掌握这些 Numpy、Pandas 方法,快速提升数据处理效率
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:数据STUDIO 作者:云朵君

Pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使python成为强大而高效的数据分析环境的重要因素之一。
NumPy
NumPy库是Python中用于科学计算的核心库。它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具。
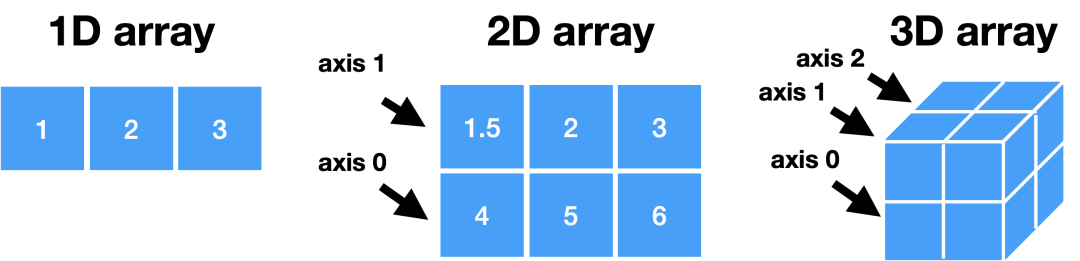
导入Numpy
import numpy as np
创建 Arrays
>>> a = np.array([1,2,3])
>>> b = np.array([(1.5,2,3), (4,5,6)], dtype = float)
>>> c = np.array([[(1.5,2,3), (4,5,6)], [(3,2,1), (4,5,6)]],dtype = float)
# 创建一个由0组成的数组
>>> np.zeros((3,4))
# 创建一个1的数组
>>> np.ones((2,3,4),dtype=np.int16)
# 创建一个等距值数组(步长值)
>>> d = np.arange(10,25,5)
# 创建一个等距值数组(样本数)
>>> np.linspace(0,2,9)
# 创建一个常量数组
>>> e = np.full((2,2),7)
# 创建一个2X2单位矩阵
>>> f = np.eye(2)
# 创建一个随机值的数组
>>> np.random.random((2,2))
# 创建一个空数组
>>> np.empty((3,2))
输入与输出
从磁盘上导入与存储
>>> np.save('my_array', a)
>>> np.savez('array.npz', a, b)
>>> np.load('my_array.npy')
导入与存储文本文件
>>> np.loadtxt("myfile.txt")
>>> np.genfromtxt("my_file.csv", delimiter=',')
>>> np.savetxt("myarray.txt", a, delimiter=" ")
数据类型
>>> np.int64 # 有符号64位整数类型
>>> np.float32 # 标准双精度浮点数
>>> np.complex # 由128个浮点数表示的复数
>>> np.bool # 布尔类型,存储TRUE和FALSE值
>>> np.object # Python对象类型
>>> np.string_ # 固定长度的字符串类型
>>> np.unicode_# 固定长度的unicode类型
查看数组
>>> a.shape # 阵列尺寸
>>> len(a) # 数组的长度
>>> b.ndim # 阵列维数
>>> e.size # 数组元素数
>>> b.dtype # 数组元素的数据类型
>>> b.dtype.name # 数据类型名称
>>> b.astype(int) # 将数组转换为不同类型
获取帮助
>>> np.info(np.ndarray.dtype)
Array 算术运算
>>> g = a - b # 减法
array([[-0.5, 0. , 0. ],
[-3. , -3. , -3. ]])
>>> np.subtract(a,b) # 减法
>>> b + a # 加法
array([[ 2.5, 4. , 6. ],
[ 5. , 7. , 9. ]])
>>> np.add(b,a) # 加法
>>> a / b # 除法
array([[ 0.66666667, 1. , 1. ],
0.25 , 0.4, 0.5])
>>> a * b # 乘法
array([[ 1.5, 4. , 9. ],
[ 4. , 10. , 18. ]])
>>> np.multiply(a,b) # 乘法
>>> np.divide(a,b) # 除法
>>> np.exp(b) # 求幂
>>> np.sqrt(b) # 平方根
>>> np.sin(a) # 输出一个数组的正弦值
>>> np.cos(b) # 输出一个数组的余弦值
>>> np.log(a) # 输出一个数组的自然对数
>>> e.dot(f) # 点积
array([[ 7., 7.], [ 7., 7.]])
比较大小
>>> a == b # 数组元素比较
array([[False, True, True],
[False, False, False]], dtype=bool)
>>> a < 2 # 数组元素比较
array([True, False, False], dtype=bool)
>>> np.array_equal(a, b) # 数组比较
统计函数
>>> a.sum() # 数组求和
>>> a.min() # 数组最小值
>>> b.max(axis=0) # 数组行最大值
>>> b.cumsum(axis=1) # 元素均值的累积和
>>> a.mean() # 中位数
>>> b.median() # 相关系数
>>> a.corrcoef() # 相关系数
>>> np.std(b) # 标准偏差
数组拷贝
>>> h = a.view() # 使用相同的数据创建数组的视图
>>> np.copy(a) # 创建数组的副本
>>> h = a.copy() # 创建数组的深层副本
数组排序
>>> a.sort() # 排序数组
>>> c.sort(axis=0) # 对数组横轴的元素进行排序
切片与索引
获取单个元素
>>> a[2] # 选择第二个索引处的元素
3
>>> b[1,2] # 选择第1行第2列的元素(相当于b[1][2])
1.5 2 3 6.0 456
获取子集
>>> a[0:2] # 选择索引0和1的项
array([1, 2])
>>> b[0:2,1] # 选择第1列中第0行和第1行中的项目
array([ 2., 5.])
>>> b[:1] # 选择第0行中的所有项目,等价于b[0:1,:]
array([[1.5, 2., 3.]])
>>> c[1,...] # 与[1,:,:]一样
array([[[3., 2., 1.],
[4., 5., 6.]]])
>>> a[ : :-1] # 逆转了数组
array([3, 2, 1])
布尔索引
>>> a[a<2] # 从小于2的a中选择元素
array([1])
花俏的索引
>>> b[[1, 0, 1, 0],[0, 1, 2, 0]] # 选择元素(1,0),(0,1),(1,2) 和 (0,0)
array([4.,2.,6.,1.5])
>>> b[[1, 0, 1, 0]][:,[0,1,2,0]] # 选择矩阵的行和列的子集
array([[4.,5.,6.,4.],
[1.5,2.,3.,1.5],
[4.,5.,6.,4.],
[1.5,2.,3.,1.5]])
数组操作
转置数组
>>> i = np.transpose(b) # 交换数组维度
>>> i.T
改变数组形状
>>> b.ravel() # 将数组压平
>>> g.reshape(3,-2) # 不会改变数据
添加和删除数组元素
>>> h.resize((2,6)) # 返回一个具有形状(2,6)的新数组
>>> np.append(h,g) # 向数组添加项
>>> np.insert(a, 1, 5) # 在数组中插入项
>>> np.delete(a,[1]) # 从数组中删除项
合并数组
>>> np.concatenate((a,d),axis=0)# 连接数组
array([ 1, 2, 3, 10, 15, 20])
>>> np.vstack((a,b)) # 垂直(行)堆叠阵列
array([[ 1. , 2. , 3. ],
[ 1.5, 2. , 3. ],
[ 4. , 5. , 6. ]])
>>> np.r_[e,f] # 垂直(行)堆叠阵列
>>> np.hstack((e,f)) # 水平(列)堆叠阵列
array([[ 7., 7., 1., 0.],
[ 7., 7., 0., 1.]])
>>> np.column_stack((a,d))# 创建堆叠的列阵列
array([[ 1, 10],
[ 2, 15],
[ 3, 20]])
>>> np.c_[a,d] # 创建堆叠的列阵列
分割数组
>>> np.hsplit(a,3) # 在第3个索引处水平分割数组
[array([1]),array([2]),array([3])]
>>> np.vsplit(c,2) # 在第二个索引处垂直分割数组
[array([[[ 1.5, 2. , 1. ],
[ 4. , 5. , 6. ]]]),
array([[[ 3., 2., 3.],
[ 4., 5., 6.]]])]
Pandas
Pandas库建立在NumPy上,并为Python编程语言提供了易于使用的数据结构和数据分析工具。
导入Pandas
>>> import pandas as pd
Series
>>> s = pd.Series([3,5,-7,9], index=['A', 'B', 'C', 'D'])

DataFrame
>>> data = {'Country': ['Belgium', 'India', 'Brazil'],
'Capital': ['Brussels', 'New Delhi', 'Brasília'],
'Population': [11190846, 1303171035, 207847528]}
>>> df = pd.DataFrame(data,
columns=['Country', 'Capital', 'Population'])
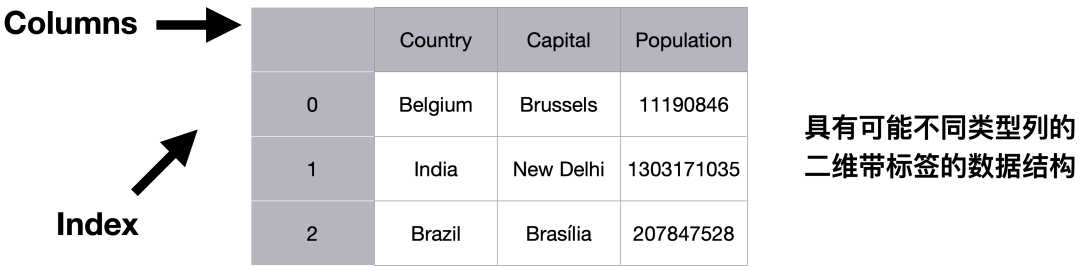
获取帮助信息
>>> help(pd.Series.loc)
切片与索引
获取元素
>>> s['b'] # 获取一个元素
-5
>>> df[1:] # 获取DataFrame子表
Country Capital Population
1 India New Delhi 1303171035
2 Brazil Brasília 207847528
布尔索引
# 通过位置
>>> df.iloc[[0],[0]] # 按行和列选择单个值
'Belgium'
>>> df.iat([0],[0])
'Belgium'
# 通过标签
>>> df.loc[[0], ['Country']] # 通过行和列标签选择单个值
'Belgium'
>>> df.at([0], ['Country'])
'Belgium'
# 通过标签或位置
>>> df.ix[2] # 选择行子集中的单行
Country Brazil
Capital Brasília
Population 207847528
>>> df.ix[:,'Capital'] # 选择列子集中的单列
0 Brussels
1 New Delhi
2 Brasília
>>> df.ix[1,'Capital'] # 选择行和列
'New Delhi'
# 布尔索引
>>> s[~(s > 1)] # 选择Series s的值不大于1的子集
>>> s[(s < -1) | (s > 2)] # 选择Seriess的值是<-1或>2 的子集
>>> df[df['Population']>1200000000] # 使用过滤器来调整数据框
# 设置
>>> s['a'] = 6 # 将Series s的索引a设为6
Dropping
>>> s.drop(['a', 'c']) # 从行删除值 (axis=0)
>>> df.drop('Country', axis=1) # 从列删除值
Sort & Rank
>>> df.sort_index() # 按轴上的标签排序
>>> df.sort_values(by='Country') # 按轴上的值排序
>>> df.rank()
检索Series / DataFrame上的信息
基础信息
>>> df.shape # (行、列)
>>> df.index # 描述指数
>>> df.columns # 描述DataFrame列
>>> df.info() # DataFrame信息
>>> df.count() # 非空值的个数
统计信息
>>> df.sum() # 值的总和
>>> df.cumsum() # 值的累积和
>>> df.min()/df.max() # 最小/最大值
>>> df.idxmin()/df.idxmax() # 最小/最大索引值
>>> df.describe()# 摘要统计信息
>>> df.mean() # 值的意思
>>> df.median() # 中位数的值
Apply 函数
>>> f = lambda x: x*2
>>> df.apply(f) # Apply函数
>>> df.applymap(f) # Apply每个元素
数据一致性
内部数据一致
在不重叠的索引中引入NA值
>>> s3 = pd.Series([7, -2, 3], index=['a', 'c', 'd'])
>>> s + s3
a 10.0
b NaN
c 5.0
d 7.0
填充方法的算术运算
你也可以在fill方法的帮助做内部数据一致
>>> s.add(s3, fill_value=0)
a 10.0
b -5.0
c 5.0
d 7.0
>>> s.sub(s3, fill_value=2)
>>> s.div(s3, fill_value=4)
>>> s.mul(s3, fill_value=3)
输入与输出
读取与写入到CSV
>>> pd.read_csv('file.csv', header=None, nrows=5)
>>> df.to_csv('myDataFrame.csv')
读取与写入到Excel
>>> pd.read_excel('file.xlsx')
>>> pd.to_excel('dir/myDataFrame.xlsx', sheet_name='Sheet1')
# 从同一个文件中读取多个工作表
>>> xlsx = pd.ExcelFile('file.xls')
>>> df = pd.read_excel(xlsx, 'Sheet1')
读取与写入到SQL 查询或数据库表中
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:')
>>> pd.read_sql("SELECT * FROM my_table;", engine)
>>> pd.read_sql_table('my_table', engine)
>>> pd.read_sql_query("SELECT * FROM my_table;", engine)
>>> pd.to_sql('myDf', engine)
read_sql()是read_sql_table()和read_sql_query()到一个便捷的封装。
数据透视Pivot
# 将行展开成列
>>> df3= df2.pivot(index='Date',
columns='Type',
values='Value')
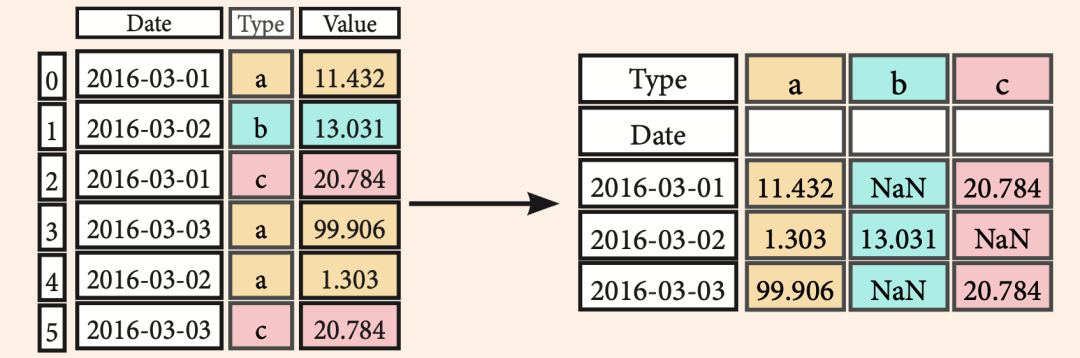
数据透视表Pivot_table
# 将行展开成列
>>> df4 = pd.pivot_table(df2,
values='Value',
index='Date',
columns=['Type'])
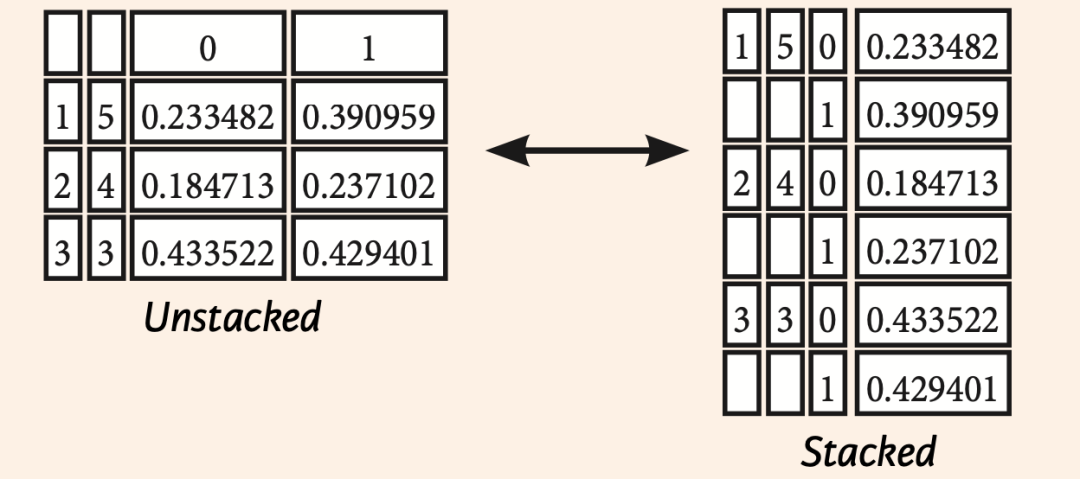
堆叠 stack/unstack
stack和unstack是python进行层次化索引的重要操作。
Stack: 将数据的列索引转换为行索引(列索引可以简单理解为列名) Unstack: 将数据的行索引转换为列索引
>>> stacked = df5.stack()
>>> stacked.unstack()
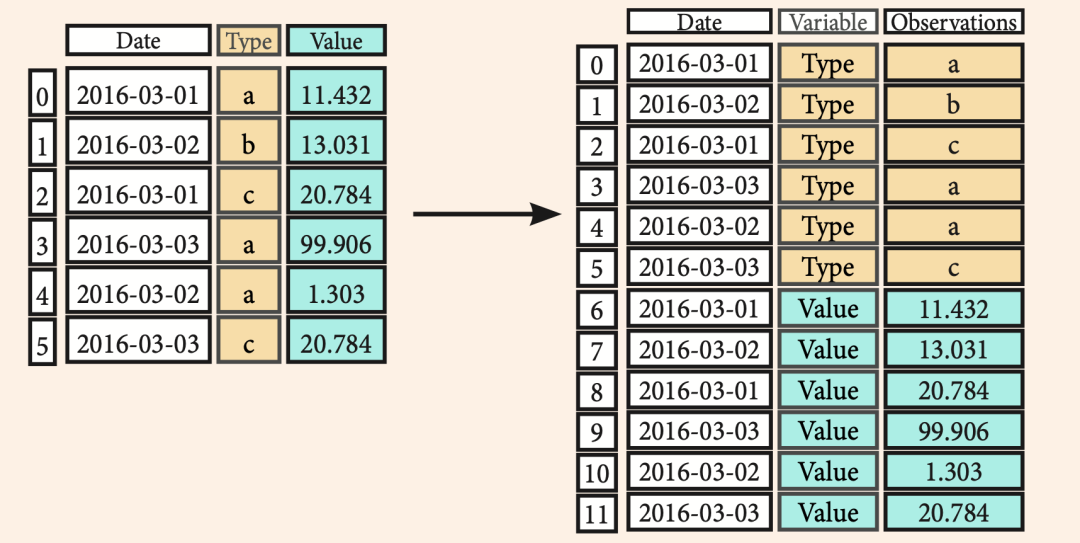
pandas.melt(frame,
id_vars=None,
value_vars=None,
var_name=None,
value_name='value',
col_level=None)
frame:
要处理的数据集。id_vars:
不需要被转换的列名。value_vars:
需要转换的列名,如果剩下的列全部都要转换,就不用写了。var_name和value_name:
是自定义设置对应的列名。col_level :
如果列是MultiIndex,则使用此级别。
宽数据--->>长数据,有点像用excel做透视跟逆透视的过程。
>>> pd.melt(df2,
id_vars=["Date"],
value_vars=["Type", "Value"],
value_name="Observations")
迭代
# (Column-index, Series) 对
>>> df.iteritems()
# (Row-index, Series) 对
>>> df.iterrows()
高级索引
# 按条件选择
>>> df3.loc[:,(df3>1).any()] # 选择只要有变量大于1的列
>>> df3.loc[:,(df3>1).all()] # 选择所有变量大于1的列
>>> df3.loc[:,df3.isnull().any()] # 选择带NaN的列
>>> df3.loc[:,df3.notnull().all()] # 选择不带NaN的列
# 用isin索引选择
>>> df[(df.Country.isin(df2.Type))] # 找到相同的元素
>>> df3.filter(items=["a","b"]) # 过滤值
>>> df.select(lambda x: not x%5) # 选择特定的元素
# Where
>>> s.where(s > 0) # 满足条件的子集的数据
# Query
>>> df6.query('second > first') # 查询DataFrame
设置与重置索引
>>> df.set_index('Country') # 设置索引
>>> df4 = df.reset_index() # 重置索引
# DataFrame重命名
>>> df = df.rename(index=str,columns={"Country":"cntry",
"Capital":"cptl",
"Population":"ppltn"})
重建索引
>>> s2 = s.reindex(['a','c','d','e','b'])
向前填充
>> df.reindex(range(4),
method='ffill')
Country Capital Population
0 Belgium Brussels 11190846
1 India New Delhi 1303171035
2 Brazil Brasília 207847528
3 Brazil Brasília 207847528
向后填充
>>> s3 = s.reindex(range(5),
method='ffill')
0 3
1 3
2 3
3 3
4 3
多重索引
>>> arrays = [np.array([1,2,3]),
np.array([5,4,3])]
>>> df5 = pd.DataFrame(np.random.rand(3, 2), index=arrays)
>>> tuples = list(zip(*arrays))
>>> index = pd.MultiIndex.from_tuples(tuples,
names=['first', 'second'])
>>> df6 = pd.DataFrame(np.random.rand(3, 2), index=index)
>>> df2.set_index(["Date", "Type"])
数据去重
>>> s3.unique() # 返回唯一的值
>>> df2.duplicated('Type') # 检查特定列重复的
>>> df2.drop_duplicates('Type',
keep='last') # 去重
>>> df.index.duplicated() # 检查索引重复
数据聚合
groupby
>>> df2.groupby(by=['Date','Type']).mean()
>>> df4.groupby(level=0).sum()
>>> df4.groupby(level=0).agg({'a':lambda x:sum(x)/len(x),
'b': np.sum})
转换 Transformation
transform⽅法,它与apply很像,但是对使⽤的函数有⼀定限制:
它可以产⽣向分组形状⼴播标量值 它可以产⽣⼀个和输⼊组形状相同的对象 它不能修改输⼊
>>> customSum = lambda x: (x+x%2)
>>> df4.groupby(level=0).transform(customSum)
缺失值处理
>>> df.dropna() # 删除缺失值
>>> df3.fillna(df3.mean())# 用特定的值填充NaN值
>>> df2.replace("a", "f") # 使用其他值替换缺失值
数据合并
Merge
>>> pd.merge(data1,
data2,
how='left',
on='X1')

>>> pd.merge(data1,
data2,
how='right',
on='X1')

>>> pd.merge(data1,
data2,
how='inner',
on='X1')

>>> pd.merge(data1,
data2,
how='outer',
on='X1')

Join
join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame。
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left。
>>> data1.join(data2, how='right')
Concatenate
# 垂直拼接
>>> s.append(s2)
# 水平或垂直拼接
>>> pd.concat([s,s2],axis=1, keys=['One','Two'])
>>> pd.concat([data1, data2], axis=1, join='inner')
日期
>>> df2['Date']= pd.to_datetime(df2['Date'])
>>> df2['Date']= pd.date_range('2000-1-1',
freq='M')
>>> dates = [datetime(2012,5,1), datetime(2012,5,2)]
>>> index = pd.DatetimeIndex(dates)
>>> index = pd.date_range(datetime(2012,2,1), end, freq='BM')
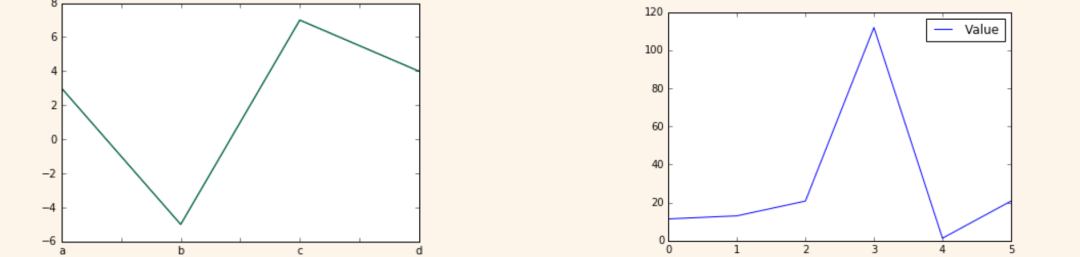
可视化
Series可视化
>>> import matplotlib.pyplot as plt
>> s.plot()
>>> plt.show()
>>> df2.plot()
>>> plt.show()
老表送福利时间(点个赞呀)
赠书规则:给本文点赞+留言,留言说说你还想读什么书,是哪个出版社的,哪个作者写的, 留言集赞数 排名前 3 的朋友,可获得《Python编程完全自学教程》赠书一本。
后面会根据大家的需要进行赠书活动,宠读者计划开启!
领书须知:提供拉赞截图
开奖时间:5月14日 20:00
注意:中奖者24小时内,必须添加我微信领取,逾期不候!为了大家都有机会中奖,本月已经中过书的朋友,再次中奖将不在赠书。
本批书籍由 北京大学出版社 赞助,再次致谢。也欢迎大家自行前往购买支持。
扫码即可加老表私人微信
观看朋友圈,获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 “点赞”传统美德不能丢