
这样理解 HTTP,面试再也不用慌了~
开源Linux
长按二维码加关注~
1 HTTP
2 Post 和 Get 的区别
Get 请求能缓存,Post 不能
Post 相对 Get 安全一点点,因为Get 请求都包含在 URL 里,且会被浏览器保存历史记录,Post 不会,但是在抓包的情况下都是一样的。
Post 可以通过 request body来传输比 Get 更多的数据,Get 没有这个技术
URL有长度限制,会影响 Get 请求,但是这个长度限制是浏览器规定的,不是 RFC 规定的
Post 支持更多的编码类型且不对数据类型限制
3 常见状态码
200 OK,表示从客户端发来的请求在服务器端被正确处理
204 No content,表示请求成功,但响应报文不含实体的主体部分
205 Reset Content,表示请求成功,但响应报文不含实体的主体部分,但是与 204 响应不同在于要求请求方重置内容
206 Partial Content,进行范围请求
301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
302 found,临时性重定向,表示资源临时被分配了新的 URL
303 see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源
304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
307 temporary redirect,临时重定向,和302含义类似,但是期望客户端保持请求方法不变向新的地址发出请求
400 bad request,请求报文存在语法错误
401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息
403 forbidden,表示对请求资源的访问被服务器拒绝
404 not found,表示在服务器上没有找到请求的资源
500 internal sever error,表示服务器端在执行请求时发生了错误
501 Not Implemented,表示服务器不支持当前请求所需要的某个功能
503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
4 HTTP 首部
5 HTTPS
6 TLS
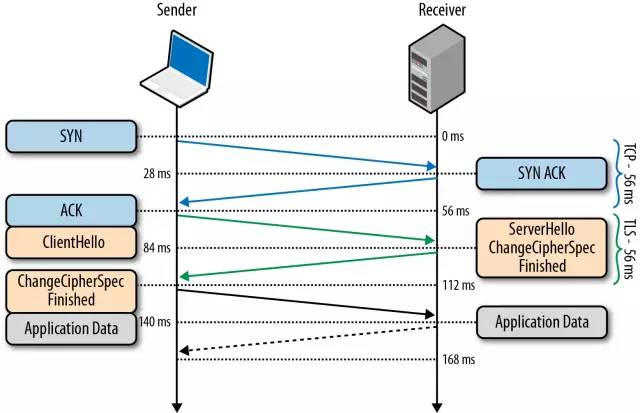
客户端发送一个随机值,需要的协议和加密方式
服务端收到客户端的随机值,自己也产生一个随机值,并根据客户端需求的协议和加密方式来使用对应的方式,发送自己的证书(如果需要验证客户端证书需要说明)
客户端收到服务端的证书并验证是否有效,验证通过会再生成一个随机值,通过服务端证书的公钥去加密这个随机值并发送给服务端,如果服务端需要验证客户端证书的话会附带证书
服务端收到加密过的随机值并使用私钥解密获得第三个随机值,这时候两端都拥有了三个随机值,可以通过这三个随机值按照之前约定的加密方式生成密钥,接下来的通信就可以通过该密钥来加密解密
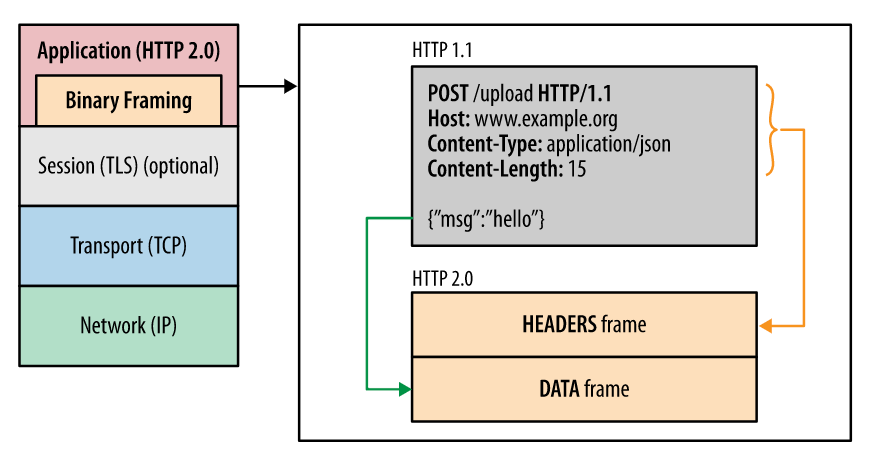
7 HTTP 2.0


8 二进制传输
9 多路复用

10 Header 压缩
11 服务端 Push
12 QUIC
该协议支持多路复用,虽然 HTTP 2.0 也支持多路复用,但是下层仍是 TCP,因为 TCP 的重传机制,只要一个包丢失就得判断丢失包并且重传,导致发生队头阻塞的问题,但是 UDP 没有这个机制
实现了自己的加密协议,通过类似 TCP 的 TFO 机制可以实现 0-RTT,当然 TLS 1.3 已经实现了 0-RTT 了
支持重传和纠错机制(向前恢复),在只丢失一个包的情况下不需要重传,使用纠错机制恢复丢失的包
纠错机制:通过异或的方式,算出发出去的数据的异或值并单独发出一个包,服务端在发现有一个包丢失的情况下,通过其他数据包和异或值包算出丢失包
在丢失两个包或以上的情况就使用重传机制,因为算不出来了
13 DNS
操作系统会首先在本地缓存中查询
没有的话会去系统配置的 DNS 服务器中查询
如果这时候还没得话,会直接去 DNS 根服务器查询,这一步查询会找出负责 com 这个一级域名的服务器
然后去该服务器查询 google 这个二级域名
接下来三级域名的查询其实是我们配置的,你可以给 www 这个域名配置一个 IP,然后还可以给别的三级域名配置一个 IP
14 从输入 URL 到页面加载完成的过程
首先做 DNS 查询,如果这一步做了智能 DNS 解析的话,会提供访问速度最快的 IP 地址回来
接下来是 TCP 握手,应用层会下发数据给传输层,这里 TCP 协议会指明两端的端口号,然后下发给网络层。网络层中的 IP 协议会确定 IP 地址,并且指示了数据传输中如何跳转路由器。然后包会再被封装到数据链路层的数据帧结构中,最后就是物理层面的传输了
TCP 握手结束后会进行 TLS 握手,然后就开始正式的传输数据
数据在进入服务端之前,可能还会先经过负责负载均衡的服务器,它的作用就是将请求合理的分发到多台服务器上,这时假设服务端会响应一个 HTML 文件
首先浏览器会判断状态码是什么,如果是 200 那就继续解析,如果 400 或 500 的话就会报错,如果 300 的话会进行重定向,这里会有个重定向计数器,避免过多次的重定向,超过次数也会报错
浏览器开始解析文件,如果是 gzip 格式的话会先解压一下,然后通过文件的编码格式知道该如何去解码文件
文件解码成功后会正式开始渲染流程,先会根据 HTML 构建 DOM 树,有 CSS 的话会去构建 CSSOM 树。如果遇到 script 标签的话,会判断是否存在
async或者defer,前者会并行进行下载并执行 JS,后者会先下载文件,然后等待 HTML 解析完成后顺序执行,如果以上都没有,就会阻塞住渲染流程直到 JS 执行完毕。遇到文件下载的会去下载文件,这里如果使用 HTTP 2.0 协议的话会极大的提高多图的下载效率。初始的 HTML 被完全加载和解析后会触发 DOMContentLoaded 事件
CSSOM 树和 DOM 树构建完成后会开始生成 Render 树,这一步就是确定页面元素的布局、样式等等诸多方面的东西
在生成 Render 树的过程中,浏览器就开始调用 GPU 绘制,合成图层,将内容显示在屏幕上了
- End - 关注「开源Linux」加星标,提升IT技能
好文章,分享、点赞、在看三连哦❤️↓↓↓