
你真的会打印日志?
点击上方“中间件兴趣圈”,选择“设为星标”
越努力越幸运,唯有坚持不懈!
一看这个标题我想大家一定进来想“怼”我,你这不是小题大作吗?在java中打印日志不是一件非常简单的事情吗?
在java中常用的日志级别为DEBUG、INFO、WARN、ERROR四个日志级别。通常开发环境开启DEBUG,生产环境开启INFO级别,采用主流的日志采集工具包诸如log4j、logback。
但日志输出真的有这么简单吗?其实里面蕴含着很多的规范,或者是最佳实践,并且还有一些非常有用设计技巧方便查询关联日志的技巧,容我慢慢道来。
输出日志的终极目标:助力于快速定位问题、解决问题。
接下来将围绕该目标,阐述一下日志相关的一些最佳实践。
1、日志的基本规范
首先,我们还是简单介绍一下常用的4个日志级别,并说明各个级别在使用时应该注意的问题。
DEBUG 输出程序的调试信息,优雅的DEBUG日志可以让我们在排查问题的时候,压根就不需要使用开发工具的DEBUG断点调试功能,而是直接看Debug的输出日志即可定位问题。
打印请求、响应数据包,特别是入口处将所有请求参数打印 对核心方法,特别核心计算逻辑前后打印当时的输入与输出,并日志中显示包含方法名称。 对核心流程(循环、分支)等条件判断时输出必要的入参于与返回结果,清晰的展示程序的运行轨迹。 INFO INFO日志我们通常用于记录系统/组件的基本运行情况和运行状态,特别适合打印一次性日志,例如核心类的启动过程、状态变更等信息,输出的内容一定要非常详细,不要担心影响性能。
目前的主流日志输出框架例如logback,其日志的打印基本都是基于异步的,性能已经非常高,无需担心性能损耗。
WARN 警告级别,通常用于可预知但又不希望发生的情况,典型的使用场景是打印业务类异常日志,例如参数校验不通过、权限不足,余额不足等用户可处理的;再例如中间件开发时,有一些分支是我们不希望进入的,因为进入就代表性能差等场景,但这类异常不需要相关系统负责人干预就能得到处理的。
ERROR 通常用来打印系统级别的日志,需要人为来干预,通常较大业务规模的公司都会将系统级别的异常(ERROR)接入监控告警中心,一旦持续发生多少条,错误率占比多少,将会触发告警,相关负责人跟进处理。
既然需要人为来干预,ERROR日志不仅要打印出错误堆栈,同时一定要主动打印出上下文环境,至少可以打印出该异常所在方法的入参,尽量让人能够根据错误日志与上下文,就能快速定位到具体的代码行。
2、日志进阶
上述是一些基本的日志使用规范,分布式已成为企业架构的标配,一个应用至少会部署2台机器,当用户反馈业务异常时尝试去跟踪日志时会面临一个问题:去哪台业务机器上去查询日志,如果只有2台还好办,大不了一台台去尝试,但如果有10台,20台甚至上百台,在这样轮询几乎不可能实现,那该如何处理呢?
经典的ELK架构如下图所示: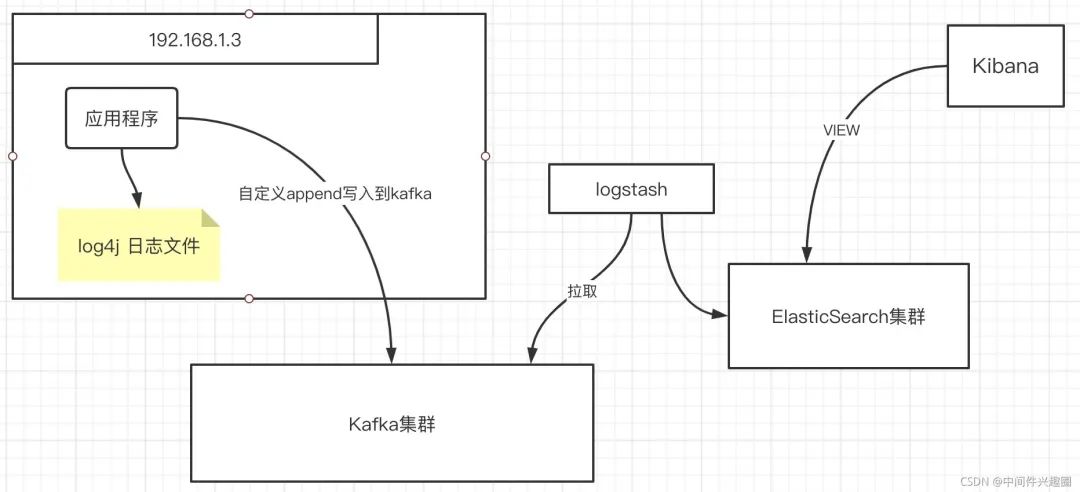 通常,为了避免在每台业务机器上部署一个logstash去抽日志,我们通常建议自定义一个log append,直接将日志写入到kafka中,然后再挂logstash从kafka中抽取日志,写入到es集群,然后通过kibana对日志进行可视化搜索。
通常,为了避免在每台业务机器上部署一个logstash去抽日志,我们通常建议自定义一个log append,直接将日志写入到kafka中,然后再挂logstash从kafka中抽取日志,写入到es集群,然后通过kibana对日志进行可视化搜索。
然后我们查询日志就变得类似这样了: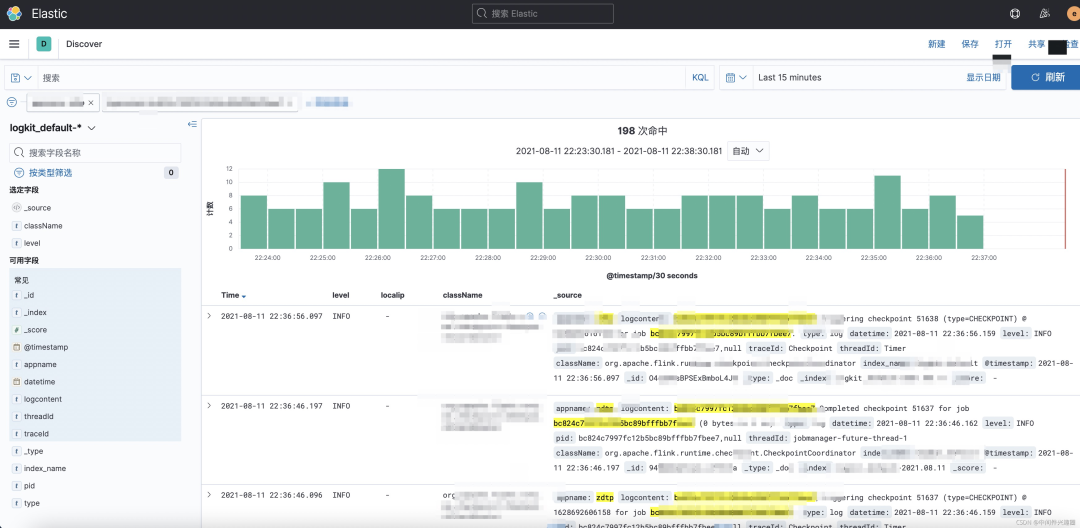 本文并没有打算探讨ELK架构,这个后续应该会单独展开详细介绍,而是就算我们接入了ELK,从ELK可以统一查看根据关键字查询日志了,该日志会包含所有服务器上的日志,比单独一台一台去找依然方便了很多。
本文并没有打算探讨ELK架构,这个后续应该会单独展开详细介绍,而是就算我们接入了ELK,从ELK可以统一查看根据关键字查询日志了,该日志会包含所有服务器上的日志,比单独一台一台去找依然方便了很多。
但这些日志其实是杂乱无章的,查询出来的日志与日志之间没有任何关联性,而我们在解决特定问题时通常希望日志的**“隔离性”**,希望我们可以根据一个统一的关键字,例如请求号筛选出所有相关的日志,这样对我们分析排查问题能起到极大的促进作用。
2.1 每条日志包含一个请求序
那我们如何将“请求号”统一写入到日志文件中,肯定不能要求在项目中去修改所有日志输出到地方,手动去增加请求编号。
我们可以通过自定义一个append,在append中对用户的日志统一进行二次加工。
logback、log4j都可以自定append,接下来以当前使用最广logback举例,和大家介绍一下自定义append。
1、继承 AppenderBase 并初始化
首先需要继承logback的append的基础类:AppenderBase,入下图所示: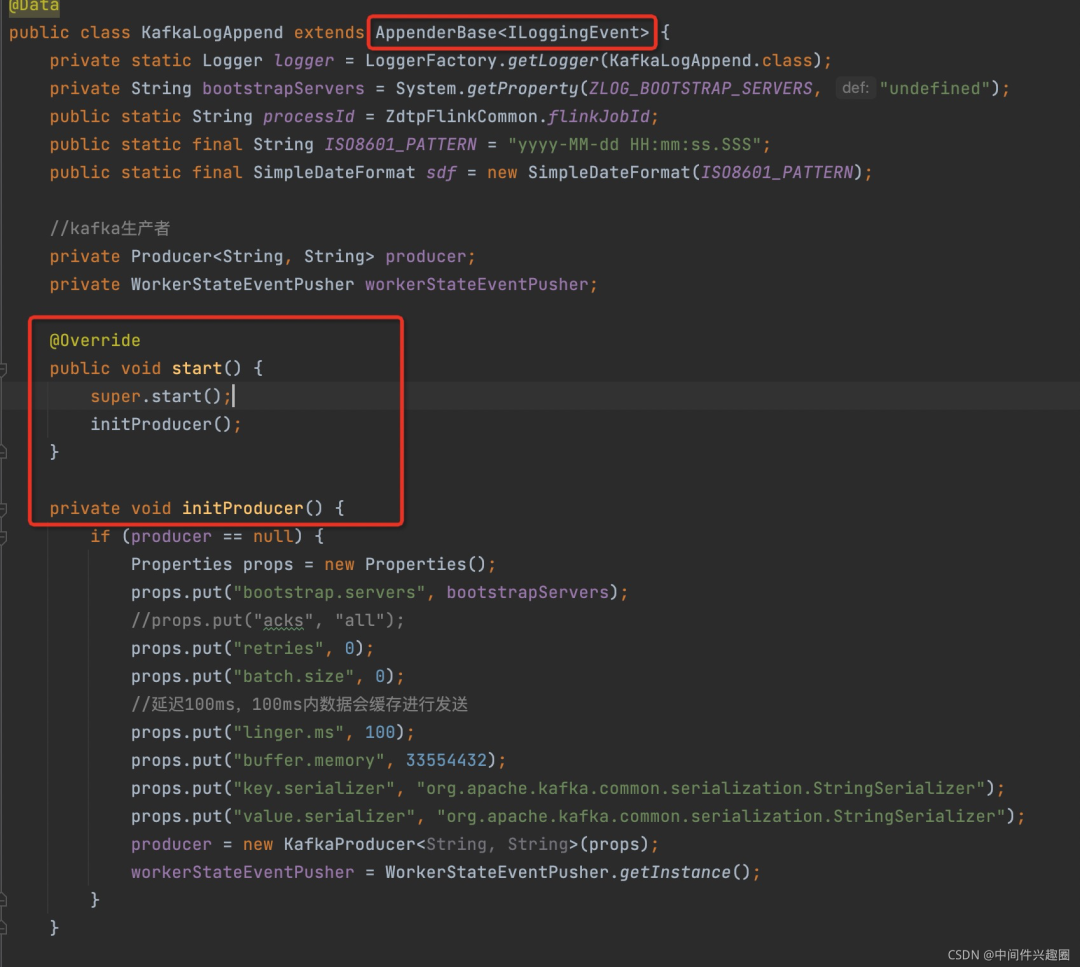 其中有一个初始化方法start,通常的做法是先调用super.start()标记append启动,然后可以在该方法中初始化kafka的消息发送者对象。
其中有一个初始化方法start,通常的做法是先调用super.start()标记append启动,然后可以在该方法中初始化kafka的消息发送者对象。
2、重写append方法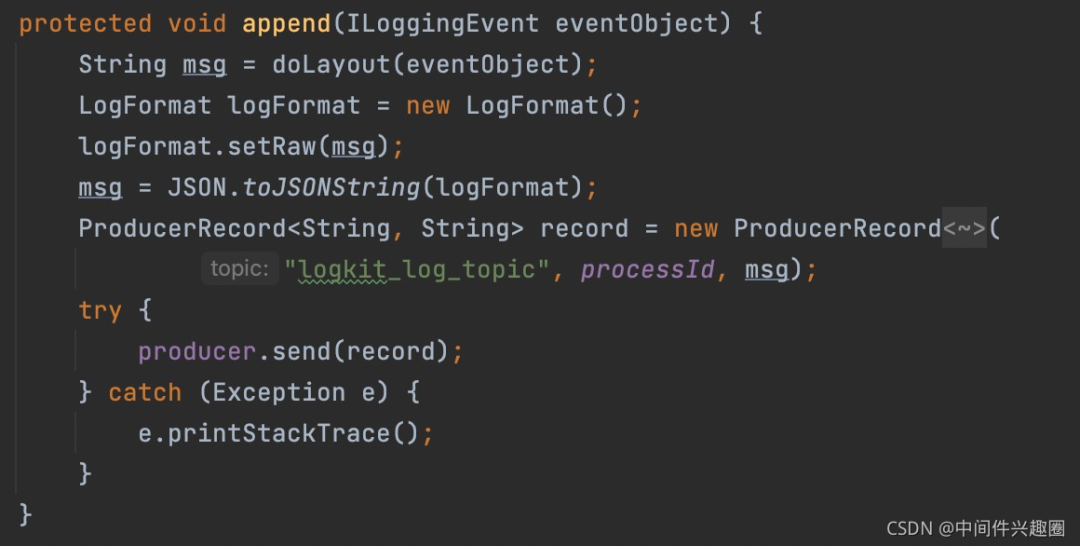 主要是从ILoggingEvent对象中获取原始日志,然后我们对原始日志加以加工,加工代码如下图所示:
主要是从ILoggingEvent对象中获取原始日志,然后我们对原始日志加以加工,加工代码如下图所示: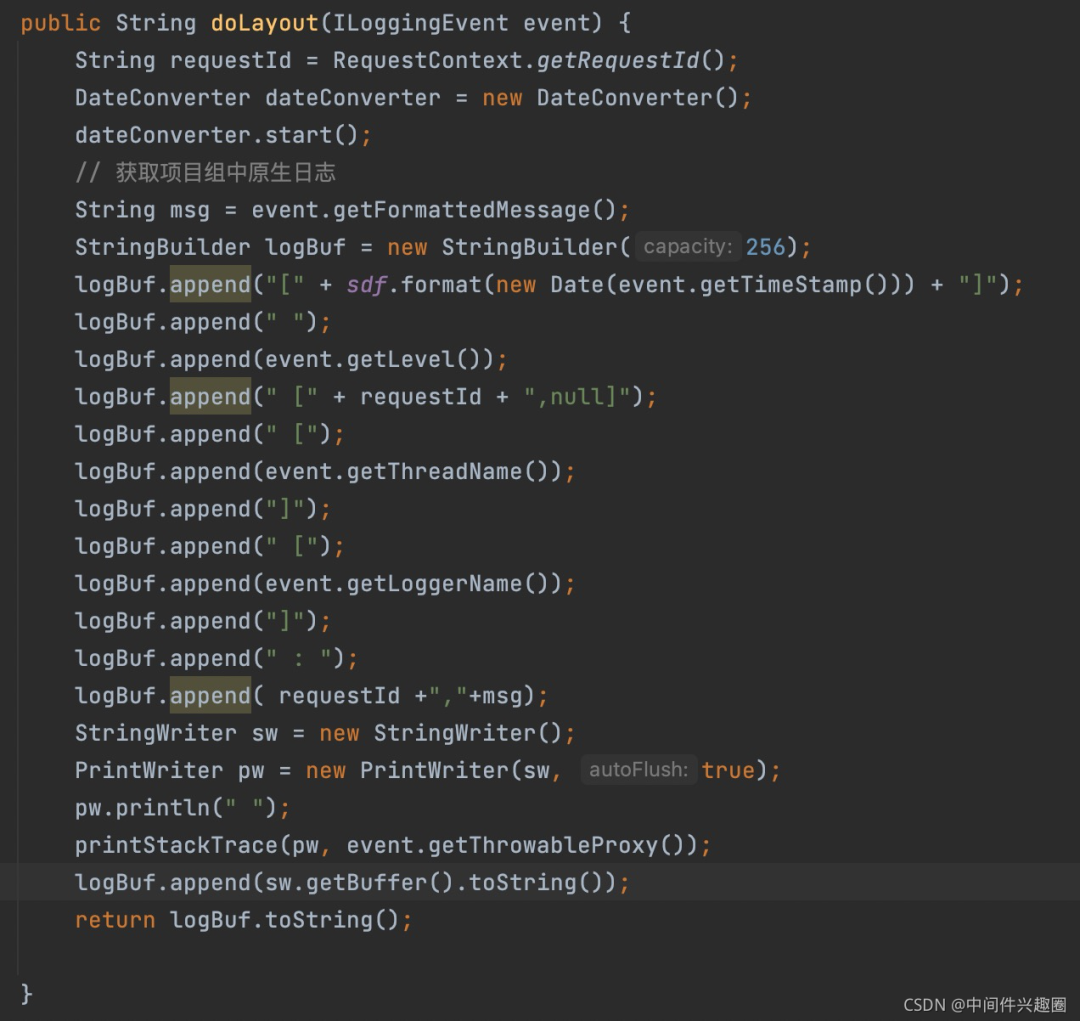 关键是reqeustId的获取,这个通常会配置一个http filter,进入请求链中放入到线程本地变量中(ThreadLocal),然后在日志输出时从线程上下文环境中获取,为了能在线程池等复杂环境下使用,通常可以使用(TransmittableThreadLocal),关于在线程池中传递数据,需要使用ttl框架,关于这块的想象介绍可以查看笔者的另一篇博文:全链路压测必备基础组件之线程上下文管理之“三剑客”
关键是reqeustId的获取,这个通常会配置一个http filter,进入请求链中放入到线程本地变量中(ThreadLocal),然后在日志输出时从线程上下文环境中获取,为了能在线程池等复杂环境下使用,通常可以使用(TransmittableThreadLocal),关于在线程池中传递数据,需要使用ttl框架,关于这块的想象介绍可以查看笔者的另一篇博文:全链路压测必备基础组件之线程上下文管理之“三剑客”
一键三连(关注、点赞、留言)是对我最大的鼓励。
⚠️点击下方卡片,关注弹出内容,回复「PDF」可领取海量学习资料,共同刷题进步,内互相监督,记录成长!
