
我们真的需要模型压缩吗?
前言
Appropriately-Parameterized Models
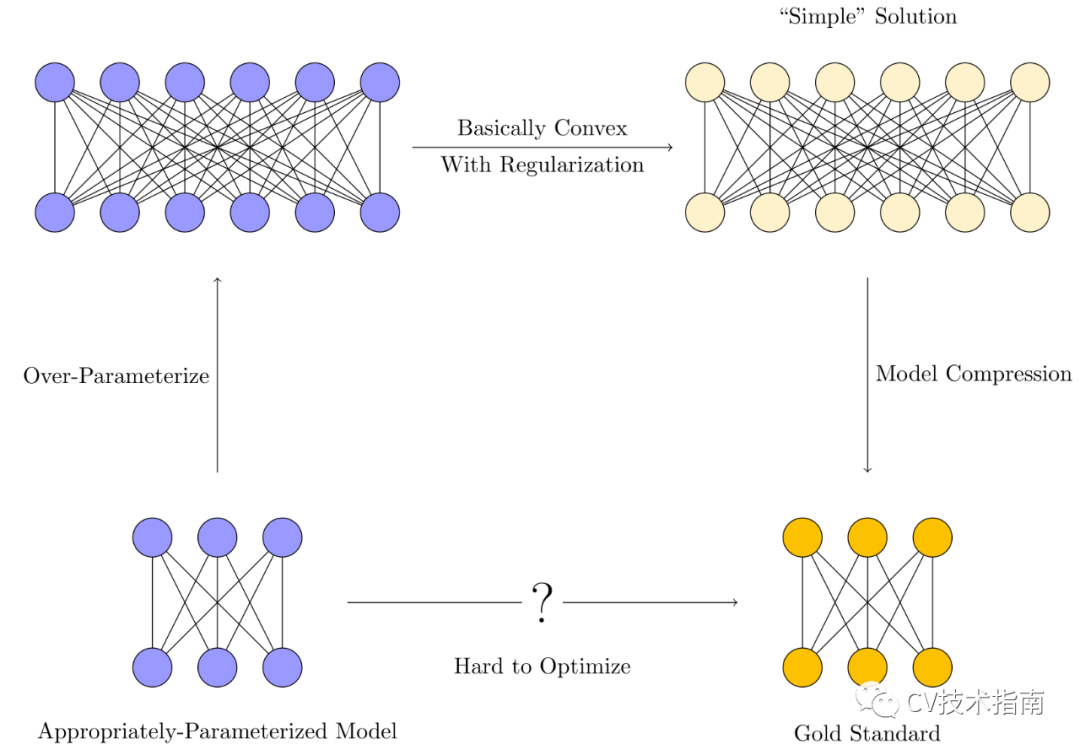
我们会训练一个过参数化的模型。这些模型通常具有比训练样本数量更多的参数。
各种正则化技术(隐式或其他)用于约束优化,以偏向于“简单解决方案”而不是过度拟合。
模型压缩通过消除冗余来提取嵌入在较大模型中的“简单”模型,使内存和时间效率更接近理想的适量参数的模型。
为什么需要过度参数化? 需要多少过参数化?
我们可以通过使用更智能的优化方法来减少过度参数化吗?
Over-parameterization Bounds
Better Optimization Techniques
许多权重接近零(修剪)
权重矩阵低秩(权重分解)
权重只用几位来表示(量化)
层通常会学习类似的功能(权重共享)
Sparse Networks from Scratch
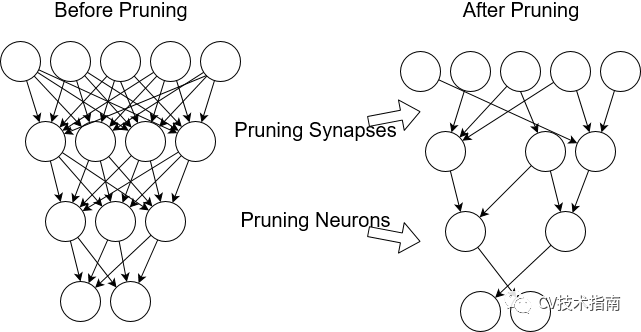
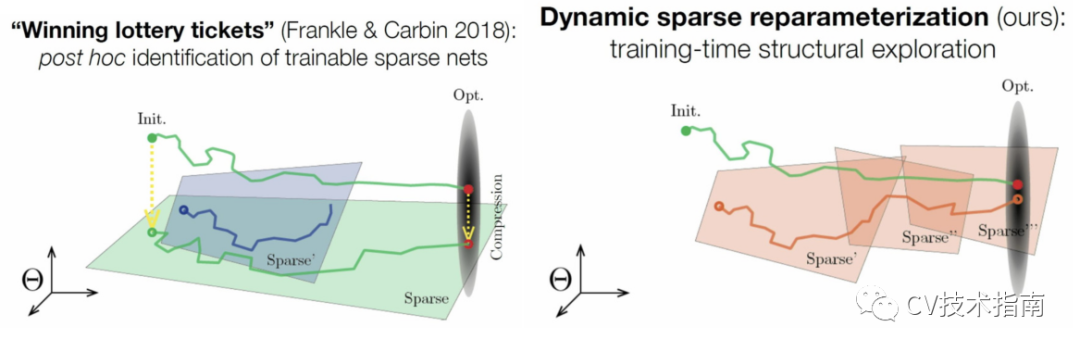
模型压缩方法揭示了训练后的神经网络中的一些常见冗余。
研究了造成这种冗余的归纳偏差/正则化。
从训练开始,就创建了一种巧妙的优化算法来训练没有这种冗余的网络。
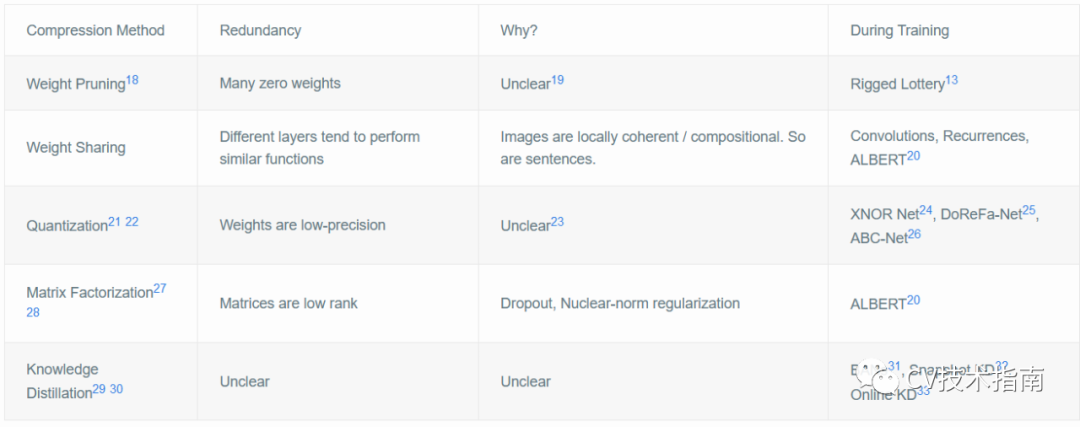
Future Directions
超量参数方面
我们可以通过窥视数据质量(使用低资源计算)来获得更紧密的界限吗?
如果我们使用巧妙的优化技巧(如Rigged Lottery13),超参数化界限会如何变化?
我们可以得到强化学习环境的过度参数化界限吗?
我们可以将这些范围扩展到其他常用的体系结构(RNN,Transformers)吗?
优化方面
我们没有利用的经过训练的神经网络中还有其他冗余吗?
使这些变得可行:
从头开始训练量化的神经网络。
从头开始使用低秩矩阵训练神经网络。
弄清楚为什么知识蒸馏可以改善优化。如果可能的话,使用类似的想法进行优化,同时使用更少的GPU内存。
正则化方面
哪些类型的正则化会导致哪些类型的模型冗余?
修剪和重新训练与L0正则化有何关系?哪些隐式正则化导致可修剪性?
哪些类型的正则化可以量化?
原文链接:
http://mitchgordon.me/machine/learning/2020/01/13/do-we-really-need-model-compression.html#fn:lottery-general
✄------------------------------------------------
双一流高校研究生团队创建
专注于计算机视觉原创并分享相关知识☞
闻道有先后,术业有专攻,如是而已╮(╯_╰)╭