
实时监控:基于流计算 Oceanus ( Flink ) 实现系统和应用级实时监控
一、解决方案描述
(一)概述
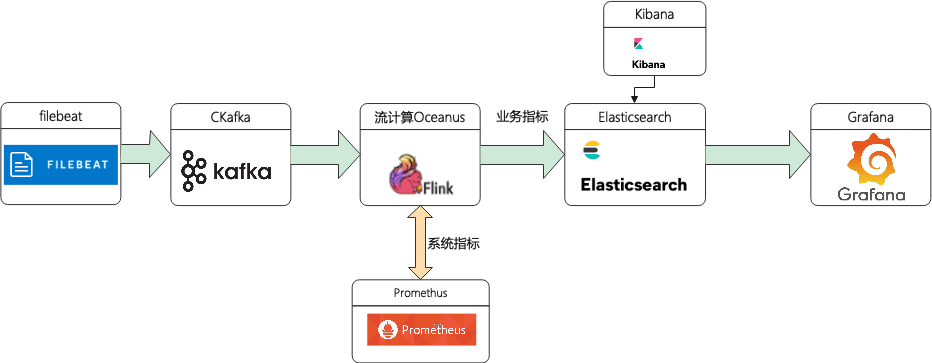
(二)方案架构
二、前置准备
(一)创建私有网络 VPC
(二)创建 CKafka 实例
topic-app-info (三)创建流计算 Oceanus 集群
(四)创建 Elasticsearch 实例
(五)创建云监控 Prometheus 实例
为了展示自定义系统指标,需购买 Promethus 服务。只需要自定业务指标的同学可以省略此步骤。
进入云监控控制台,点击左侧 【Prometheus 监控】,新建 Promethus 实例,具体的步骤请参考帮助文档 (https://cloud.tencent.com/document/product/1416/55982)。
(六)创建独立 Grafana 资源
(七)安装配置 Filebeat
# 监控日志文件配置- type: logenabled: truepaths:- /tmp/test.log#- c:\programdata\elasticsearch\logs\*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的IP地址+端口topic: 'topic-app-info' # 请填写实际的topic
注:示例选用2.4.1的 CKafka 版本,这里配置 version: 2.0.0。版本对应不上可能出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): dropping invalid message”错误
三、方案实现
接下来通过案例介绍如何通过流计算 Oceanus 实现个性化监控。
(一)Filebeat 采集数据
1、进入到 Filebeat 根目录下,并启动 Filebeat 进行数据采集。示例中采集了 top 命令中显示的 CPU、内存等信息,也可以采集 jar 应用的日志、JVM 使用情况、监听端口等,详情参考 Filebeat 官网
(https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html)。
# filebeat启动
./filebeat -e -c filebeat.yml
# 监控系统信息写入test.log文件
top -d 10 >>/tmp/test.log 2、进入 CKafka 页面,点击左侧【消息查询】,查询对应 topic 消息,验证是否采集到数据。
{"@timestamp": "2021-08-30T10:22:52.888Z","@metadata": {"beat": "filebeat","type": "_doc","version": "7.14.0"},"input": {"type": "log"},"host": {"ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"],"mac": ["xx:xx:xx:xx:xx:xx"],"hostname": "xx.xx.xx.xx","architecture": "x86_64","os": {"type": "linux","platform": "centos","version": "7(Core)","family": "redhat","name": "CentOSLinux","kernel": "3.10.0-1062.9.1.el7.x86_64","codename": "Core"},"id": "0ea734564f9a4e2881b866b82d679dfc","name": "xx.xx.xx.xx","containerized": false},"agent": {"name": "xx.xx.xx.xx","type": "filebeat","version": "7.14.0","hostname": "xx.xx.xx.xx","ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9","id": "6b23463c-0654-4f8b-83a9-84ec75721311"},"ecs": {"version": "1.10.0"},"log": {"offset": 2449931,"file": {"path": "/tmp/test.log"}},"message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
1、定义 Source
CREATE TABLE DataInput (`@timestamp` VARCHAR,`host` ROW<id VARCHAR,ip ARRAY<VARCHAR>>,`log` ROW<`offset` INTEGER,file ROW<path VARCHAR>>,`message` VARCHAR) WITH ('connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector'topic' = 'topic-app-info', -- 替换为您要消费的 Topic'scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = '10.0.0.29:9092','properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID'format' = 'json','json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
CREATE TABLE es_output (`id` VARCHAR,`ip` ARRAY<VARCHAR>,`path` VARCHAR,`num` INTEGER,`message` VARCHAR,`createTime` VARCHAR) WITH ('connector.type' = 'elasticsearch','connector.version' = '6','connector.hosts' = 'http://10.0.0.175:9200','connector.index' = 'oceanus_test2','connector.document-type' = '_doc','connector.username' = 'elastic','connector.password' = 'yourpassword','update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null''format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
INSERT INTO es_outputSELECThost.id as `id`,host.ip as `ip`,log.file.path as `path`,log.`offset` as `num`,message,`@timestamp` as `createTime`from DataInput;
4、配置作业参数
flink-connector-elasticsearch6和flink-connector-kafka注: 根据实际版本选择
5、查询 ES 数据
curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{"query": { "match_all": {}},"size": 10}'
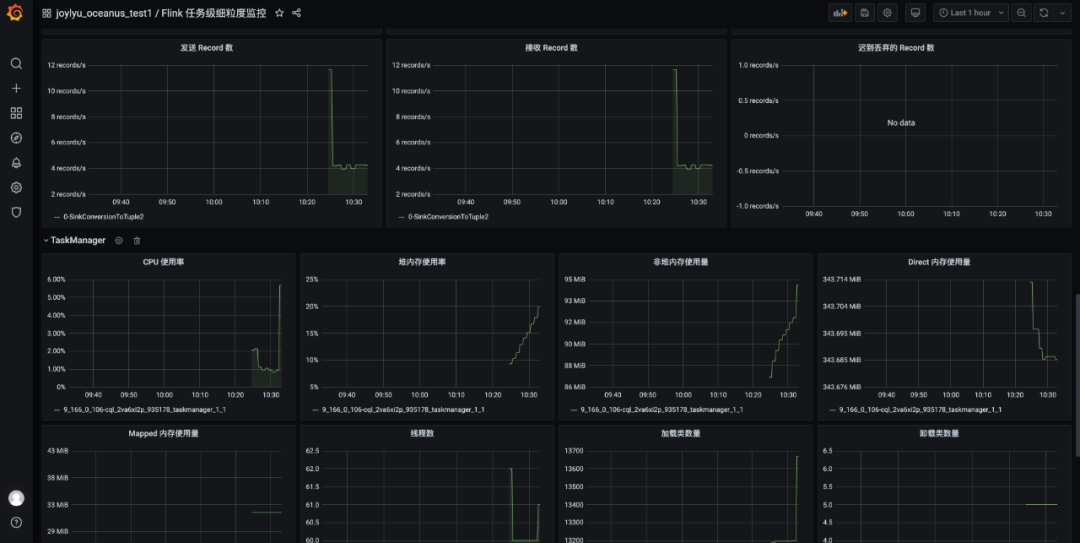
(三)系统指标监控
监控配置
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS

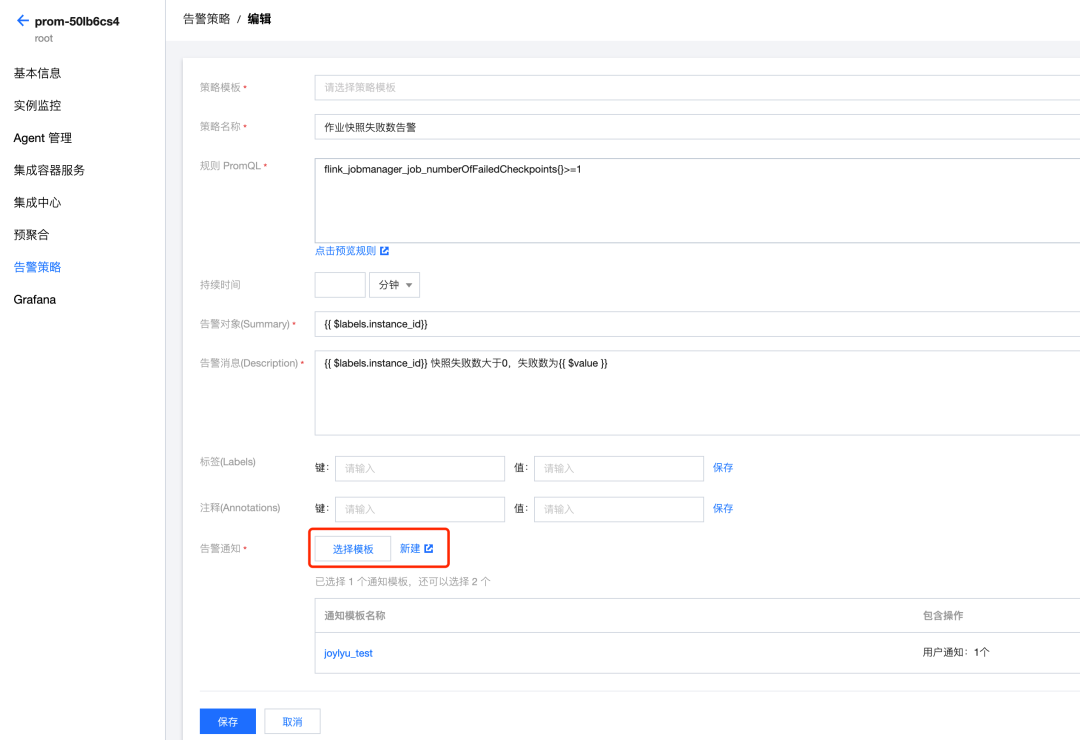
告警配置
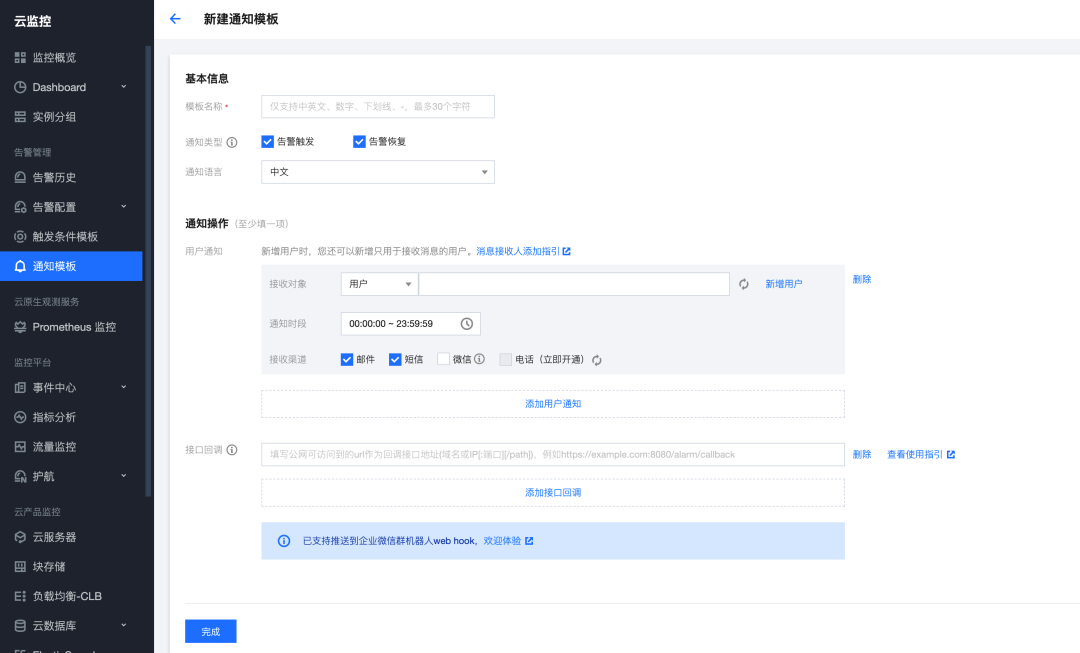
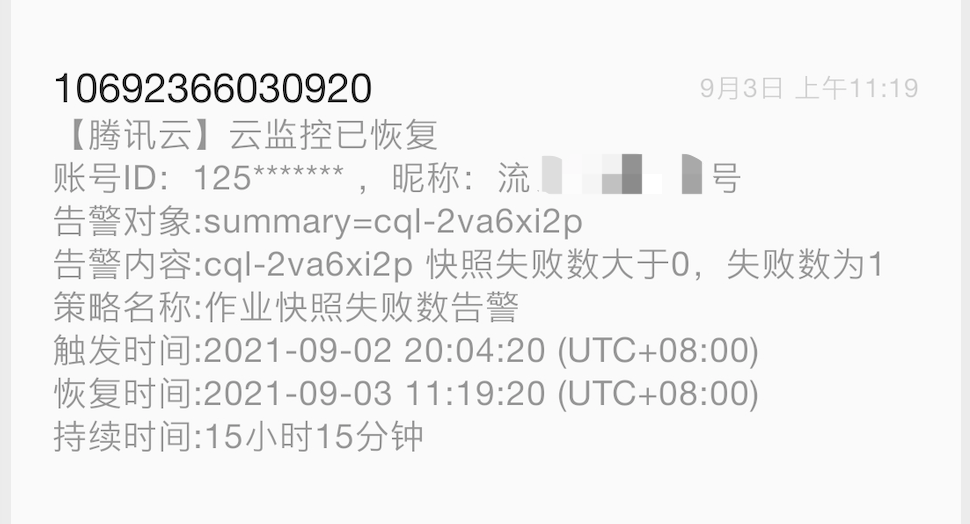
(四)业务指标监控
elasticsearch,填写相关 ES 实例信息,添加数据源。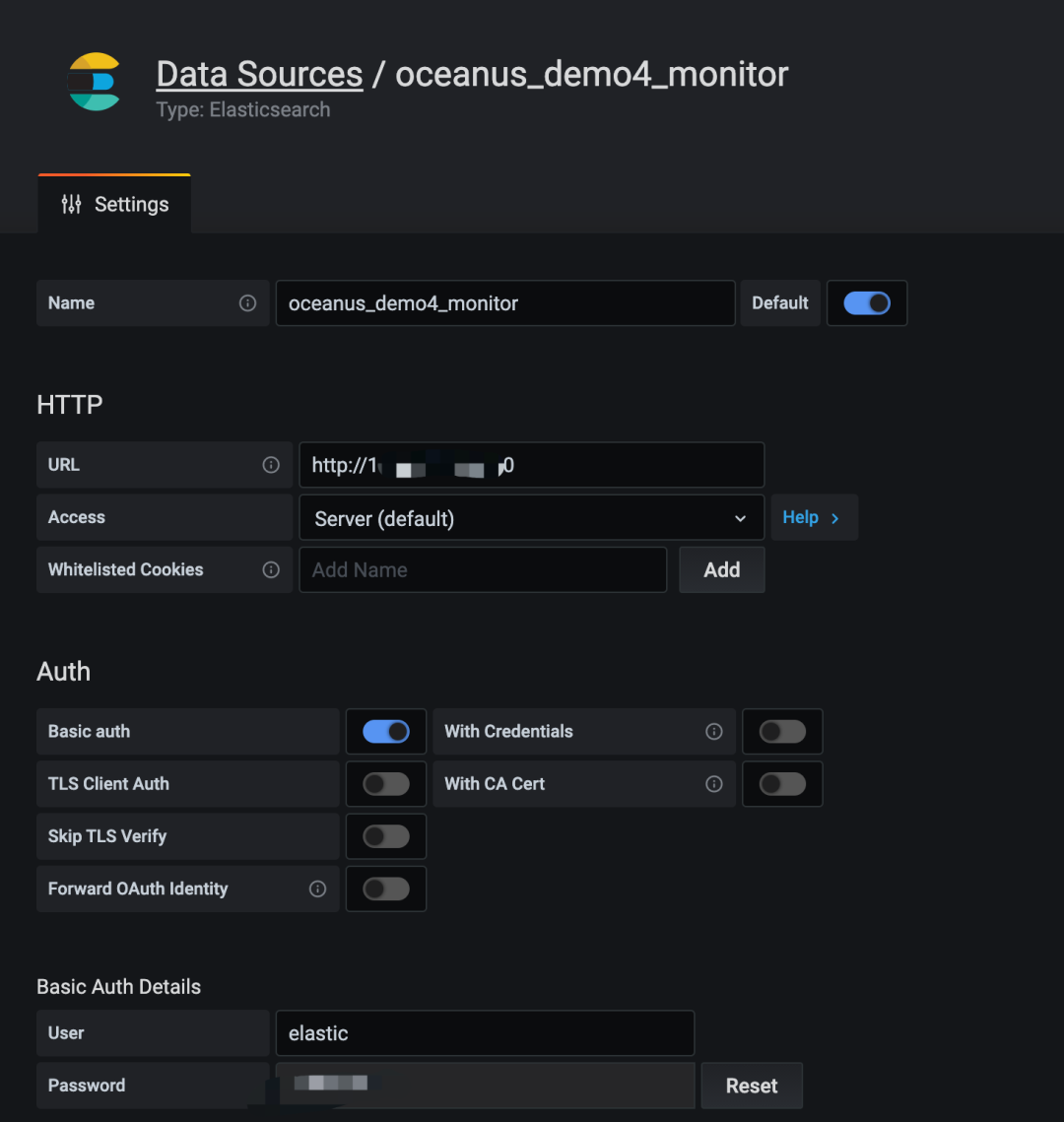
总数据量写入实时监控:对写入数据源的总数据量进行监控;数据来源实时监控:对来源于某个特定 log 的数据写入量进行监控;字段平均值监控:对某个字段的平均值进行监控;num字段最大值监控:对 num 字段的最大值进行监控;
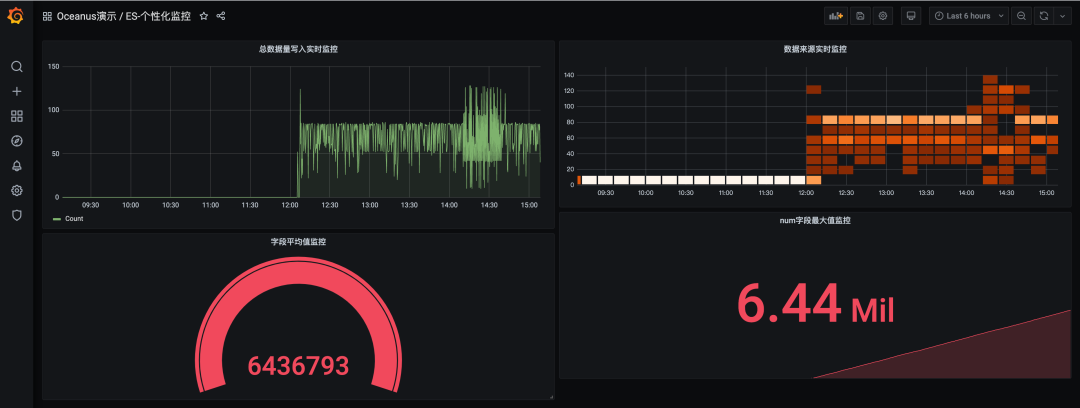
注:本处只做示例,无实际业务
四、总结
CKafka 的版本和开源版本 Kafka 并没有严格对应,方案中 CKafka2.4.1和开源 Filebeat-1.14.1版本能够调试成功。
云监控中的 Promethus 服务已经嵌入了 Grafana 监控服务。但不支持自定义数据源,该嵌入的 Grafana 只能接入 Promethus,需使用独立灰度发布的 Grafana 才能完成ES数据接入 Grafana。