
求你了,别再问我网页或APP抓包了!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
阅读文本大概需要 6 分钟
作者:pk哥
来源:Python知识圈
这半个月,pk 哥 在 B 站上传了两个关于爬虫的视频,很多 B 站小伙伴私信我,那些请求参数有什么意思,怎么更快的抓包获取这些请求?作为爬虫的前戏工作:调试和抓包,是很重要的。今天我就详细的给大家分享一下浏览器 F12 开发者调试工具和 APP 抓包的常见用法。
网页抓包
首先对于网页爬虫来说怎么抓包呢?很简单,我们直接在网页上右键点击检查或者快捷键 F12 就可以进入开发者调试工具。如果页面是经过请求接口而返回的数据的话,在 Network 中,它就会产生请求的数据,我们在这里都能捕捉到。

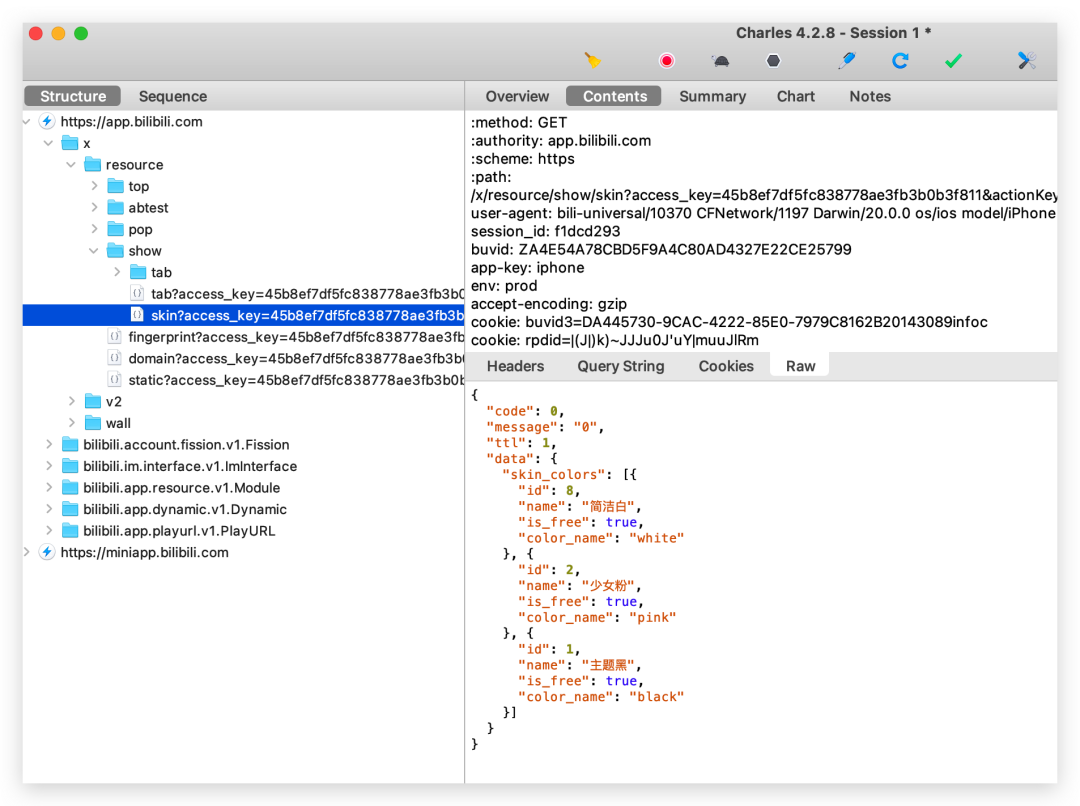
我们还是以之前的 P 站为例,我们点开一个接口,这个接口分为两部分,一个是请求的数据,一个是返回的数据,请求的信息主要在 Headers 里面,它主要有以下几部分,第 1 部分,General 里面主要包含了请求的链接 URL 以及他的请求方式,用的多的就是 get 和 post 了,还有请求状态码,200 表示请求接口成功。
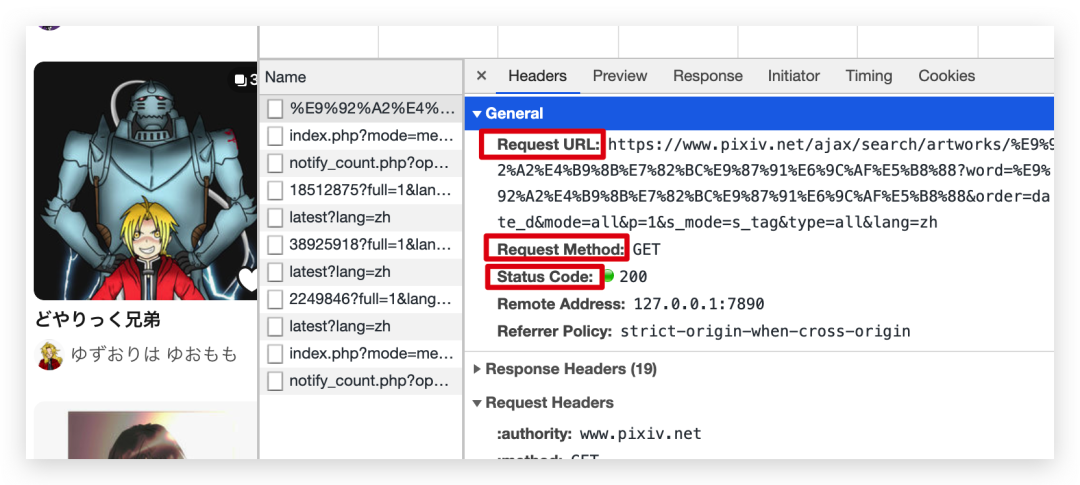
我们来看一下 Request Headers 请求头的信息,我讲一下请求头里很重要的几个请求参数。
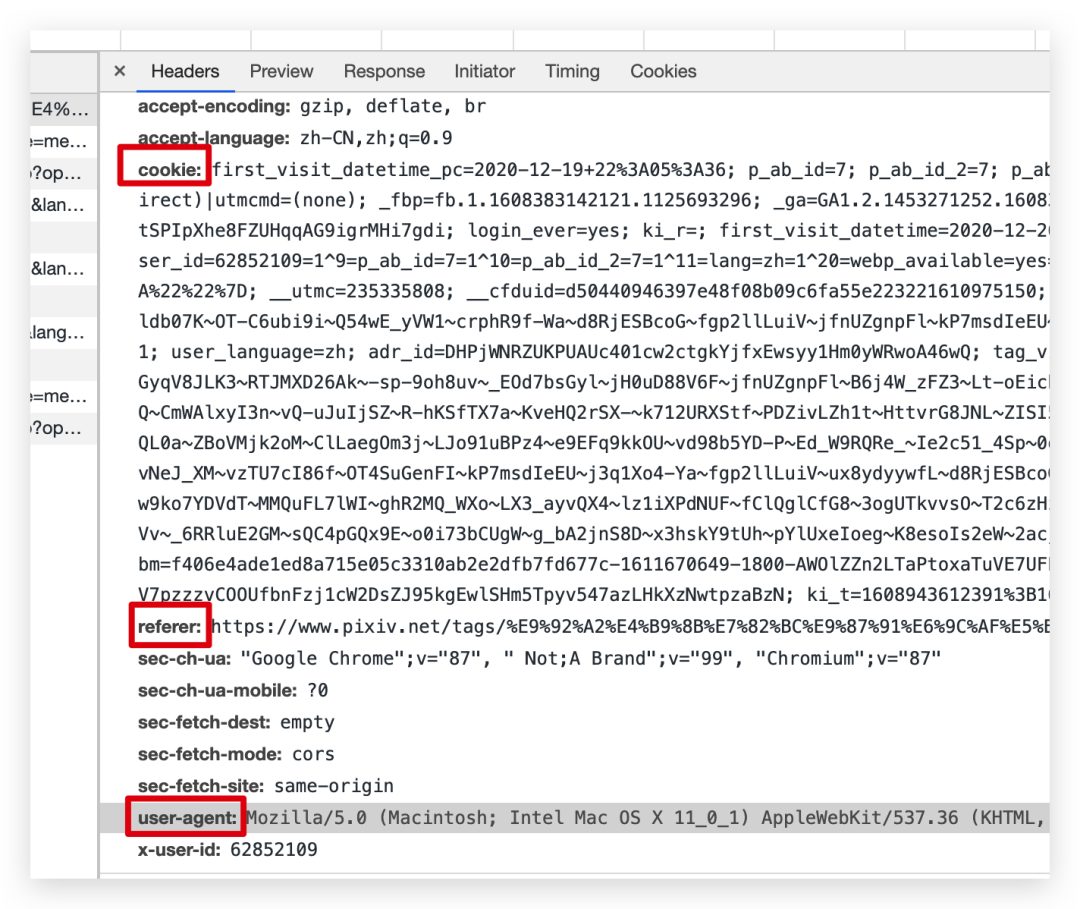
第一个是 Cookie,什么是cookie呢?Cookie是网站储存用户的相关的加密数据,这些数据是网站为了识别用户的身份,第一次登录的时候,你的 cookie 信息会被返回并且被网站服务器保存,请求第二个页面的时候,请求信息会带上 cookie,这样网站就能识别用户身份。当然,Cookie储存是有时效的,超过规定的时候后,cookie就失效了,网站会让你重新登录重新获取新的 cookie。所以对于需要登录才能看到数据的网站,请求接口时 cookie 参数是必须要给出的,不然就无法请求数据。
第 2个 请求参数是:Referer,这个参数是告诉网站服务器,你是从哪个页面跳转过来的,如果这个参数为空或者网址不是服务器白名单的网址,那服务器可能很快就判断你是异常请求或者爬虫了。
第 3 个比较重要的就是 user-agent,是网站用来检测你的请求是人为的还是真实的浏览器行为,我们加入 user-agent 就是为了模拟成真实的浏览器,从而“骗”过网站服务器,你不加的话,就相当于在你在人家服务器里“裸奔”,你说你在别人家地盘搞颜色,服务器不封你封谁呢?
最后是 query string parameters,因为我们这个是 get 请求,这些参数也就是请求 url 里问号后面要带的参数,比如上次讲的插画的展示模式 mode,下滑加载的页数 P,这些可以统一把它放在一个元组里。
params = (
('mode', 'rookie'),
('content', 'illust'),
('p', p),
('format', 'json'),
)
那这些分析出来了之后。那我们就是通过 requests 库来请求接口返回数据了。
response = requests.get(url, headers=headers, params=params)
你说刚才讲的那些 cookie、user-agent 等信息需要一个个自己拼写转换成 Python 代码格式也是挺繁琐,有没有更快的办法呢?答案是有的,有大佬已经制作的转换的网站了,只需 3 秒就可以搞定这些参数。
第 1 秒,copy 请求接口的 cURL。

第 2 秒,将刚才 copy 的 cURL 粘贴到转换网站,语言选择 Python(默认是Python,还支持其他的语言,共支持 14 种语言)。
https://curl.trillworks.com/
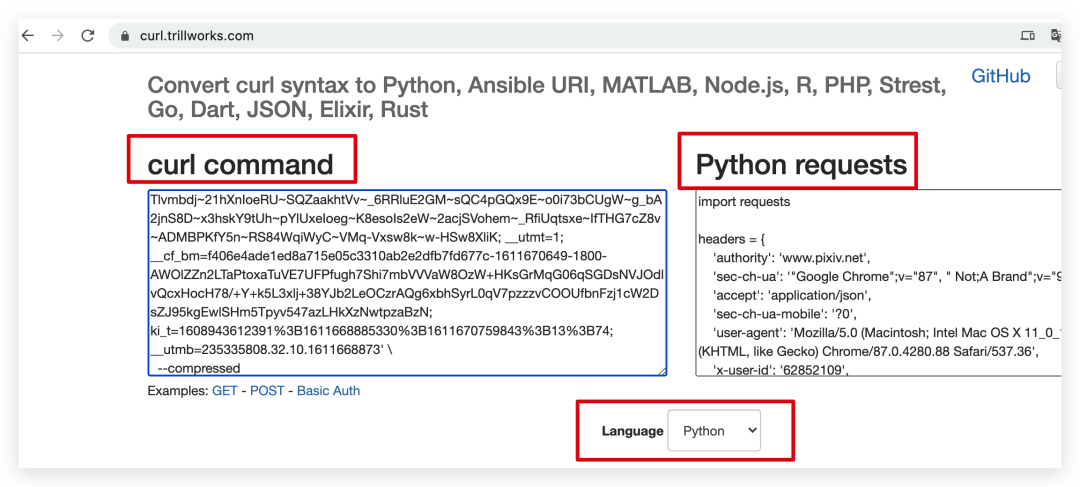
第 3 秒,把转换好的 Python requests 复制到编辑器里,headers 和 params 的详细信息都有了,是不是很快,只用 3 秒!
APP 抓包
上面分享网页抓包的方法,那怎么抓取 APP 的请求数据呢?这个我们需要下载第三方软件去搞定了,我常用的有 Charles 和 Fiddler 软件,这两款工具主要功能差不多的,任选一款就好,也听说过 Fiddler 比 charles 强大那么一点点,但是我更喜欢 Charles,因为它的界面展示的接口有层级目录感,而 Fiddler 所有接口都是并列的。
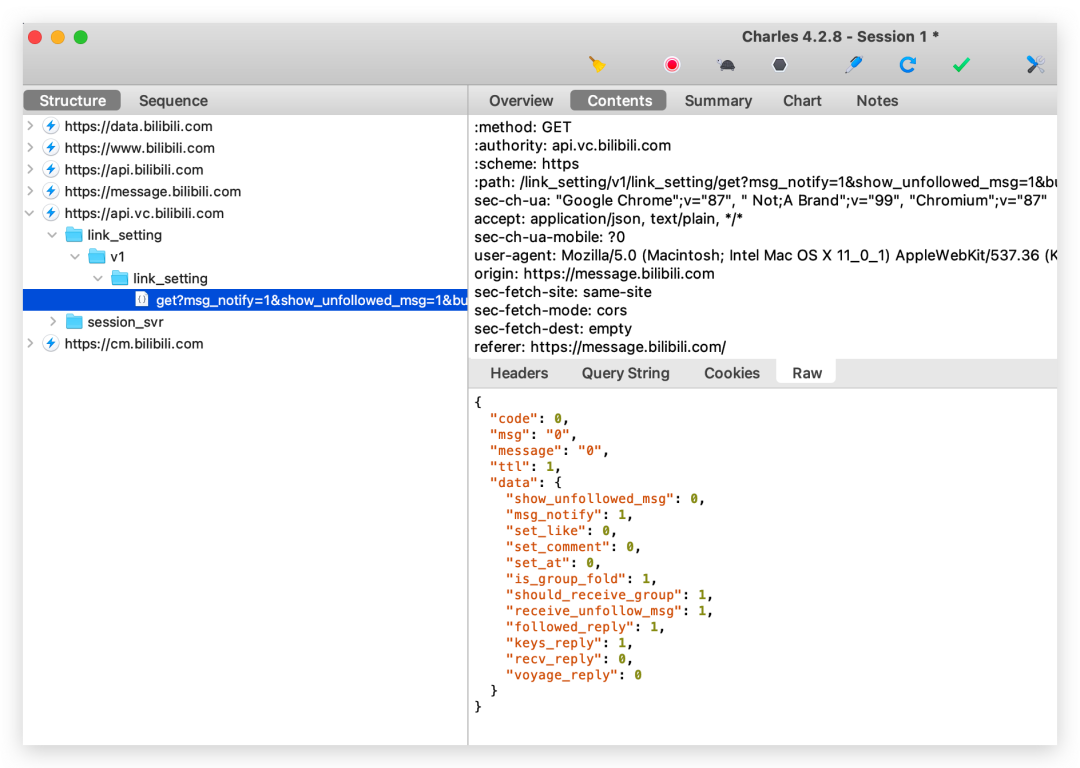
所以接下来我以 Charles 为例,讲讲 Charles 是怎么抓包的。
Charles 基础设置
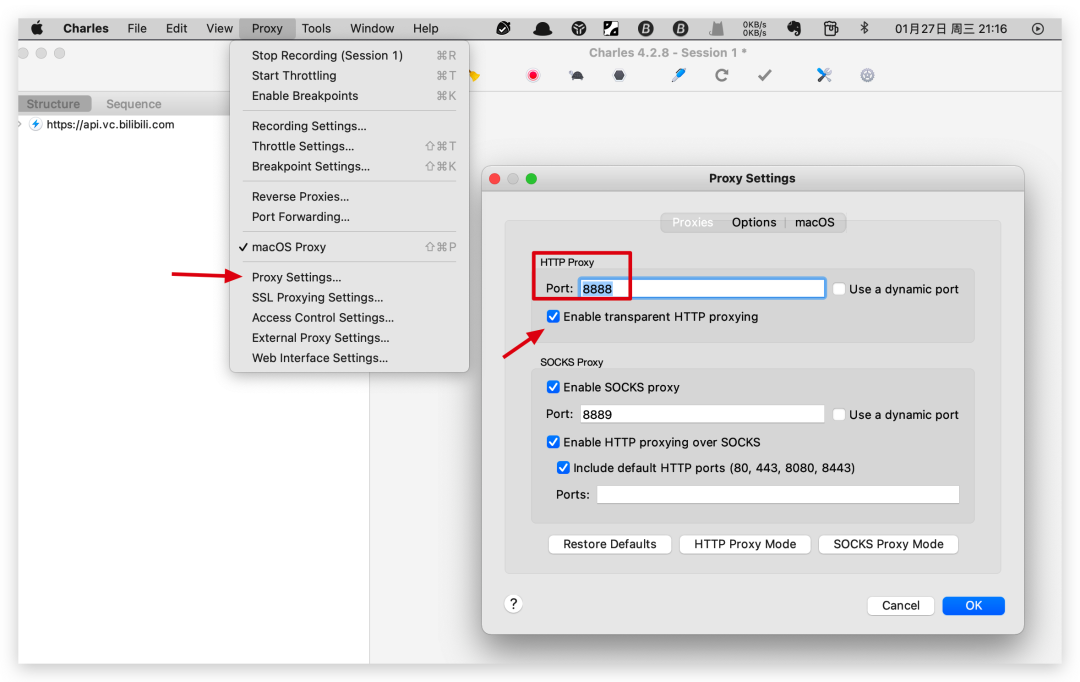
在开始用 Charles 调试抓取网页或者 APP 前,我们需要对 Charles 做一些基础的设置。首先我们得在 Proxy-Proxy Setting 中设置代理端口号,默认为 8888,一般用默认的就行,除非和电脑上其他端口有冲突,然后勾选下面的容许抓取 HTTP 域名的选项。
Charles 抓包网页
Charles 不仅能抓包 APP,电脑网页也是可以抓取的,下面这张图就是我抓取的 bilibili 动画主页的请求。
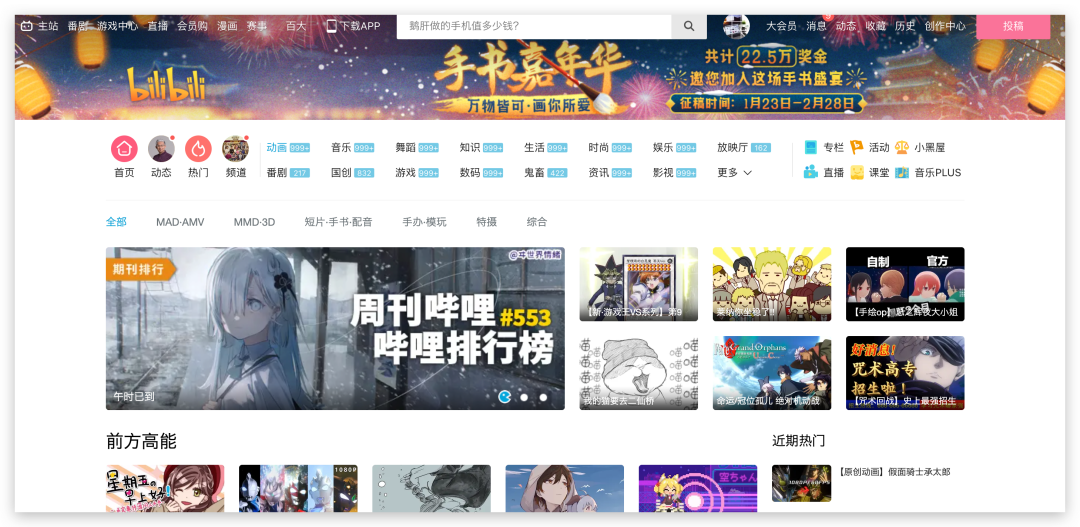
抓取电脑网页前,我们只需要把 Proxy 里的 macOS Proxy 选项(Window系统显示的是 Windows Proxy)勾上就可以捕捉网页端的请求了。

Charles 下面我们可以用筛选功能让它只显示我们需要抓取的域名就行。

Charles 抓包APP
网页能抓,APP 当然也不在话下,但在抓取前需要做下简单的设置。
安装证书到移动设备
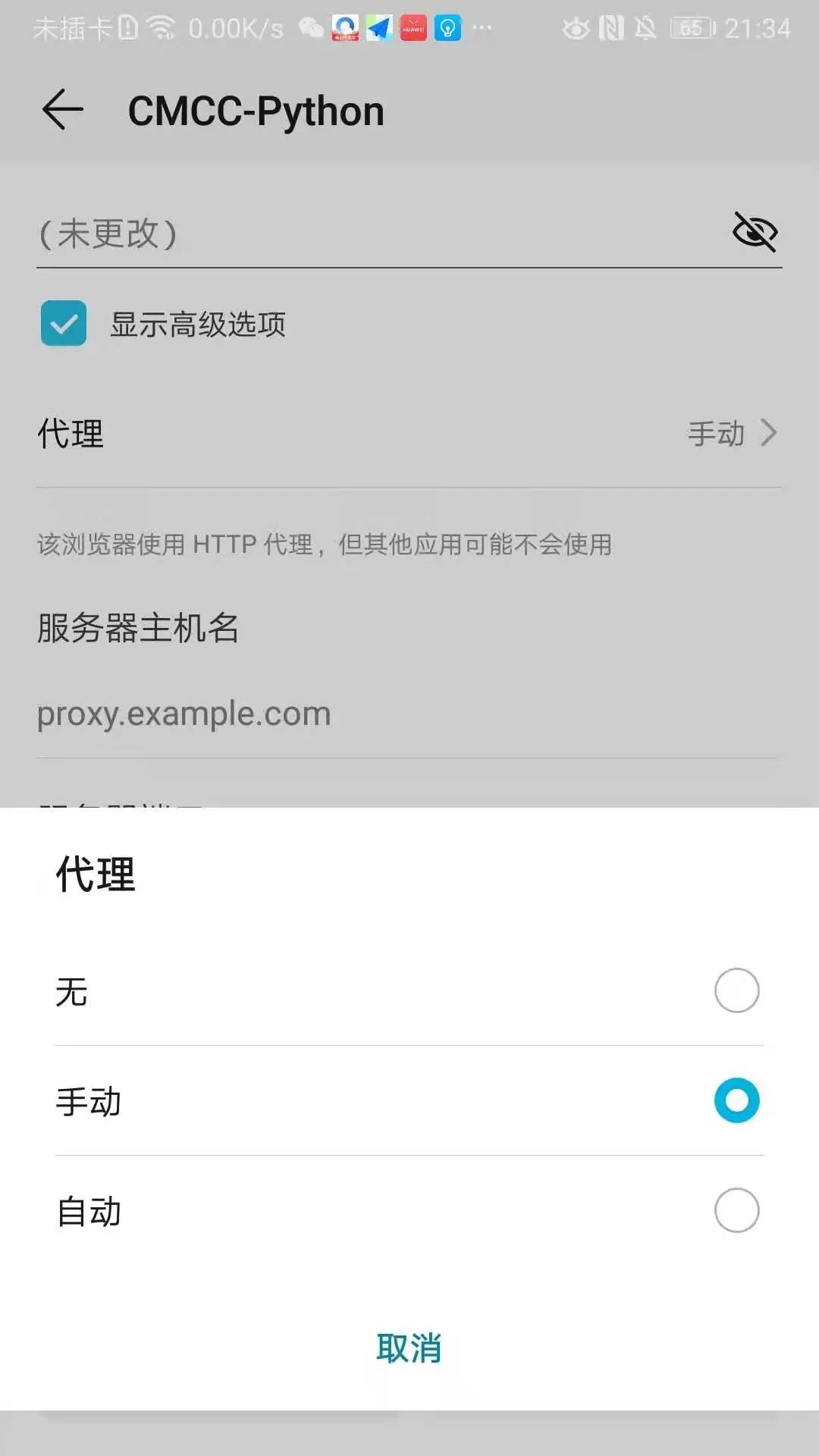
首先,我们让手机和电脑要在同一局域网下,先查看下电脑的 IP,Windows 电脑在 cmd 里输入 ipconfig 命令查看 IP,Mac 电脑在终端输入 ifconfig 查看 IP,手机的无线网里设置代理,填上刚查到的 IP 和端口号 8888。
安卓手机是在长按已连接的 wife,啊呸,wifi,勾上显示高级选项,把代理设置为手动,然后把上面电脑上的 ip 和 Charles 设置的端口号输入到主机名和端口里,点击保存。
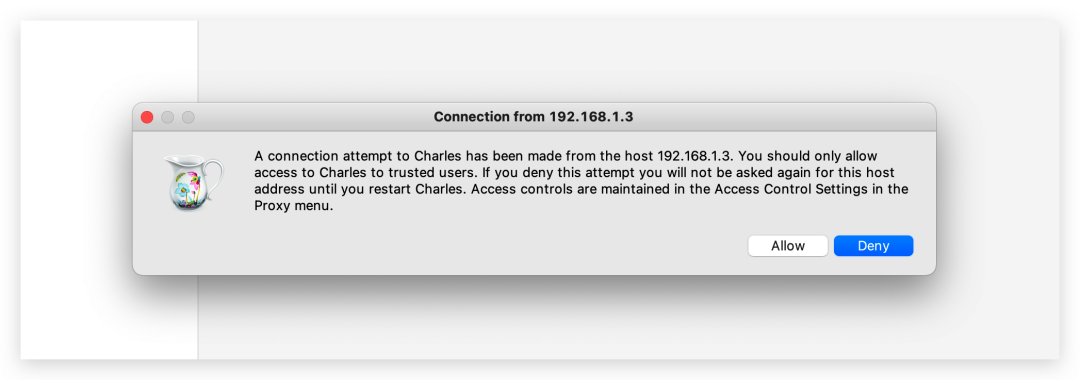
如果手机是第一次和 Charles 连接,Charles 上会有设备接入弹窗提示,选择 Allow 同意即可。
连上之后,我们点击 Help-SSL Proxying-Install Charles Root Certificate on a Mobile Devices or Remote Browser,这时会有个弹窗。
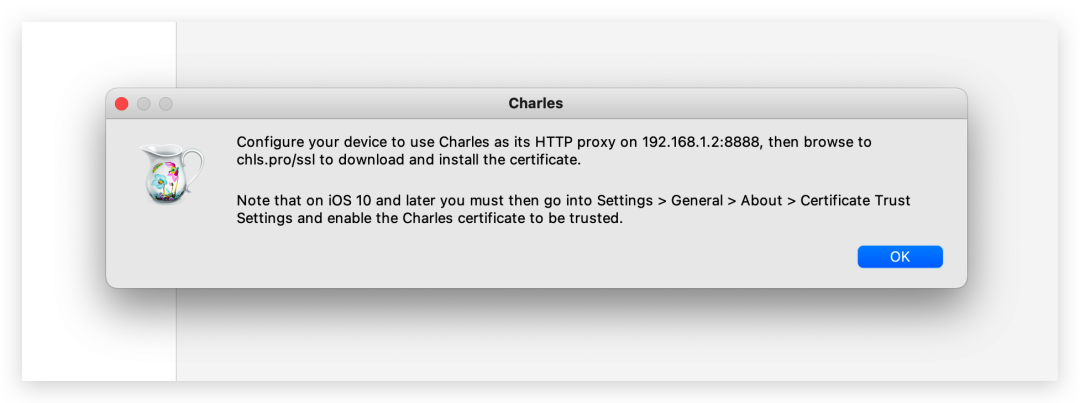
弹窗的意思就是让在安卓设备或 ios 设备或安卓模拟器设置好代理后,然后在浏览器里输入 chls.pro/ssl 网址 去下载安装证书。
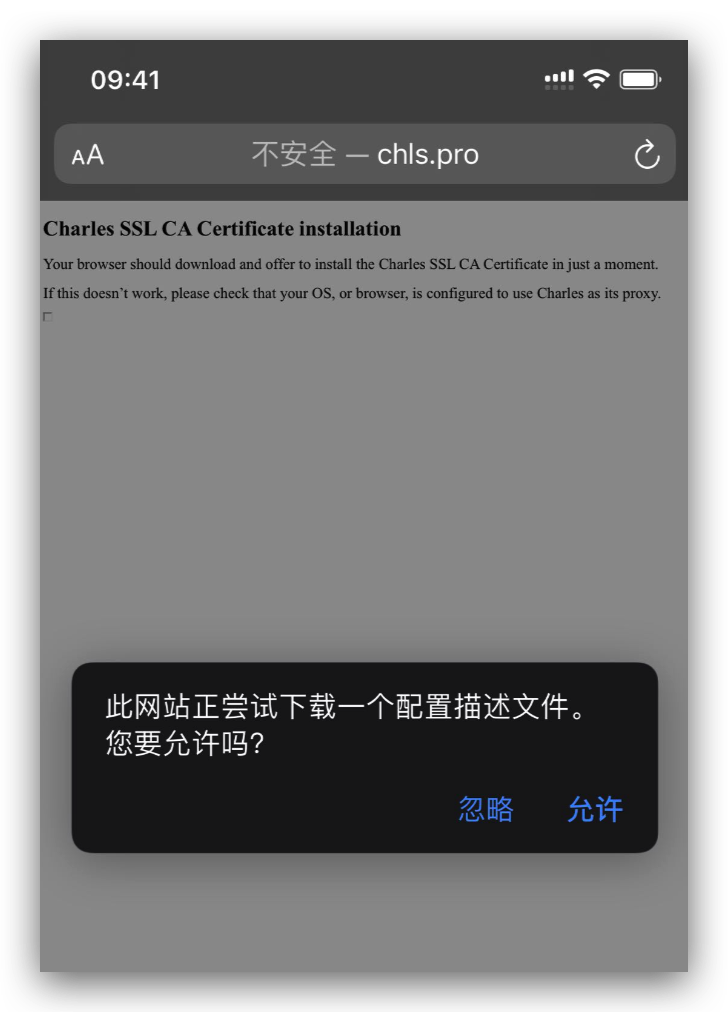
charles 下方还有一段提醒说的是 ios 10 以上的手机安装完证书后,需要在设置-通用-关于本机-证书信任设置,把刚才安装的证书信任下。
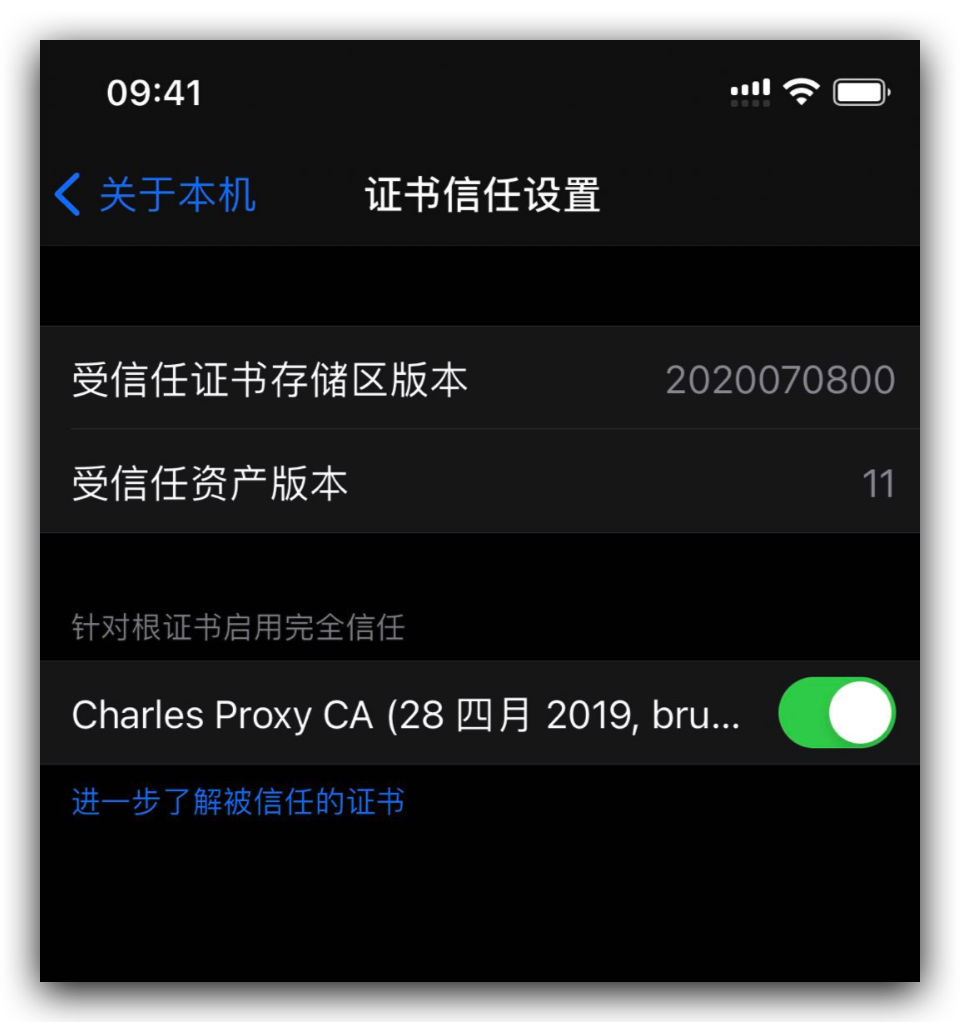
我这操作的是苹果手机,安卓手机没有信任这一步。
证书都安装完成后,操作手机上的 APP,就会抓到大量的数据信息了。
抓取数据显示 unknown 的解决办法
假如你抓取的全部数据出现 unknown 的情况,比如下面我是打开手机的哔哩哔哩APP,抓取的的全是 unknown。
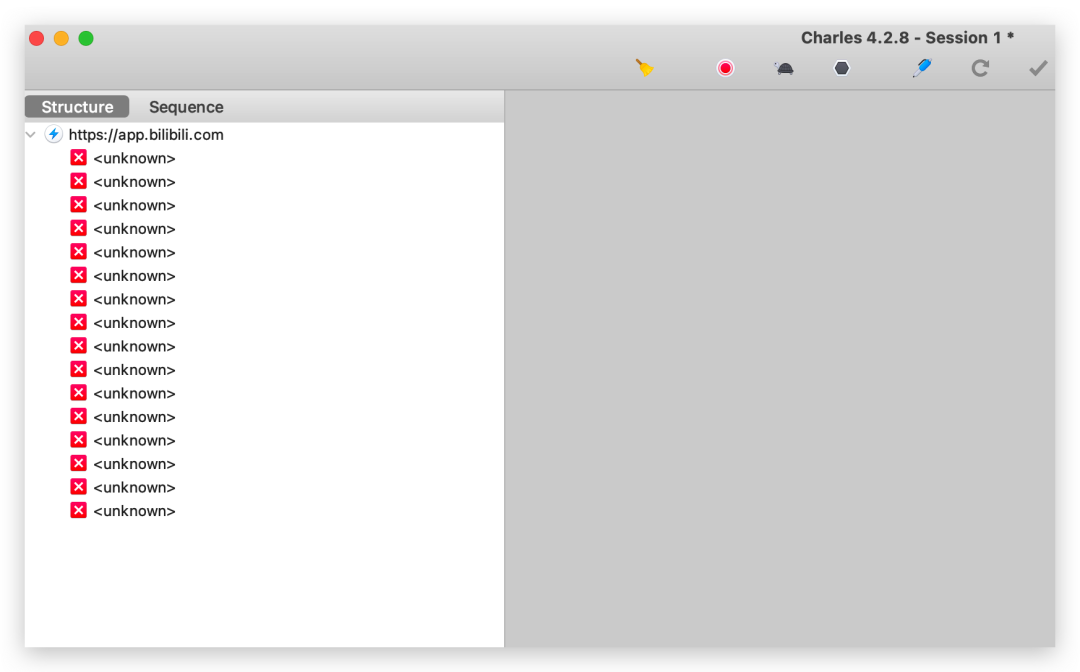
这时我们需要在 Proxy-SSL Proxy Settings ,在 Host 里输入需要抓取的主域名 app.bilibili.com 和端口 443,清空抓取的数据再次打开哔哩哔哩 APP,就能看到抓取的数据了。
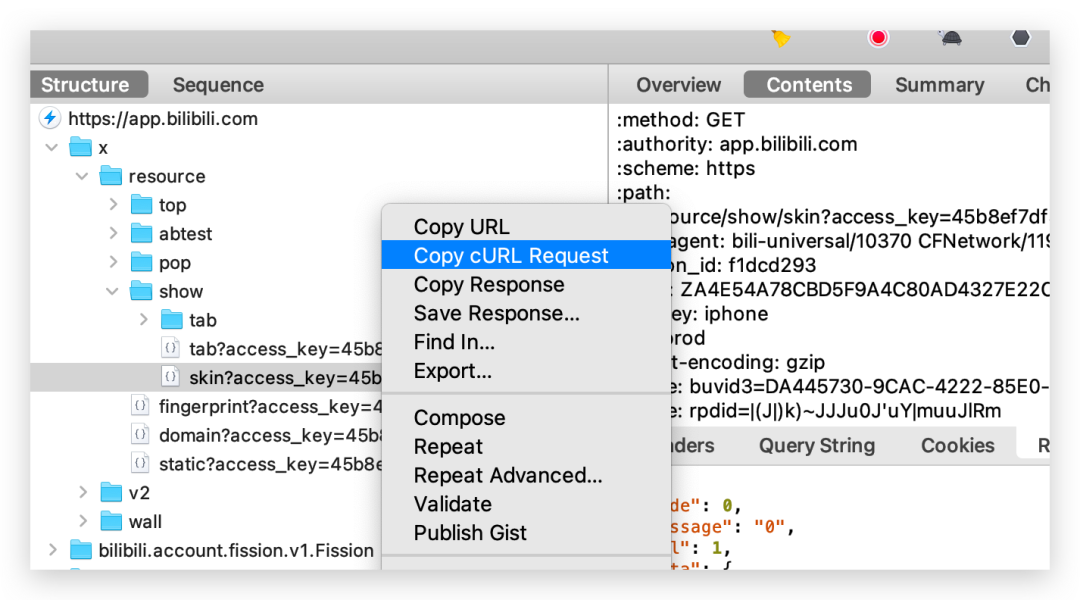
3秒转换成 Python请求
还是上面一样方法,3秒直接转换成我们需要的 Python 请求头。
在接口上右键 copy cURL Request
粘贴到转换网站中
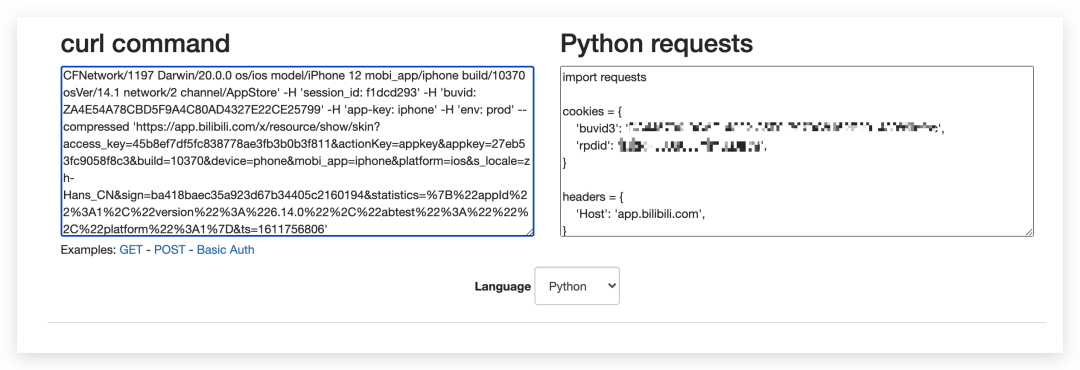
headers 信息和 cookies 信息就轻松转换过来了。
Charles 其他功能
Charles 还有其他的功能,比如模拟网速,这个测试同学可能会经常用到,手机连上 Charles 代理后,在 Proxy-Throttle Settings 中设置不同的网速,可以设置弱网的环境,然后点击 start Throttling 开启,这样就可以测试 APP 在弱网情况下的反应了。
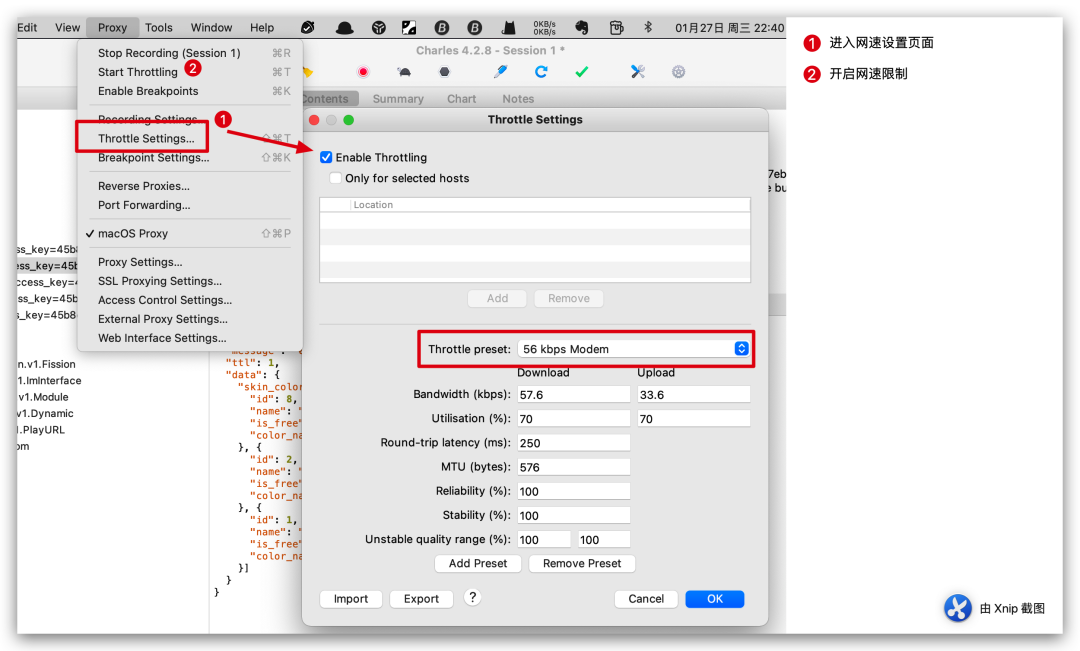
对于测试同学来说,Charles 还有个好用的功能:断点。
什么是断点呢?开发的时候,经常需要对代码进行 debug 断点调试,让程序中断在需要的地方,从而方便其分析。Charles 中的断点功能也是类似的。

这个功能主要是在测试过程中,对于有些极端的数字我们无法模拟的情况下,我们给这个接口的主域名上设置断点,修改该接口的请求或者返回信息也就是假传圣旨后再发给服务器。
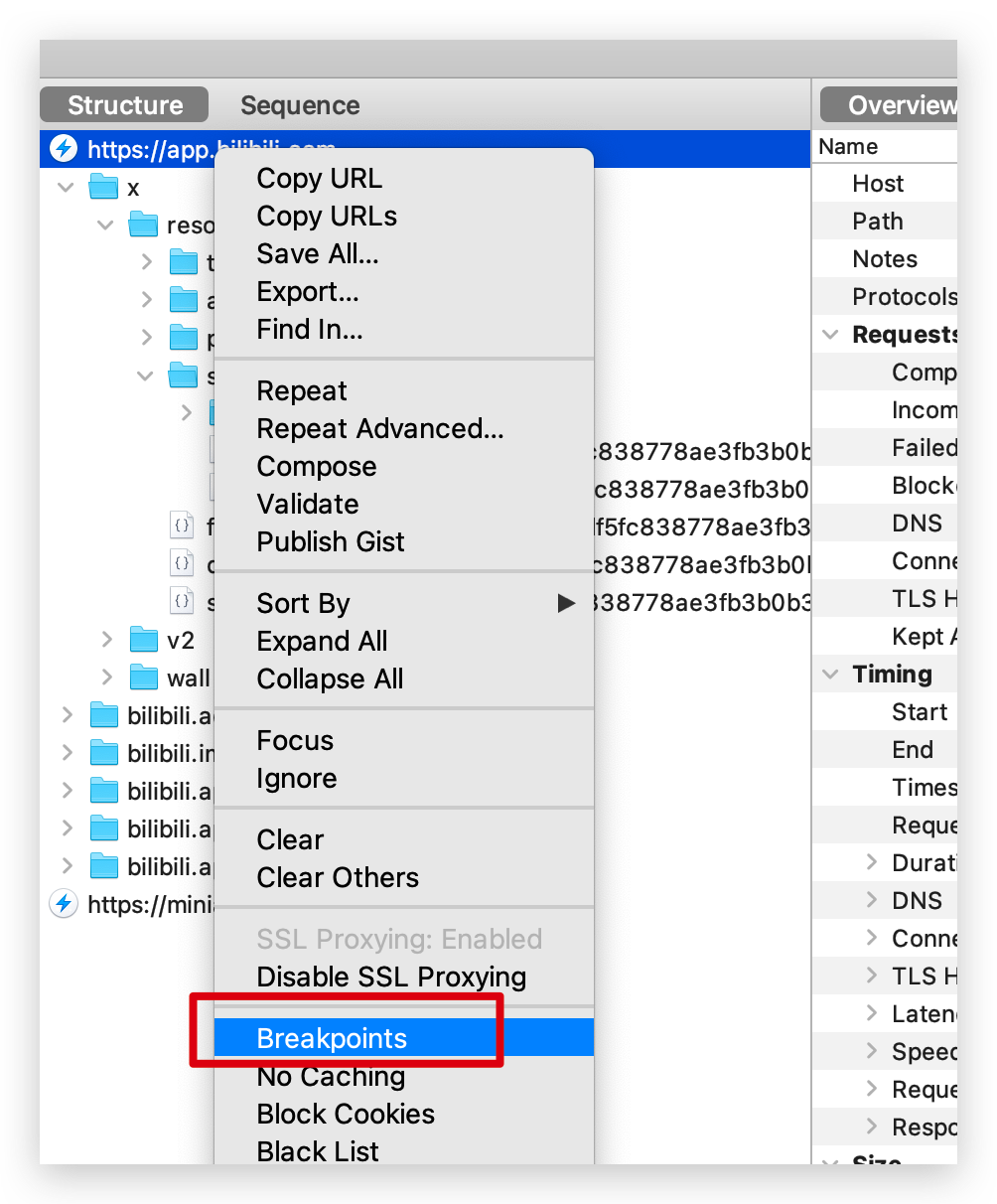
举个例子,比如测试贷款业务,显示贷款金额,比如最大金额是 1 个亿,假如测试中这个数据不好造,但我们需要测试下最大金额时页面显示的情况,是否会被截断或者不显示,这时可以借助断点,改变金额后返回给页面,页面显示的就是你修改之后的数据了。
最后,断点结束后,记得关闭断点,还有,电脑上的 Charles 抓包工具关闭时,记得将手机上的代理关闭,否则手机会上不了网。
以上就是网页抓包调试和 Charles 抓包的主要功能了,这些只是爬虫的前期工作,听了 pk哥今天的分享,大家应该都能 3 秒搞定爬虫前的请求参数了。
好了,以上就是今天的全部分享内容了,求点赞,求在看你,求转发,你也可以评论区留言讨论。
见面礼
扫码加我微信备注「三剑客」送你上图三本Python入门电子书
推荐阅读



