
kafka存储结构以及Log清理机制
本文主要聚焦 kafka 的日志存储以及日志清理相关。
日志存储结构
首先我们来看一张 kafak 的存储结构图。
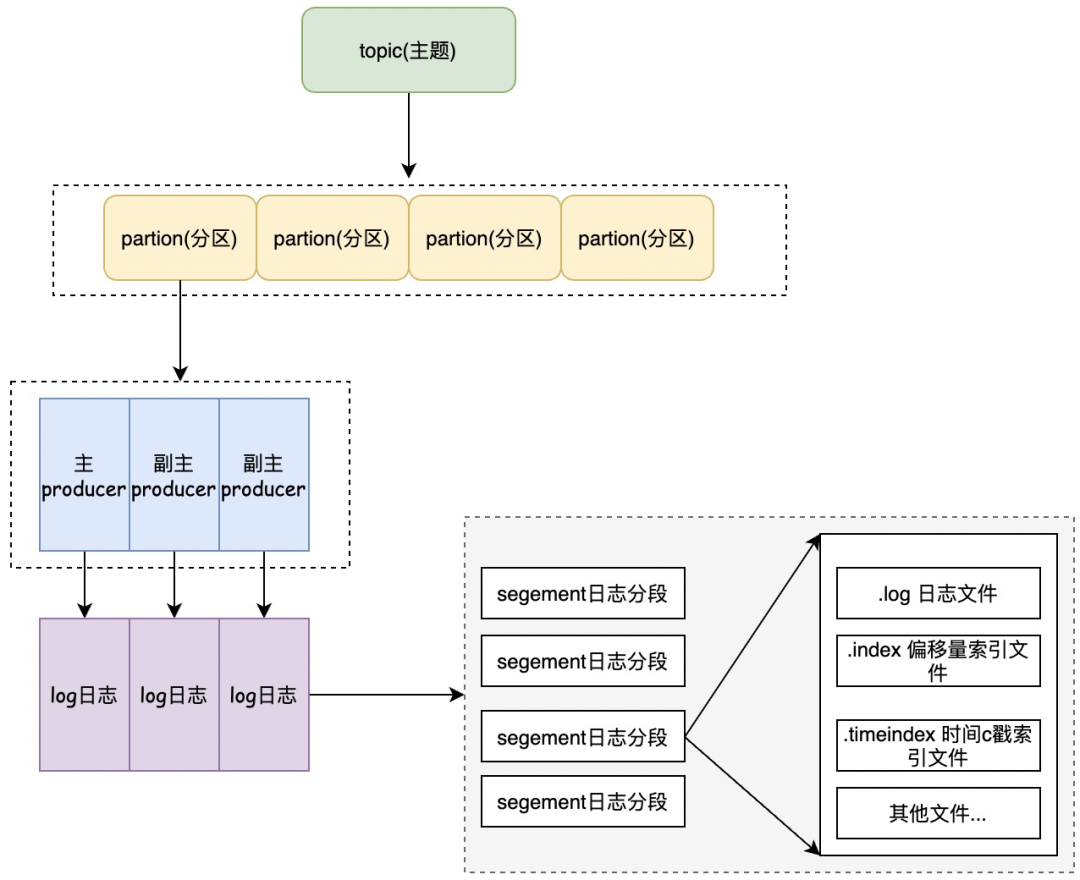
如上图所示、kafka 中消息是以主题 topic 为基本单位进行归类的,这里的 topic 是逻辑上的概念,实际上在磁盘存储是根据分区存储的,每个主题可以分为多个分区、分区的数量可以在主题创建的时候进行指定。例如下面 kafka 命令创建了一个 topic 为 test 的主题、该主题下有 4 个分区、每个分区有两个副本保证高可用。
./bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 2 --partitions 4 --topic test
复制代码
分区的修改除了在创建的时候指定。还可以动态的修改。如下将 kafka 的 test 主题分区数修改为 12 个
./kafka-topics.sh --alter --zookeeper 127.0.0.1:2181 --topic test --partitions 12
复制代码
分区内每条消息都会被分配一个唯一的消息 id,也就是我们通常所说的 offset, 因此 kafak 只能保证每一个分区内部有序性,不能保证全局有序性。
如果分区设置的合理,那么所有的消息都可以均匀的分布到不同的分区中去,这样可以实现水平扩展。不考虑多副本的情况下,一个分区对应一个 log 日志、如上图所示。为了防止 log 日志过大,kafka 又引入了日志分段(LogSegment)的概念,将 log 切分为多个 LogSegement,相当于一个巨型文件被平均分配为相对较小的文件,这样也便于消息的维护和清理。事实上,Log 和 LogSegement 也不是纯粹物理意义上的概念,Log 在物理上只是以文件夹的形式存储,而每个 LogSegement 对应于磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以".txindex"为后缀的事务索引文件)。
kafak 中的 Log 对应了一个命名为<topic>-<partition> 的文件夹。举个例子、假如有一个 test 主题,此主题下游 3 个分区,那么在实际物理上的存储就是 "test-0","test-1","test-2" 这三个文件夹。
向 Log 中写入消息是顺序写入的。只有最后一个 LogSegement 才能执行写入操作,在此之前的所有 LogSegement 都不能执行写入操作。为了方便描述,我们将最后一个 LogSegement 成为"ActiveSegement",即表示当前活跃的日志分段。随着消息的不断写入,当 ActiveSegement 满足一定的条件时,就需要创建新的 activeSegement,之后在追加的消息写入新的 activeSegement。
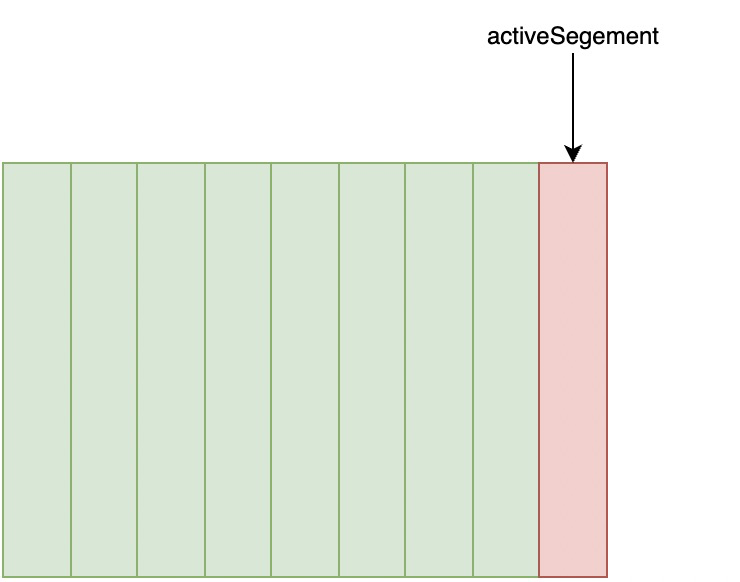
为了便于消息的检索,每个 LogSegement 中的日志文件(以".log" 为文件后缀)都有对应的两个文件索引:偏移量索引文件(以".index" 为文件后缀)和时间戳索引文件(以".timeindex"为文件后缀)。每个 LogSegement 都有一个“基准偏移量” baseOffset,用来标识当前 LogSegement 中第一条消息的 offset。偏移量是一个 64 位的长整形。日志文件和两个索引文件都是根据基准偏移量(baseOffset)命名的,名称固定为 20 位数字,没有达到的位数则用 0 填充。比如第一个 LogSegment 的基准偏移量为 0,对应的日志文件为 00000000000000000000.log

示例中第 2 个 LogSegment 对应的基准位移是 256,也说明了该 LogSegment 中的第一条消息的偏移量为 256,同时可以反映出第一个 LogSegment 中共有 256 条消息(偏移量从 0 至 254 的消息)。
注意每个 LogSegment 中不只包含“.log”“.index”“.timeindex”这 3 种文件,还可能包含“.deleted”“.cleaned”“.swap”等临时文件,以及可能的“.snapshot”“.txnindex”“leader-epoch-checkpoint”等文件。
日志清理机制
由于 kafak 是把消息存储 在磁盘上,为了控制消息的不断增加我们就必须对消息做一定的清理和压缩。kakfa 中的每一个分区副本都对应的一个 log 日志文件。而 Log 又分为多个 LogSegement 日志分段。这样也便于日志清理。kafka 内部提供了两种日志清理策略。
日志删除
按照一定的保留策略直接删除不符合条件的日志分段。
基于时间
我们可以通过 broker 端参数 log.cleanup.policy 来设置日志清理策略,此参数的默认值为“delete”,即采用日志删除的清理策略。如果要采用日志压缩的清理策略,就需要将 log.cleanup.policy 设置为“compact”,并且还需要将 log.cleaner.enable(默认值为 true)设定为 true。通过将 log.cleanup.policy 参数设置为“delete,compact”,还可以同时支持日志删除和日志压缩两种策略。日志清理的粒度可以控制到主题级别,比如与 log.cleanup.policy 对应的主题级别的参数为 cleanup.policy,为了简化说明,本文只采用 broker 端参数做陈述。
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值(retentionMs)来寻找可删除的日志分段文件集合(deletableSegments),如图下图所示。retentionMs 可以通过 broker 端参数 log.retention.hours、log.retention.minutes 和 log.retention.ms 来配置,其中 log.retention.ms 的优先级最高,log.retention.minutes 次之,log.retention.hours 最低。默认情况下只配置了 log.retention.hours 参数,其值为 168,故默认情况下日志分段文件的保留时间为 7 天。
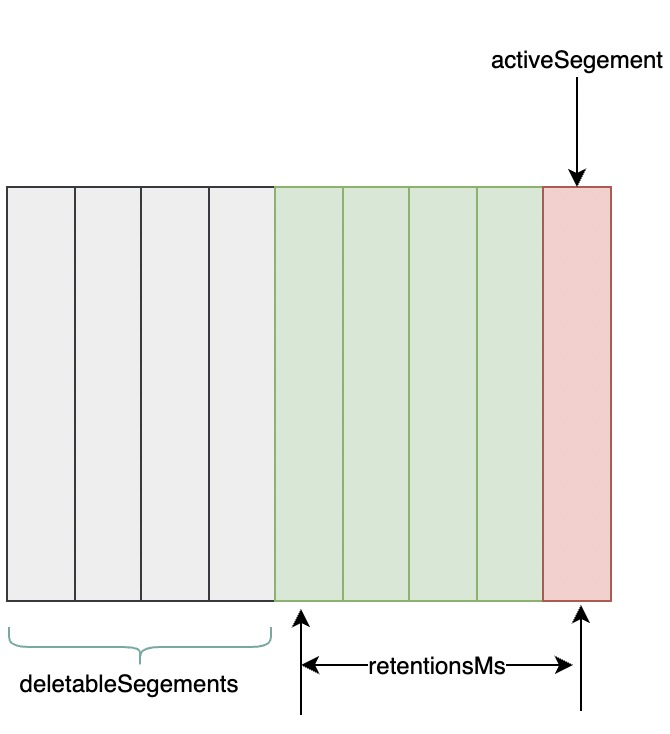
查找过期的日志分段文件,并不是简单地根据日志分段的最近修改时间 lastModifiedTime 来计算的,而是根据日志分段中最大的时间戳 largestTimeStamp 来计算的。因为日志分段的 lastModifiedTime 可以被有意或无意地修改,比如执行了 touch 操作,或者分区副本进行了重新分配,lastModifiedTime 并不能真实地反映出日志分段在磁盘的保留时间。要获取日志分段中的最大时间戳 largestTimeStamp 的值,首先要查询该日志分段所对应的时间戳索引文件,查找时间戳索引文件中最后一条索引项,若最后一条索引项的时间戳字段值大于 0,则取其值,否则才设置为最近修改时间 lastModifiedTime.
若待删除的日志分段的总数等于该日志文件中所有的日志分段的数量,那么说明所有的日志分段都已过期,但该日志文件中还要有一个日志分段用于接收消息的写入,即必须要保证有一个活跃的日志分段 activeSegment,在此种情况下,会先切分出一个新的日志分段作为 activeSegment,然后执行删除操作。
删除日志分段时,首先会从 Log 对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作。然后将日志分段所对应的所有文件添加上“.deleted”的后缀(当然也包括对应的索引文件)。最后交由一个以“delete-file”命名的延迟任务来删除这些以“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过 file.delete.delay.ms 参数来调配,此参数的默认值为 60000,即 1 分钟。
基于日志大小
日志删除任务会检查当前日志的大小是否超过设定的阈值(retentionSize)来寻找可删除的日志分段的文件集合(deletableSegments),如下图所示。retentionSize 可以通过 broker 端参数 log.retention.bytes 来配置,默认值为-1,表示无穷大。注意 log.retention.bytes 配置的是 Log 中所有日志文件的总大小,而不是单个日志分段(确切地说应该为.log 日志文件)的大小。单个日志分段的大小由 broker 端参数 log.segment.bytes 来限制,默认值为 1073741824,即 1GB。
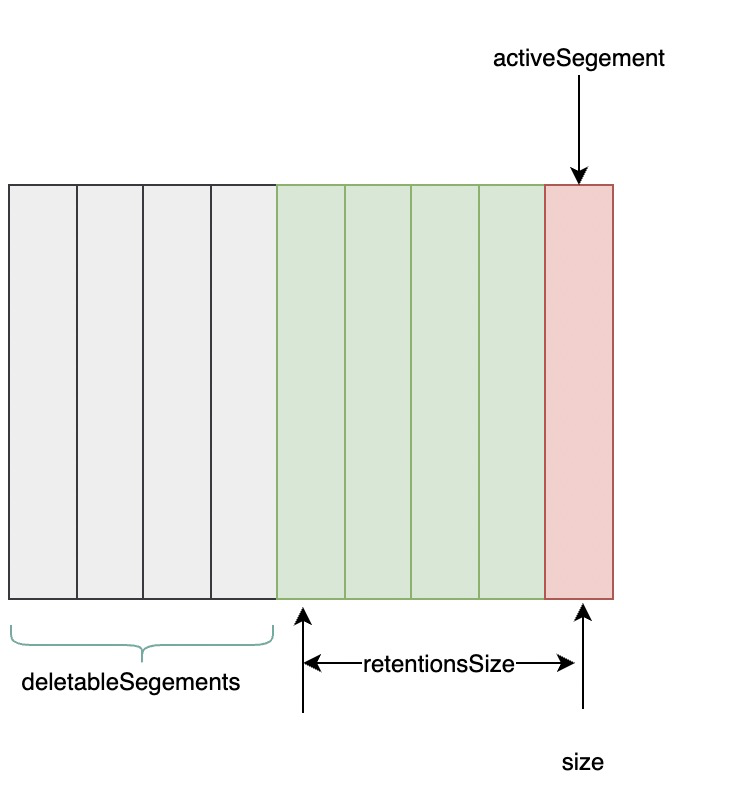
基于日志大小的保留策略与基于时间的保留策略类似,首先计算日志文件的总大小 size 和 retentionSize 的差值 diff,即计算需要删除的日志总大小,然后从日志文件中的第一个日志分段开始进行查找可删除的日志分段的文件集合 deletableSegments。查找出 deletableSegments 之后就执行删除操作,这个删除操作和基于时间的保留策略的删除操作相同