
日志多租户架构下的 Loki 方案
当我们在看Loki的架构文档时,社区都会宣称Loki是一个可以支持多租户模式下运行的日志系统,但我们再想进一步了解时,它却含蓄的表示Loki开启多租户只需要满足两个条件:
配置文件中添加 auth_enabled: true请求头内带上租户信息 X-Scope-OrgID
这一切似乎都在告诉你,"快来用我吧,这很简单",事实上当我们真的要在kubernetes中构建一个多租户的日志系统时,我们需要考虑的远不止于此。
通常当我们在面对一个多租户的日志系统架构时,出于对日志存储的考虑,我们一般会有两种模式来影响系统的架构。
1. 日志集中存储(后文以方案A代称)
和Loki原生一样,在日志进入到集群内,经过一系列校验和索引后集中的将日志统一写入后端存储上。
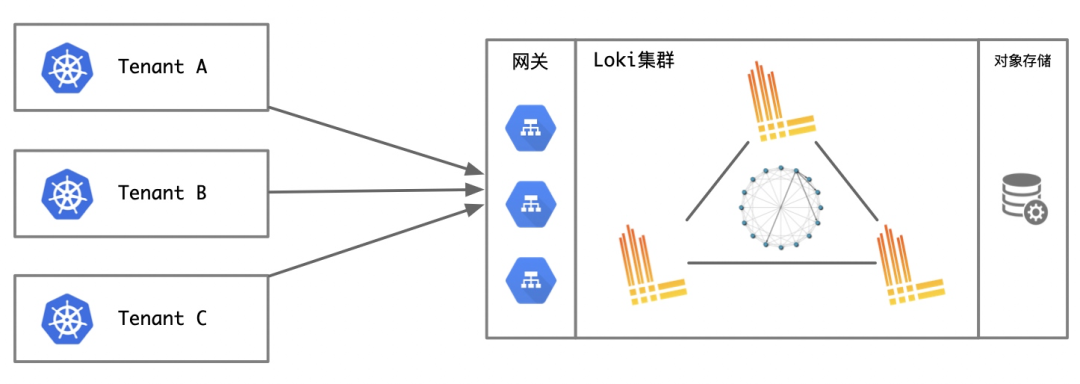
2. 日志分区存储(后文以方案B代称)
反中心存储架构,每个租户或项目都可以拥有独立的日志服务和存储区块来保存日志。
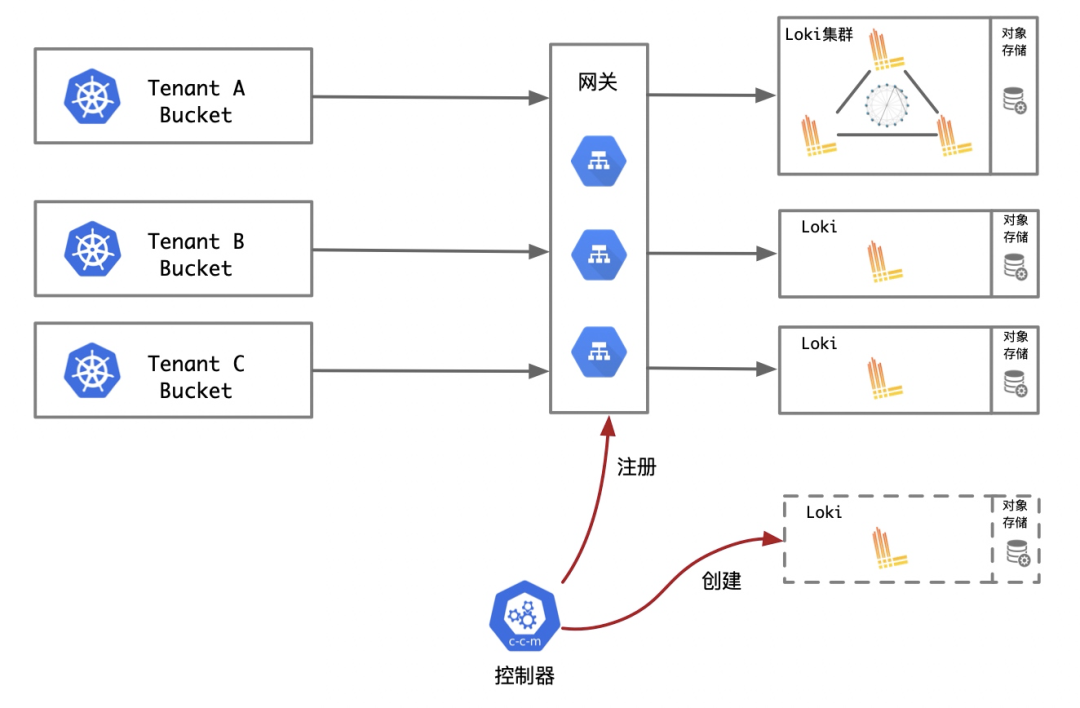
从直觉上来看,日志分区带来的整体结构会更为复杂,除了需要自己开发控制器来管理loki服务的生命周期外,它还需要为网关提供正确的路由策略。不过,不管多租户的系统选择何种方案,在本文我们也需从日志的整个流程来阐述不同方案的实现。
第一关:Loki划分
Loki是最终承载日志存储和查询的服务,在多租户的模式下,不管是大集群还是小服务,Loki本身也存在一些配置空间需要架构者去适配。其中特别是在面对大集群场景下,保证每个租户的日志写入和查询所占资源的合理分配调度就显得尤为重要。
在原生配置中,大部分关于租户的调整可以在下面两个配置区块中完成:
query_frontend_config limits_config
query_frontend_config
query_frontend是Loki分布式集群模式下的日志查询最前端,它承担着用户日志查询请求的分解和聚合工作。那么显然,query_frontend对于请求的处理资源应避免被单个用户过分抢占。
每个frontend处理的租户
[max_outstanding_per_tenant: <int> | default = 100]
limits_config
limits_config基本控制了Loki全局的一些流控参数和局部的租户资源分配,这里面可以通过Loki的-runtime-config启动参数来让服务动态定期的加载租户限制。这部分可以通过runtime_config.go中的runtimeConfigValues结构体内看到
type runtimeConfigValues struct {
TenantLimits map[string]*validation.Limits `yaml:"overrides"`
Multi kv.MultiRuntimeConfig `yaml:"multi_kv_config"`
}
可以看到对于TenantLimits内的限制配置是直接继承limits_config的,那么这部分的结构应该就是下面这样:
overrides:
tenantA:
ingestion_rate_mb: 10
max_streams_per_user: 100000
max_chunks_per_query: 100000
tenantB:
max_streams_per_user: 1000000
max_chunks_per_query: 1000000
当我们在选择采用方案A的日志架构时,关于租户部分的限制逻辑就应该要根据租户内的日志规模灵活的配置。如果选择方案B,由于每个租户占有完整的Loki资源,所以这部分逻辑就直接由原生的limits_config控制。
第二关:日志客户端
在Kubernetes环境下,最重要是让日志客户端知道被采集的容器所属的租户信息。这部分实现可以是通过日志Operator或者是解析kubernetes元数据来实现。虽然这两个实现方式不同,不过最终目的都是让客户端在采集日之后,在日志流的请求上添加租户信息头。下面我分别以logging-operator和fluentbit/fluentd这两种实现方式来描述他们的实现逻辑
Logging Operator
Logging Operator是BanzaiCloud下开源的一个云原生场景下的日志采集方案。它可以通过创建NameSpace级别的CRD资源flow和output来控制日志的解析和输出。
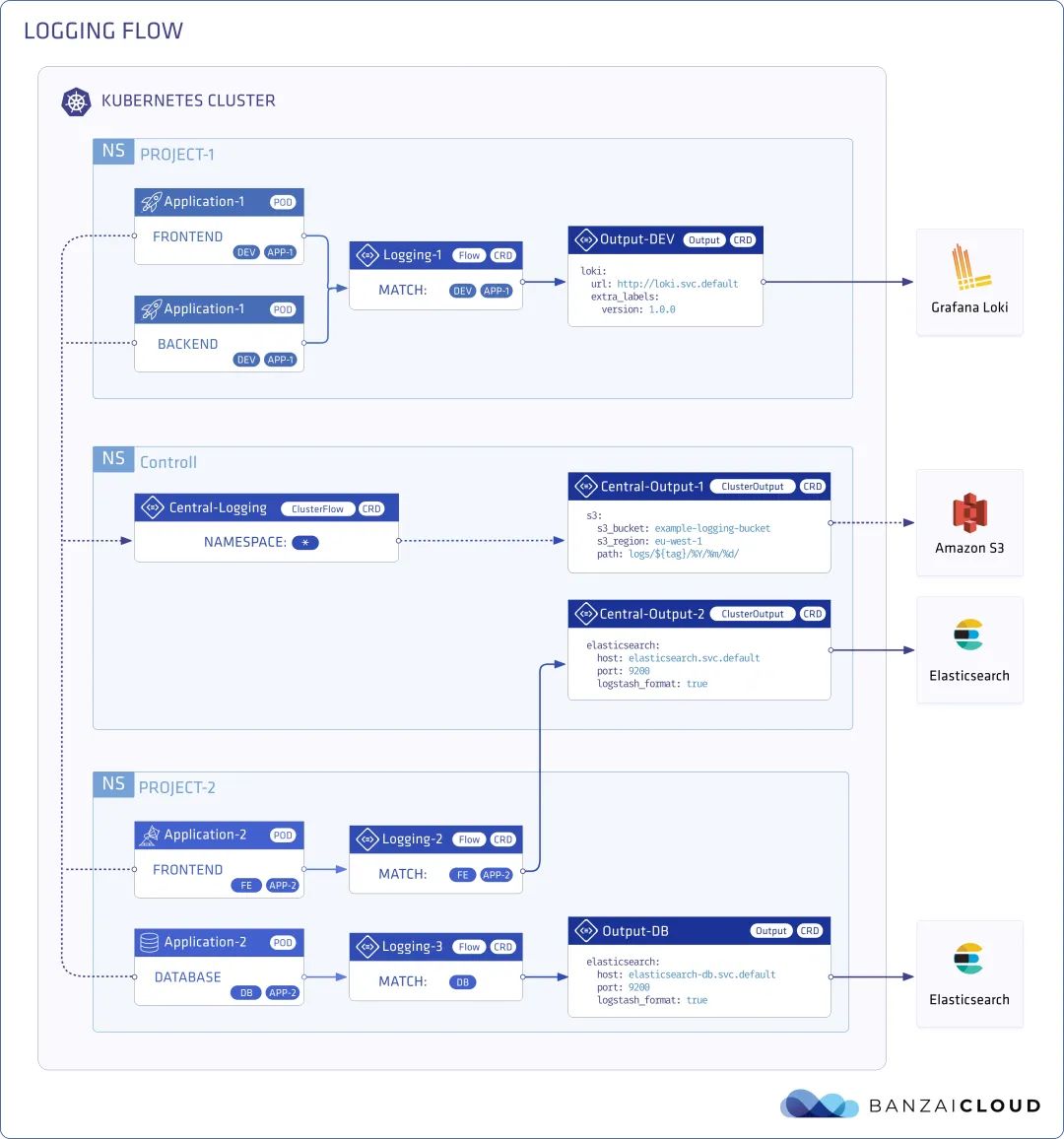
通过Operator的方式可以精细的控制租户内的日志需要被采集的容器,以及控制它们的流向。以输出到loki举例,通常在只需在租户的命名空间内创建如下资源就能满足需求。
output.yaml,在创建资源时带入租户相关的信息
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: loki-output
namespace: <tenantA-namespace>
spec:
loki:
url: http://loki:3100
username: <tenantA>
password: <tenantA>
tenant: <tenantA>
...
flow.yaml,在创建资源时关联租户需要被采集日志的容器,以及指定输出
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: flow
namespace: <tenantA-namespace>
spec:
localOutputRefs:
- loki-output
match:
- select:
labels:
app: nginx
filters:
- parser:
remove_key_name_field: true
reserve_data: true
key_name: "log"
可以看到通过operator来管理多租户的日志是一个非常简单且优雅的方式,同时通过CRD的方式创建资源对开发者集成到项目也十分友好。这也是我比较推荐的日志客户端方案。
FluentBit/FluentD
FluentBit和FluentD的Loki插件同样支持对多租户的配置。对于它们而言最重要的是让其感知到日志的租户信息。与Operator在CRD中直接声明租户信息不同,直接采用客户端方案就需要通过Kubernetes Metadata的方式来主动抓取租户信息。对租户信息的定义,我们会声明在资源的label中。不过对于不同的客户端,label定义的路径还是比较有讲究的。它们总体处理流程如下:
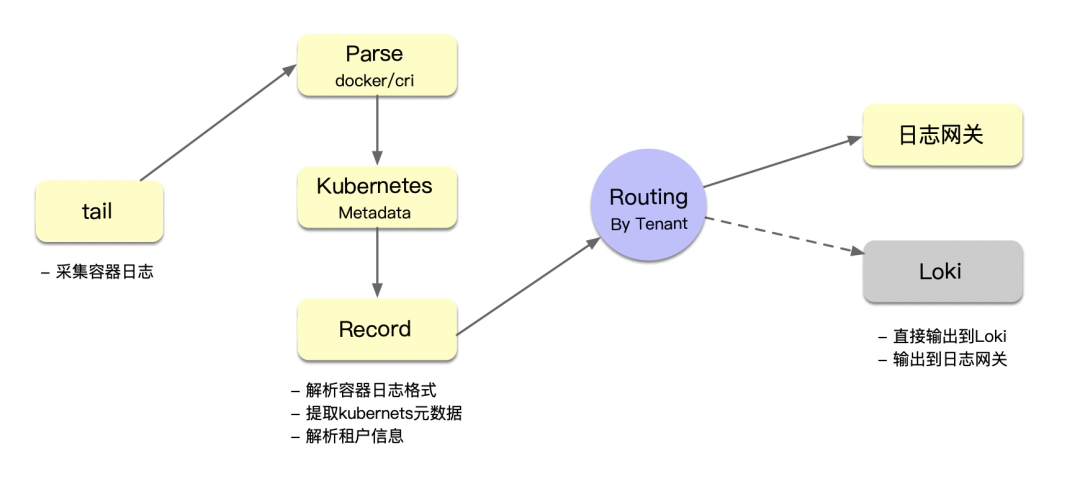
FluentD
fluentd的kubernetes-metadata-filter可以抓取到namespaces_label,所以我比较推荐将租户信息定义在命名空间内。
apiVersion: v1
kind: Namespace
metadata:
labels:
tenant: <tenantA>
name: <taenant-namespace>
这样在就可以loki的插件中直接提取namespace中的租户标签内容,实现逻辑如下
<match loki.**>
@type loki
@id loki.output
url "http://loki:3100"
# 直接提取命名空间内的租户信息
tenant ${$.kubernetes.namespace_labels.tenant}
username <username>
password <password>
<label>
tenant ${$.kubernetes.namespace_labels.tenant}
</label>
FluentBit
fluentbit的metadata是从pod中抓取,那么我们就需要将租户信息定义在workload的template.metadata.labels当中,如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
spec:
template:
metadata:
labels:
app: nginx
tenant: <tanant-A>
之后就需要利用rewrite_tag将容器的租户信息提取出来进行日志管道切分。并在output阶段针对不同日志管道进行输出。它的实现逻辑如下:
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Merge_Log On
[FILTER]
Name rewrite_tag
Match kube.*
#提取pod中的租户信息,并进行日志管道切分
Rule $kubernetes['labels']['tenant'] ^(.*)$ tenant.$kubernetes['labels']['tenant'].$TAG false
Emitter_Name re_emitted
[Output]
Name grafana-loki
Match tenant.tenantA.*
Url http://loki:3100/api/prom/push
TenantID "tenantA"
[Output]
Name grafana-loki
Match tenant.tenantB.*
Url http://loki:3100/api/prom/push
TenantID "tenantB"
可以看到不管是用FluentBit还是Fluentd的方式进行多租户的配置,它们不但对标签有一定的要求,对日志的输出路径配置也不是非常灵活。所以fluentd它比较做适合方案A的日志客户端,而fluentbit比较适合做方案B的日志客户端。
第三层:日志网关
日志网关准确的说是Loki服务的网关,对于方案A来说,一个大Loki集群前面的网关,只需要简单满足能够横向扩展即可,租户的头信息直接传递给后方的Loki服务处理。这类方案相对简单,并无特别说明。只需注意针对查询接口的配置需调试优化,例如网关服务与upstream之间的连接超时时间、网关服务response数据包大小等。
本文想说明的日志网关是针对方案B场景下,解决针对不同租户的日志路由问题。从上文可以看到,在方案B中,我们引入了一个控制器来解决租户Loki实例的管理问题。但是这样就带来一个新的问题需要解决,那就是Loki的服务需要注册到网关,并实现路由规则的生成。这部分可以由集群的控制器CRD资源作为网关的upsteam源配置。控制器的逻辑如下:
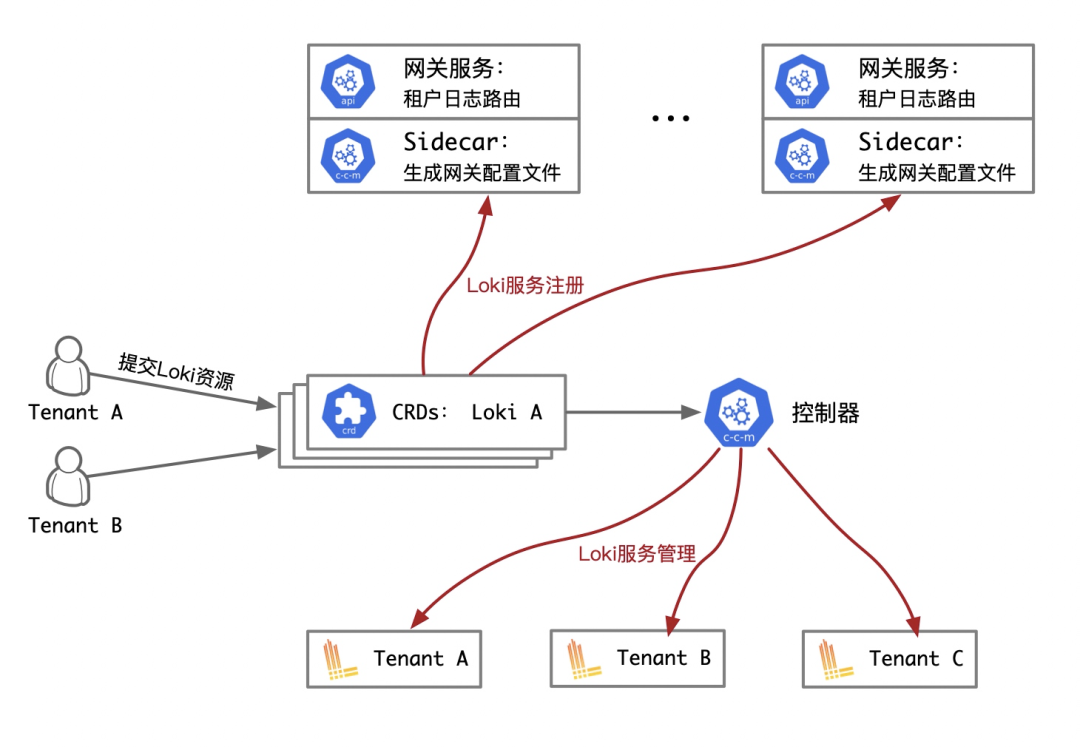
网关服务在处理租户头信息时,路由部分的逻辑为判断Header中X-Scope-OrgID带租户信息的日志请求,并将其转发到对应的Loki服务。我们以nginx作为网关举个例,它的核心逻辑如下:
#upstream内地址由sidecar从CRD中获取loki实例后渲染生成
upstream tenantA {
server x.x.x.x:3100;
}
upstream tenantB {
server y.y.y.y:3100;
}
server {
location / {
set tenant $http_x_scope_orgid;
proxy_pass http://$tenant;
include proxy_params;
总结
本文介绍了基于Loki在多租户模式下的两种日志架构,分别为日志集中存储和日志分区存储。他们分别具备如下的特点:
| 方案 | Loki架构 | 客户端架构 | 网关架构 | 开发难度 | 运维难度 | 自动化程度 |
|---|---|---|---|---|---|---|
| 日志集中存储 | 集群、复杂 | fluentd / fluentbit | 简单 | 简单 | 中等 | 低 |
| 日志分区存储 | 简单 | Logging Opeator | 较复杂 | 较复杂(控制器部分) | 中等 | 高 |
对于团队内具备kubernetes operator相关开发经验的同学可以采用日志分区存储方案,如果团队内偏向运维方向,可以选择日志集中存储方案。