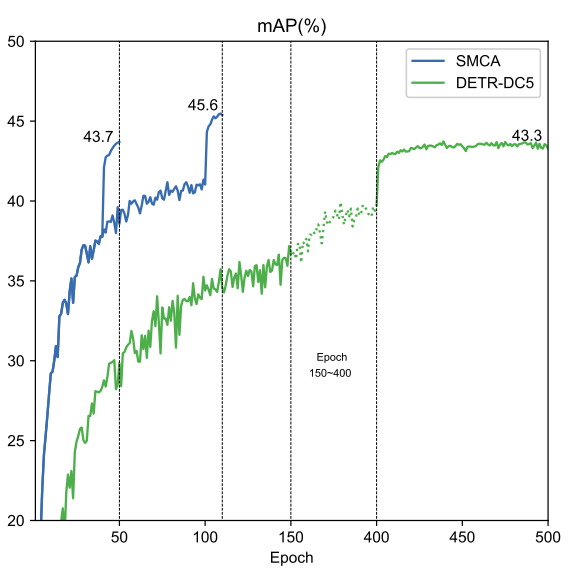
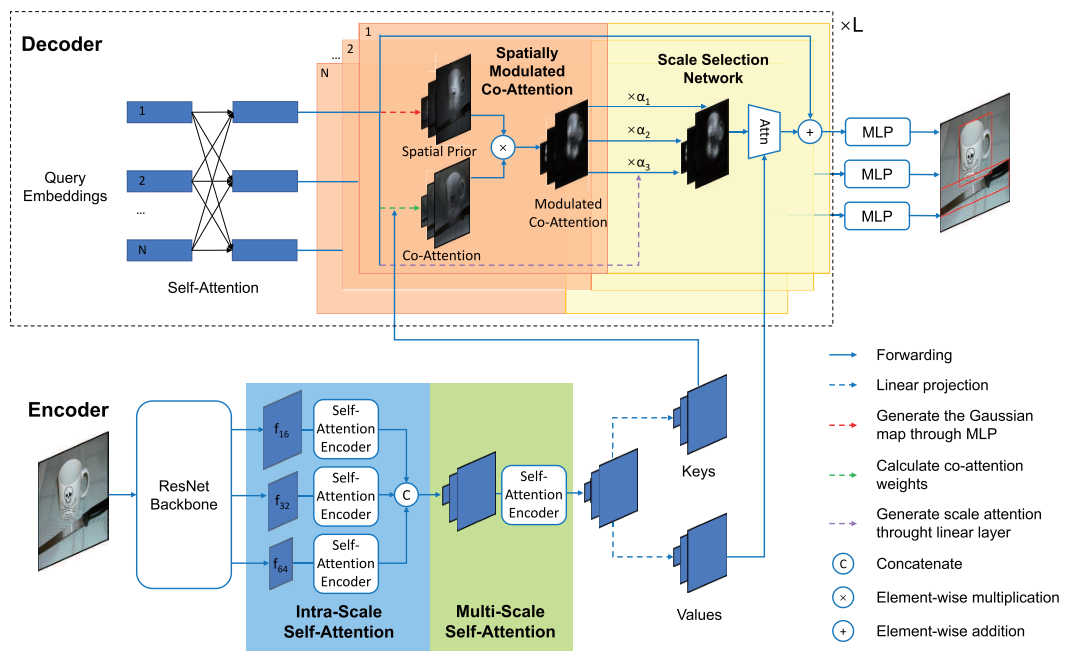 图2 SMCA的结构示意图
图2 SMCA的结构示意图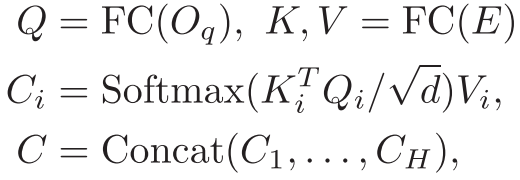
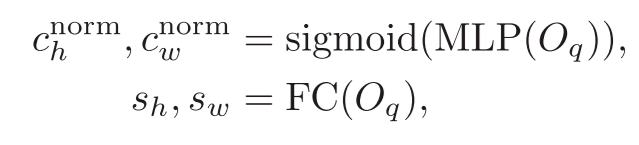
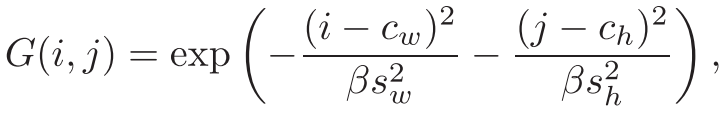
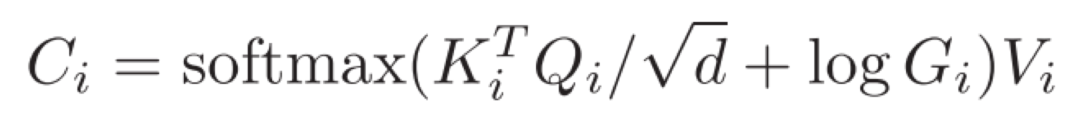

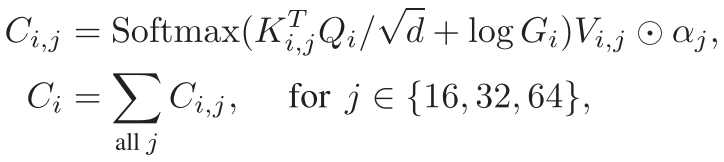
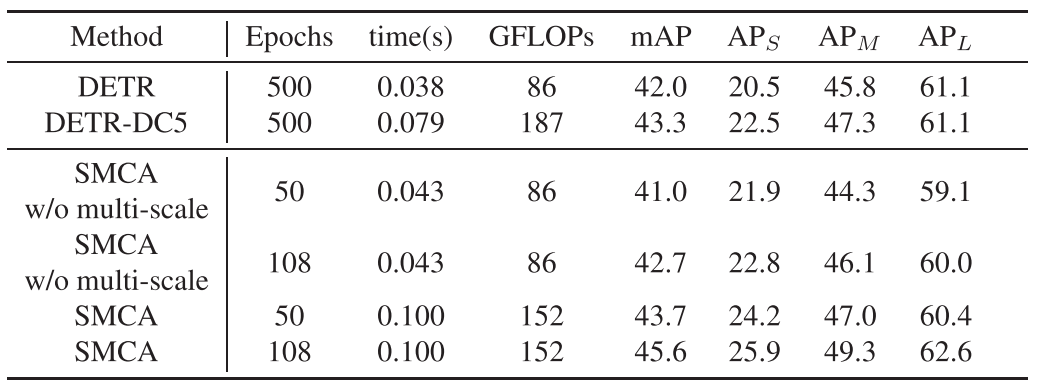 表1 与DETR的对比
表1 与DETR的对比 表2 SMCA在Panoptic Segmentation任务上的结果
表2 SMCA在Panoptic Segmentation任务上的结果 图3 SMCA中共同注意力机制的可视化
图3 SMCA中共同注意力机制的可视化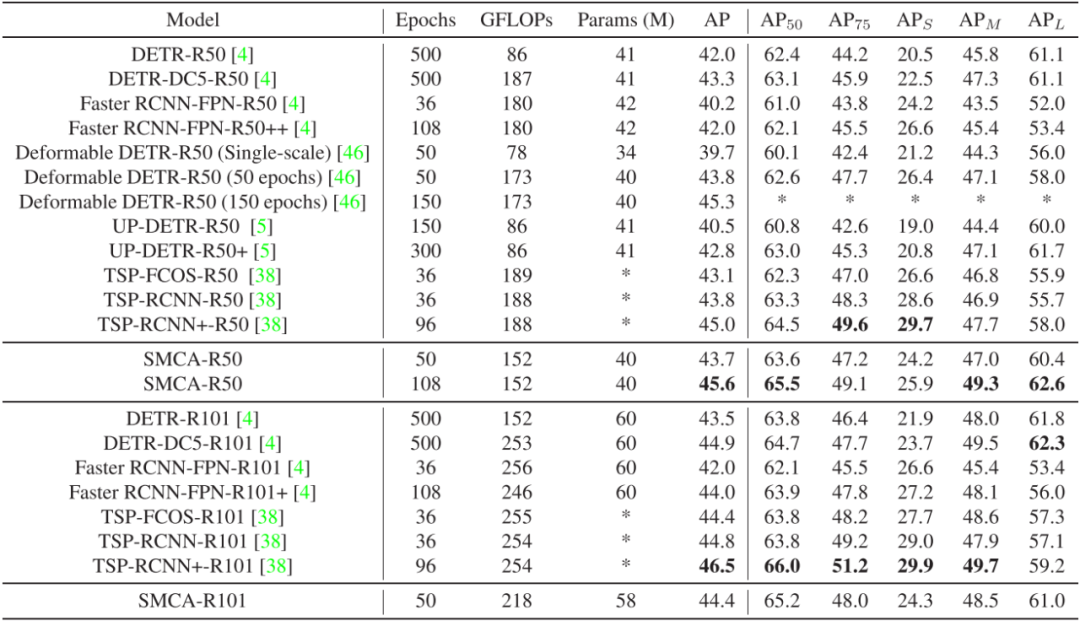 表3 与其他模型的比较
表3 与其他模型的比较
